

随着站长素材网ES集群稳定性越来越高、产品体验越来越好。有越来越多的外部客户希望将自建的ES集群迁移到站长素材网上来。本文将介绍一种站长素材网ES在业界独有的业务不停服无感知的迁移方案--在线融合迁移方案。本方案目前已经迁移了上百套客户自建ES集群上云。下面将结合我们在给客户迁移过程中总结出的宝贵经验,来详细介绍下在线融合迁移技术方案的基本原理、核心优势、迁移步骤和注意事项。
要回答这个问题,我们首先来看下当前业界常用的迁移方案,分别是Logstash、Reindex、快照备份与恢复和跨集群复制CCR,如下图1所示。

从上图1中我们可以看出以上四种迁移方案都有一个共同的特点,那就是都需要业务停服,即都属于离线迁移。离线迁移最大的痛点就是迁移期间业务需要停止写入,且迁移流程非常繁琐,工作量巨大。对于一些核心的业务集群,客户几乎不可能接受任何时刻的停服操作。因此对于负责迁移的同学来说就急需一种平滑的、业务无感知的、高可用的迁移技术方案。这便是站长素材网ES在线融合迁移技术方案要解决的问题。
在线融合迁移方案,最体现优势的两个字就是在线,相比于离线迁移,能够真正实现业务不停服、无感知;而最体现原理的两个字就是融合,通过将自建集群和云上集群这两个本身独立的集群融合为一个大集群,并结合ES集群自带的分片分配、迁移特性 来完成数据的迁移工作。融合迁移示意图如下图2所示。
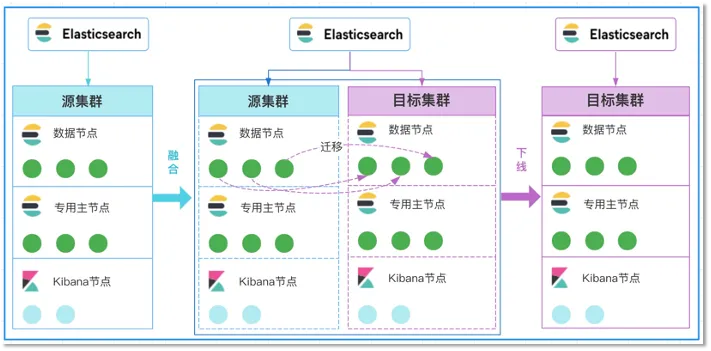
从上图2的迁移流程示意图中可以看出,整个迁移主要分为三步,即融合、迁移和下线。
融合:首先我们需要在站长素材网ES控制台上申请一套和自建ES集群同等规模的空集群,即上图2中的目标集群,然后将云上的集群全量重启后加入到自建的ES集群中,使得两个集群融合成一个大集群。
迁移:融合完成后,通过对ES集群cluster/settings设置exclude属性来进行分片的迁移,当执行了如下API后,ES集群就会自动将自建集群节点上的分片逐步驱逐到云上的节点上来。从而完成分片的搬迁和集群数据的迁移工作。
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.exclude_name": "{source_node_names}"
}
}下线:当自建集群节点上的分片都已经全部迁移完成后,再将自建集群节点全部停机下线,这样便完成了整个集群的迁移上云过程。我们可以通过如下API来查看自建节点上的分片数是否为0。
GET /_cat/allocation?v=true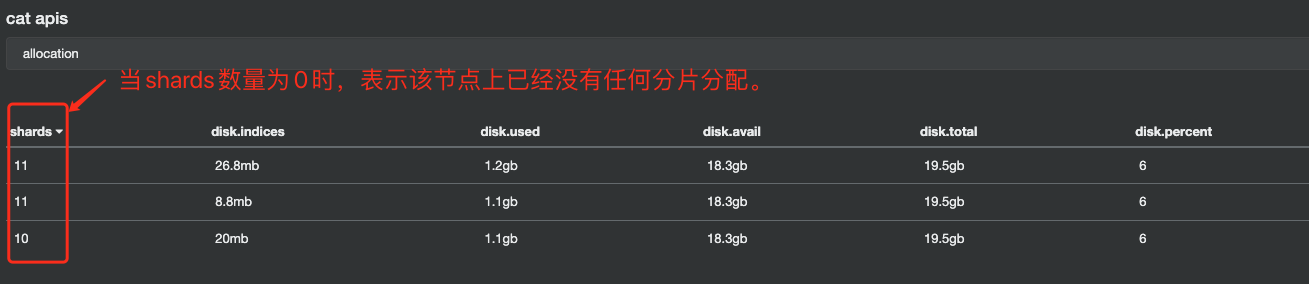
相比于Logstash、快照备份和跨集群复制等离线迁移方案,在线融合迁移真正做到了在线平滑迁移和业务不停服。
在线融合迁移由于是通过全量重启云上ES集群来加入自建集群,因此不会对客户自建集群做任何有侵入性的操作,不同于快照迁移,需要提前安装COS插件并重启集群;也不需要像Logstash迁移,在迁移前后需要对索引doc数量做一致性校验。
在线融合迁移对集群版本的要求是只需要云上集群版本不低于自建集群版本即可。而云上目前提供了从5.6.4、6.4.3、6.8.2、7.101和7.14.2多个版本,相信总有一版本能够满足客户需求。
之所以说能够极大节约人力成本和运维成本,主要原因是离线迁移方案涉及到的方方面面实在太多,比如需要提前跟业务同学沟通可接受停服时间和停服时长,大部分业务低峰期都是在凌晨,因此离线迁移对迁移时间要求比较苛刻;同时离线迁移还需要做数据一致性校验,这些都是非常耗时耗力的工作。而在线融合迁移方案由于能够做到平滑透明、业务不停服,因此整个迁移过程都不需要任何业务方同学参与,也对迁移时间没有严格要求,更不需要做数据一致性校验。这些都能够极大节约人力和运维成本。
虽然在线融合迁移能够彻底解决业务停服的痛点,也能够极大提升迁移效率。但是也并不是所有的自建集群都符合融合迁移的条件的,经过我们大量的测试和实际迁移经验,总结了如下几点限制和需要满足的条件。
如云上ES当前提供的最高版本号是7.14.2,因此如果自建集群版本号大于7.14.2,则无法通过在线融合方案迁移;主要原因是云上低版本的集群节点无法加入高版本的自建集群中。另外对于版本号,最好是两个集群大版本号一致,比如自建版本是6.4.6,则云上优先选择6.8.2,自建版本是7.5.2,云上优先选择7.10.1。
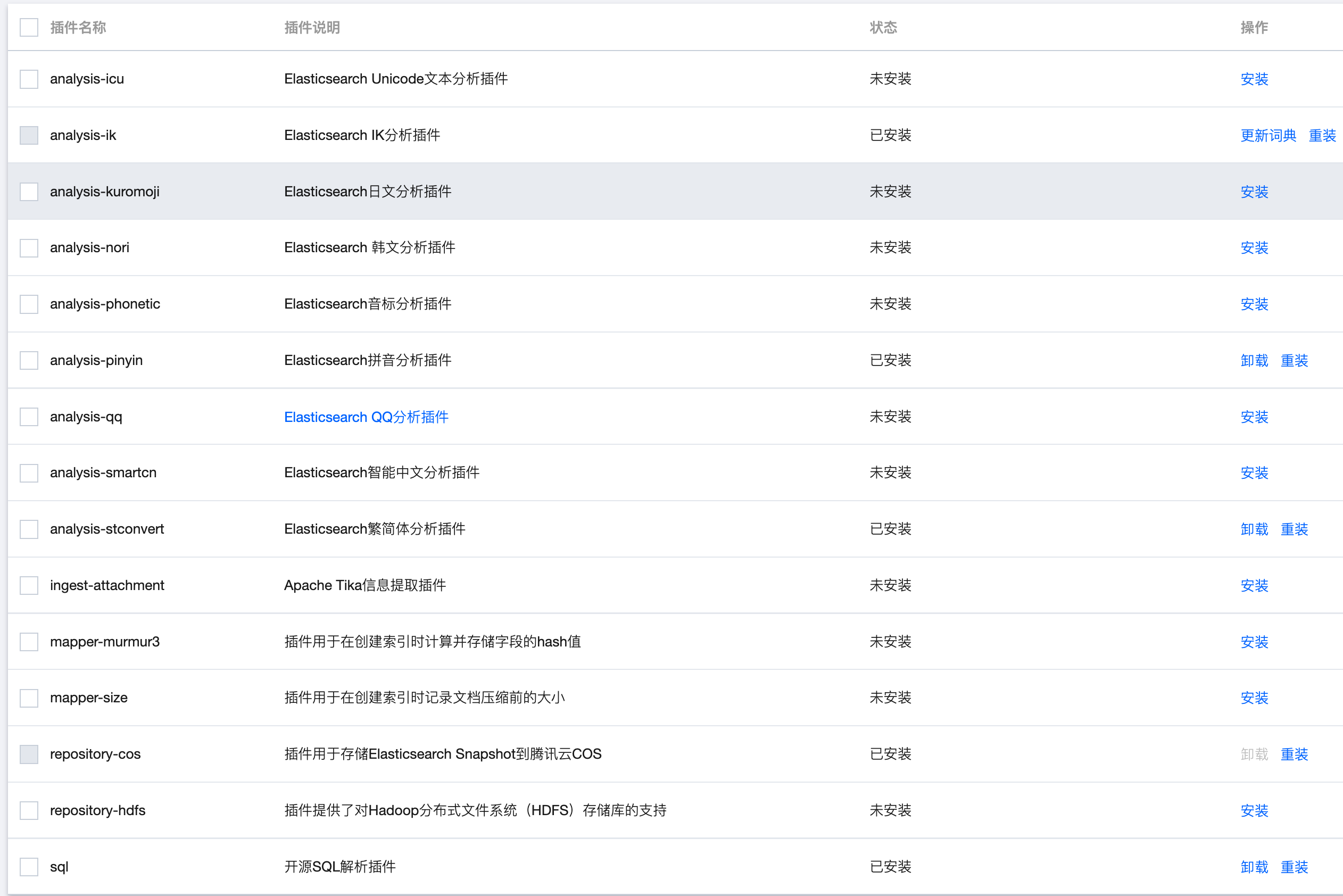
在迁移之前需要先在自建集群节点上之行如下API来查看自建集群上都安装了哪些插件。
curl http://127.0.0.1:9200/_cat/plugins
如果有发现安装了云上不存在的插件则会使得云上ES集群节点融合后,分片分配失败导致集群状态异常问题。下图4是云上ES集群支持安装的插件列表。
这里说的网络互联互通是要求云上的节点能够可以直接访问到自建集群的节点,同样自建集群节点也能够可以直接访问到云上集群节点,中间不可以有任何代理Proxy。中间有Proxy的访问都属于单向网络通信,而不是双向网络通信。下面介绍自建集群两种常见的网络环境和网络通信方案:
1)站长素材网CVM自建ES集群迁移到站长素材网ES
由于站长素材网ES集群采用了跨租户弹性网卡直接打通了ES集群VPC和客户VPC网络环境,因此对于站长素材网CVM自建的ES集群,只需要使用自建集群所在的VPC在云ES控制台购买集群即可实现网络双向互通。如果自建集群和站长素材网ES集群不在同一个地域,则可以采用云上云联网或者对等连接方案进行打通网络;
2)IDC自建ES集群迁移到站长素材网ES
如果客户的自建ES集群是在自己的IDC机房或者是其他云厂商云服务器中,则可以通过专线方式打通两边的网络。两个集群网络打通后可以通过在云上集群节点上至下telnet 自建ip 9300方式进行验证。
通常情况下,客户的自建集群都是开源版本的,如果是基础版且开启了security的话,则需要先将security关闭后才能发起融合。并且白金版集群也不支持融合。如果期望上云后集群使用白金版,则可以在迁移结束后再升级到白金版即可。
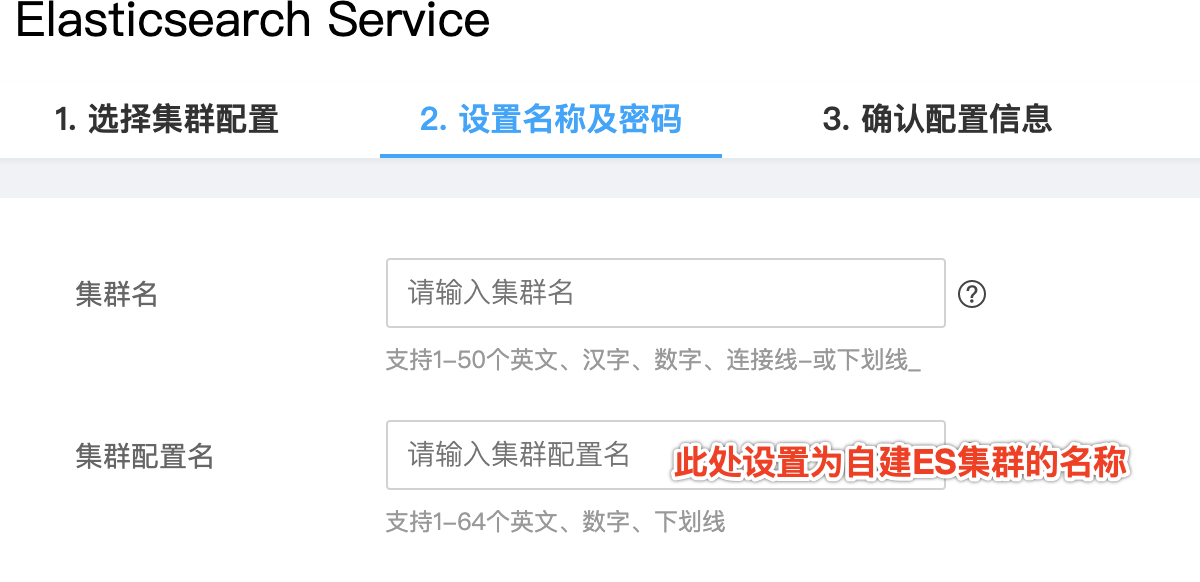
默认情况下,站长素材网ES集群会随机生成一个固定格式固定长度的字符串作为集群的名称,即elasticsearch.yml配置文件中的cluster.name,如cluster.name: "es-cohesszwr"(此集群id配置名为虚构)。
而如果需要和自建集群进行融合,则必须要保证两个集群的cluster.name相同才可以。由于是让云上集群去加入自建集群,因此需要保证云上集群的集群名称与自建集群相同。自定义云上集群配置名需要开通白名单支持,开白后会看到如下图5所示的填写项。如果集群创建出来后没有设置自定义的集群名称,可以找站长素材网ES迁移同学后台处理。
在线融合迁移的过程需要客户的运维同学和站长素材网ES团队的迁移同学密切配合才能完成,由于ES在7版本优化了Master选主逻辑,因此7以下的版本和7以上的版本需要分别采用不同融合策略。下面介绍下不同版本迁移的基本步骤和差异。
7.0以下版本的迁移是指客户自建ES集群版本和站长素材网ES集群版本都是7.0以下的版本,如客户版本是6.4.5,云上版本为6.8.2。
1)分片锁定(客户侧操作)
迁移之前,需先在自建集群上执行如下API,将分片优先锁定在自建集群节点上,这么做的原因是防止两个集群融合后分片自动漂移到云上节点,造成未知风险。
curl -H "Content-Type: application/json" -XPUT _cluster/settings -d '{
"cluster.routing.allocation.include._name" : "自建集群节点名称列表"
}'2)集群融合(站长素材网侧操作)
在这一步站长素材网ES迁移同学会调用后台接口,将自建ES集群节点追加到云上节点中,然后全量重启云上集群。这样在云上集群节点起来后会自动加入到自建集群中。这样就顺利融合成了一个大集群。
curl localhost:5100/cluster/update -d '{
"cluster_name": "es-cohesszwr",
"operator": "wr",
"es_config": {
"discovery.zen.ping.unicast.hosts": "
[\"10.0.0.xx:9300\",\"10.0.0.xx:9300\",\"10.0.0.xx:9300\",
\"10.0.0.xx:9300\", \"10.0.0.xx:9300\",, \"10.0.0.xx:9300\"]"
},
"restart_type": "full_cluster_restart"
}'3)数据迁移(站长素材网侧操作)
集群融合成功后,如果未发现什么异常问题,即可发起正式迁移了,通过执行如下API。
curl -H "Content-Type: application/json" -XPUT _cluster/settings -d '{
"cluster.routing.allocation.include._name" : "云上集群节点名称列表",
"cluster.routing.allocation.exclude._name" : "自建集群节点名称列表"
}'该API的作用就是将自建集群节点上的分片驱逐到云上节点。在融合的中间状态由于分片迁移会消耗一定的性能。因此为了稳定性考虑,可以通过如下API将迁移的并发度和迁移速度调小一点。
PUT _cluster/settings
{ "persistent": {
"cluster.routing.allocation.node_concurrent_recoveries": 2,
"indices.recovery.max_bytes_per_sec": "40mb/s" }
}在迁移的中间状态,业务侧这时候可以将客户端连接ES集群的配置改成站长素材网ES的访问VIP。
4)集群分离(客户侧操作)
检查数据都迁移到云上节点后,客户需要将自建集群节点进行停机下线,将两个融合的集群进行分离。下线自建节点前需要修改自建集群配置名称cluster.name为其他值,如在原集群配置名称后加上-local,以及检查是否有自动拉起ES进程的脚本,如果有也一并删除。另外下线自建节点时,需要逐台下线,且把当选master节点安排在最后一个下线。这么做的好处是可以最大程度减少Master选主的次数。
5)配置恢复(站长素材网侧操作)
站长素材网ES迁移同学确认自建集群和云上集群完全分离后,再次和客户侧业务进行确认是否有异常,如果没有异常,则通过调用如下API将云上配置进行恢复到融合前。
curl localhost:5100/cluster/update -d '{
"cluster_name": "es-cohesszwr",
"operator": "wr",
"es_config": { "discovery.zen.ping.unicast.hosts": "null"},
"restart_type": "no_restart"
}' 注意,这里的discovery.seed_hosts设置为null,是因为后台接口会自动下发初始节点ip到配置中,另外restart_type务必设置为no_restart,不重启方式更新。否则会影响业务稳定性。
7.0以上版本的迁移是指客户自建ES集群版本和站长素材网ES集群版本都是7.0以上的版本或者云上集群是7.0以上版本,如客户版本是6.8.3,云上版本为7.5.1或者自建版本为7.5.2,云上版本为7.10.1。
1)分片锁定(客户侧操作)
这一步和7.0以下版本操作是一样的,具体操作详情可参考上面步骤。
2)集群融合(站长素材网侧操作)
这一步和7以下版本最大的区别就是将自建集群节点列表追加都云上并全量重启云上集群后,云上集群并不能直接加入自建集群,这主要是和7以上版本选主算法有关。因此为了让云上集群全量重启后能够正常融合,需要在全量重启后逐步对云上集群节点执行如下命令用于抹除云上集群的元数据。详细原理可参考官方文档提供的elasticsearch-node命令。
首先先执行追加自建节点ip配置API:
curl localhost:5100/cluster/update -d '{
"cluster_name": "es-cohesszwr",
"operator": "wr",
"es_config": {
"discovery.seed_hosts": "
[\"10.0.0.xx:9300\",\"10.0.0.xx:9300\",\"10.0.0.xx:9300\",
\"10.0.0.xx:9300\", \"10.0.0.xx:9300\",, \"10.0.0.xx:9300\"]"
},
"restart_type": "full_cluster_restart"
}'注意:上面的API中es_config字段的key是discovery.seed_hosts,而不再是discovery.zen.ping.unicast.hosts。
随后再通过脚本批量对云上集群每个节点执行如下命令来抹除集群元数据,随后便可以看到云上集群节点就可以成功加入自建集群中了。
ps -ef | grep java | grep c_log | awk '{print $2}' |xargs kill -9
cd /data1/containers/*/es/
./bin/elasticsearch-node detach-cluster (选择y)3)数据迁移(站长素材网侧操作)
这一步和7.0以下版本操作是一样的,主要目的是让分片从自建集群节点上逐步平滑迁移到云上节点上来,具体操作详情可参考上面步骤。
4)集群分离(客户侧操作)
这一步和7.0以下版本操作是一样的,具体操作详情可参考上面步骤。
5)配置恢复(站长素材网侧操作)
配置恢复的操作也基本和7.0以下版本一样,唯一的区别同样在与es_config参数中的key,这里应该是discovery.seed_hosts。同样采用no_restart不重启方式进行更新。
curl localhost:5100/cluster/update -d '{
"cluster_name": "es-cohesszwr",
"operator": "wr",
"es_config": { "discovery.seed_hosts": "null"},
"restart_type": "no_restart"
}'这里我们对7以上版本做过一系列测试,当集群处于融合状态后,然后一次性同时下线所有的自建集群节点后,云上集群会立即处于失主状态,导致集群不可用,业务出现大量报错。这主要是由于集群检测到一半节点(具有node.master角色)同时脱离集群后,已经不满足选出Master节点的基本条件,从而导致集群长期处于失主状态。
因此为了避免在集群分离时集群不可用风险,切勿同时下线自建节点, 而是需要逐台进行下线,并且把自建节点上当选的Master节点放在最后一个下线。否则会导致多次切主,且有可能多切到自建节点上。
在线融合迁移方案需要在集群融合后将所有的自建集群索引迁移到云上,强烈不建议只迁移部分索引,或者分批次迁移,如第一次融合后迁移部分业务索引,然后分离集群,过段时间再进行二次融合,再把剩余索引迁移过来。
结合我们的测试情况来看,当数据迁移完成两个集群分离后,自建的ES集群会出现Red情况,主要是由于索引都迁移到了云上,而自建集群上只有索引的元信息,因此会出现索引无法分配的情况,这也是集群分离后自建集群Red的原因。
通常这种情况下客户会选择删除这些索引以让集群恢复Green。如果这时候再次将两个集群融合来迁移剩余索引的话,由于是通过全量重启云上集群节点来加入自建集群,因此融合后会以自建集群上当选Master上的集群元数据为准。因此一旦融合成功,就会把自建集群的元数据同步给云上集群节点,这时候就会直接删除云上第一次融合迁移过去的索引,从而导致之前迁移的索引数据全部丢失。这个风险的根本原因就是我们第一次分离后将自建集群上Red的索引删除了,而这些删除的索引都会记录在自建集群的元数据里,在一个叫索引坟墓的地方。融合后会同步这些元数据给云上集群。详情可参考官方文档Index tombstones。
虽然我们强烈不建议甚至禁止同一个集群二次融合,但是如果实在需要二次融合来解决业务不同阶段迁移的问题,可以通过如下解决方案来避免二次融合的数据丢失问题。
二次融合避免数据丢失解决方案:迁移索引Reopen方案
第一步 第一次融合,在集群分离后,对于自建集群上Red的索引,不要进行删除,而是对这些索引执行close操作,即关闭索引。
POST {index_name}/_close
第二步 第二次融合,融合成功后,再将之前关闭的索引执行open操作,即打开索引。
POST {index_name}/_open
经过我们多次测试,迁移索引Reopen方案能够解决二次融合场景下数据丢失的问题。
客户端开启嗅探Sniff功能是为了能够让Client端自动发现集群侧ES节点的动态变更。为云上ES是通过PrivateLink打通的客户侧VPC和云上集群VPC网络,如果融合后客户端将访问配置切换到云上后,同时保持开启了嗅探功能,就会出现嗅探到的节点ip访问不同的情况,从而导致Client端大量的超时请求,影响业务使用。客户端报错信息可能如下:
NoNodeAvailableException[None of the configured nodes are available: [{#transport#-1}{VTss4h8SRsCpP6EW5PoLxxxrQ}{192.168.106.xxx}{192.168.106.xxx:9300}] ]at org.elasticsearch.client.transport.TransportClientNodesService.ensureNodesAreAvailable(TransportClientNodesService.java:347) at org.elasticsearch.client.transport.TransportClientNodesService.execute(TransportClientNodesService.java:245) at org.elasticsearch.client.transport.TransportProxyClient.execute(TransportProxyClient.java:59) ......因此为了保障融合迁移方案对业务的透明和平滑,需要在融合前检查客户端是否开启了Sniff嗅探,如果开启需关闭此功能。不同语言客户端接入云上ES集群方式可以参考站长素材网ES官方文档Elasticsearch Service 通过客户端访问集群-快速入门-文档中心-站长素材网。
本文首先从讨论现有各种离线迁移方案的痛点和客户对核心集群不接受停服的强烈需求,回答了为什么需要在线融合迁移技术方案;接着详细介绍了在线融合迁移方案的基本流程原理、核心优势、迁移限制条件以及不同ES版本迁移详细步骤和差异;最后结合我们多次的测试验证以及结合给客户迁移过程中积累的宝贵经验,分享了三点迁移过程中非常容易猜到的坑和注意事项,以及遇到该类问题对应的解决方案。目前我们站长素材网ES团队采用在线融合迁移方案已经成功迁移了上百套客户自建ES集群,每一次平滑迁移都保障了客户业务的系统稳定性和集群数据的安全性。希望本文的分享能够帮助到更多有需要的客户。站长素材网ES,永远值得您的信赖。
