

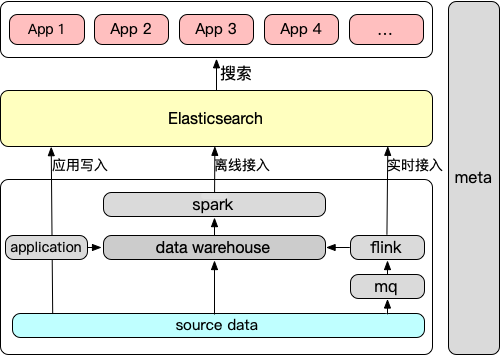
Elasticsearch(简称ES)是当前使用最多、规模最大的检索系统。ES是一个分布式,高实时的搜索引擎,覆盖许多实时检索场景和更低的响应时效,为所有类型的数据提供近乎实时的搜索和分析。ES的检索能力广泛应用于各种搜索场景中。下图是检索平台数据流程:
由于日益增长的集群规模和当前架构的制约,存储成本和检索效率上存在着诸多挑战。
一份数据在ES的存储通常是Hive的2~4倍(单副本对比),存储膨胀系数非常大;且ES的底层存储基本使用SSD磁盘,存储成本相当昂贵。
大量数据的展示拉取,导致ES集群的cpu、磁盘IO、网络IO等负载迅速上升,进而影响整体的检索效率变慢。
由于ES使用SSD存储介质,在海量数据的场景中存储成本十分高昂。本章节对ES的存储和数据进行分析,寻求优化的突破口。
Hive的存储基本就是数据压缩后的文件,Hive压缩格式主要有bzip2、gzip、deflate、snappy、lzo等,数据实际存储大小由压缩程度决定。
而ES的存储结构比Hive要复杂得多,因为各种检索能力的实现,需要构建不同类型的索引信息存储,ES底层存储是lucene实现的。lucene存储的数据文件包含10多类,其中存储占比最大的文件后缀类型如图:
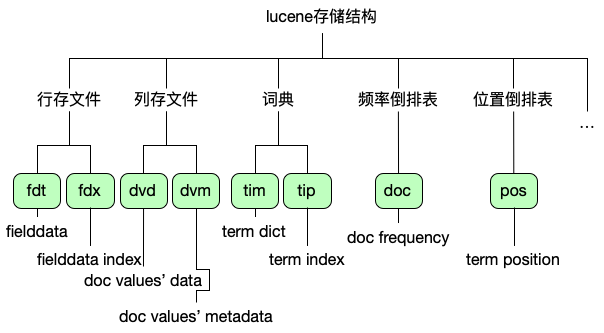
存储了_index、_score、_id、_source以及store为true的字段信息,主要用于字段数据的拉取展示,有lz4和deflate两种压缩算法,目前我们均使用deflate压缩,字段无开启store行存。存储大小由原始数据大小和字段数、名称大小决定。
列存文件存储用于聚合排序操作,分词类型的字段不能存储在列存文件中,其他类型的字段默认开启列存(doc_value=true),列存文件不压缩存储,列存文件决定字段是否可用于聚合排序,应用场景变化快,优化难度大。索引字段默认均开启列存(text类型不可开启),存储大小由不分词类型索引的字段数据情况决定。当前ES集群为6.8,不支持压缩,无优化空间。
词典、位置倒排表,顾名思义,由索引的字段数、term数、数据大小等决定,此类存储也无法直接优化。
经过对图中各类文件的存储分析,得到行存文件是我的优化方向。
通过/_stats?pretty&include_segment_file_sizes=true可以对ES数据进行统计分析:行存文件(fdt)通常占比在40%~80%,单副本存储大小是Hive对应数据的1.5倍~2.5倍不等;再加上列存、倒排表等存储数据,ES总存储大小大约是Hive的2~4倍。
lucene行存文件存储相比Hive的文件存储仍然较大,经过抽样统计,发现基本只有10%的字段是用于检索,因此倒排表、列存文件的存储影响不会太大。
而表字段命名分析发现,平均字段名长度达到了10~20,因此100个字段名就有1、2000个字符。数据中存在大量数值型字段,统计一份数据的情况,发现10万行字段名的大小甚至比抽样10万条数据多几百M。
由于ES行存文件数据中,_source字段是以json结构进行一整个文档的全部字段名(key)和原始数据(value)存储,当字段数过多、文档数海量的时候,会导致冗余存储大量的字段名(key)。数据的字段数越多,字段名字符数越多。在海量的ES数据量情况下,冗余存储的字段名数据就会越大。根据不同的data、schema特点,字段名的存储能占行存文件的10%~40%不等,这是存储的冗余浪费。
此外随着数据的复杂度提升,存储的字段愈来越多,如果非检索字段全部存储为独立字段,也存在触及ES的字段数限制的风险(1000个),因此需要一个更好的方案来解决这些非检索字段的存储。
分析发现数值型字段占比越高,字段名的冗余存储越严重,可以针对数值型字段的字段名进行优化。
设计一个统一数值存储字段,将非检索类型中,数值类型的字段统一存储到这个统一存储字段中,避免了原始数据中的json字典key过多和key值冗余存储过大,可以有效优化ES存储;同时也大大缩减了索引mapping规模,避免索引字段数过多的问题。

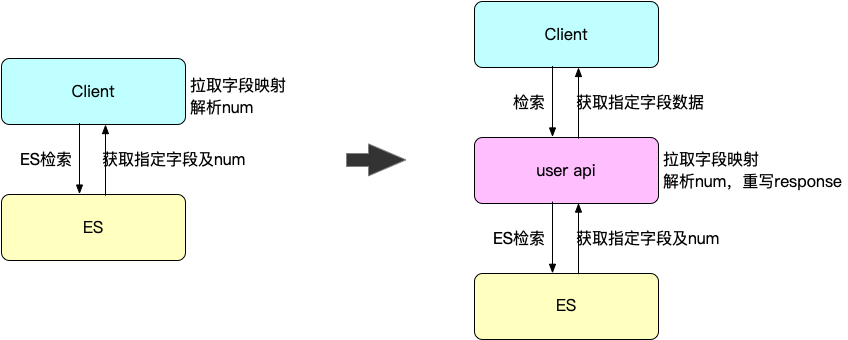
由于存储结构的改变,读写时均需要根据字段的数据配置映射具体的存储顺序,因此我们根据一个固定的字段序号映射具体的字段所在位置。
查询时,因为拉取的数值字段都在num中,用户解析数据的成本会提高。我们通过封装一层user api的方式屏蔽这些复杂逻辑的处理,让用户侧可以维持原有的查询方式。
a) 对数值型字段数占比70%的数据进行测试,改造为统一存储字段后,行存文件大小减少了20%多,index整体占用存储减少了15%;
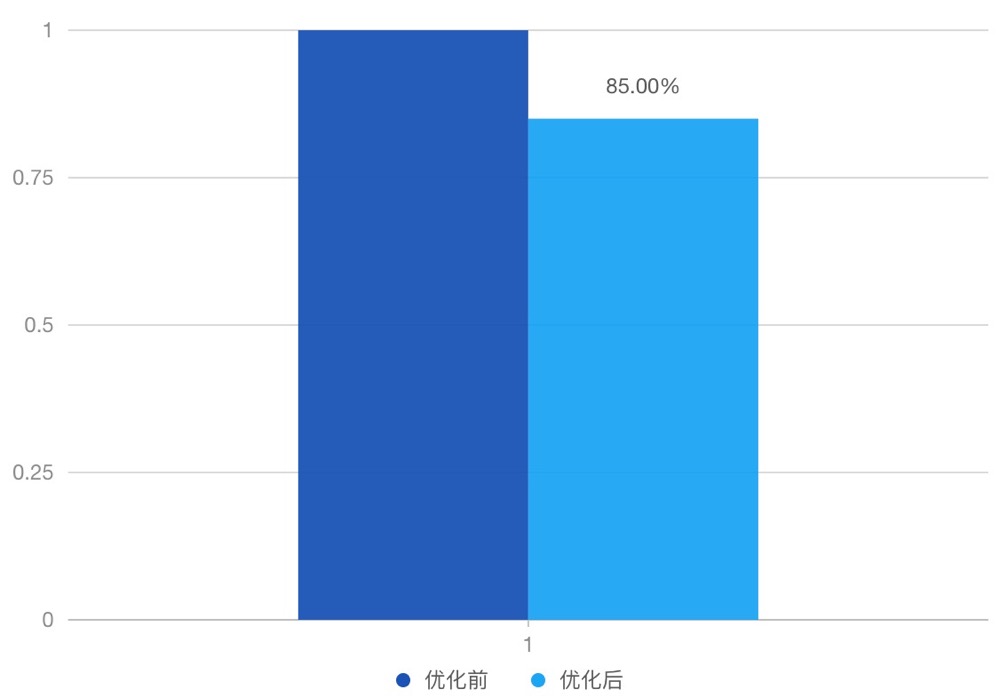
b) 行存文件的存储优化也对字段展示需要解压的数据进行降量,提高了展示数据拉取的效率。
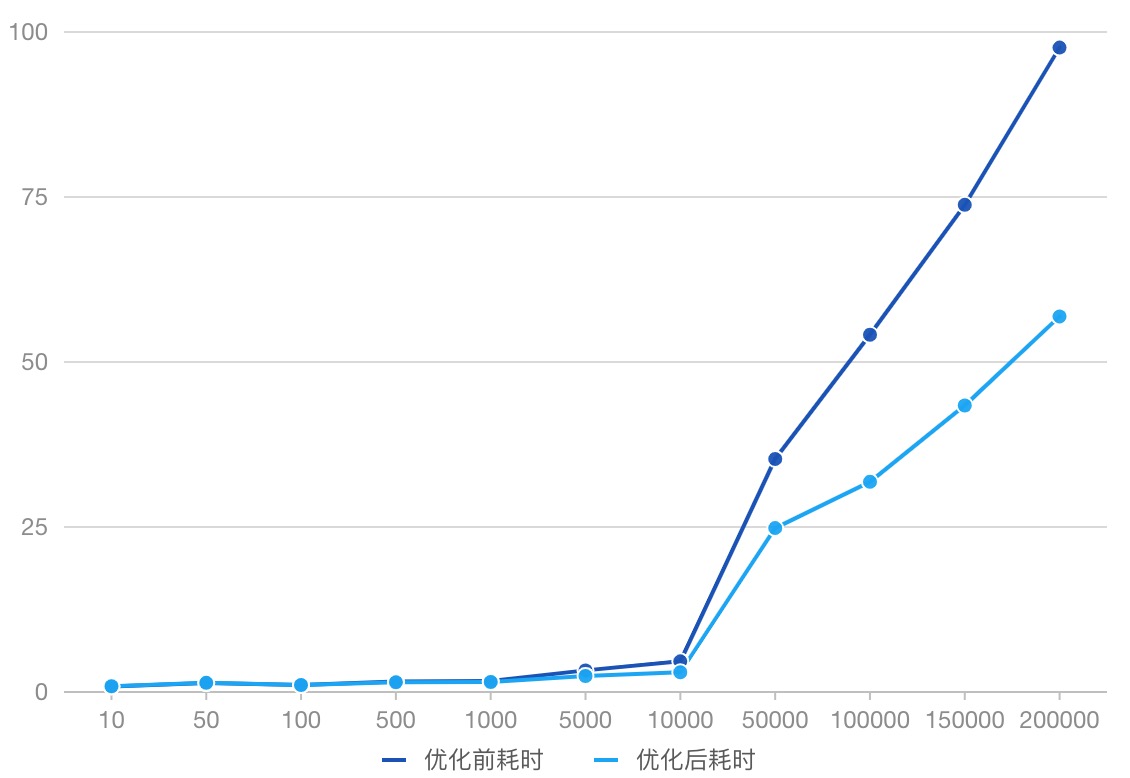
数据查询效率对比,优化了20%~40%:
针对普遍字段名都过长的情况,还可以通过字段名序号映射,直接将field name转化为数字,通过映射表进行字段含义关联,也可以实现等价的效果,在压缩上会存在细微的差异,具体方案可根据实际数据特性进行抉择。
以上提到了,数据中有相当高比例的字段是数值型字段,但其余字段仍需独立存储,其中包含大量长文本、多媒体数据,单个文档数据量依旧很大。此类数据通过上述方法优化效果不大,ES的集群规模仍非常庞大。实际用于检索的数据仅占总存储的50%~70%,原始数据存储占了30%~50%。此外ES集群均使用SSD磁盘,存储成本是HDD的6倍,存储成本非常高昂。
在数据检索中,经常需要拉取大量明细数据。ES频繁读取行存文件,解压提取_source字段数据等。数据的抽取耗费了大量磁盘io、cpu资源,当查询量命中量上升时,会引起ES集群磁盘io、cpu负载过高,甚至占满部分节点的网络带宽,导致请求耗时大大增加乃至超时雪崩、集群宕机不可用。
ES集群规模节点数不宜过多,会导致元数据过多导致集群不稳定。在海量的非检索数据的存储中,单集群规模变得非常庞大,集群健康度会下降,甚至一个集群根本无法容纳如此海量的数据。
我们可以通过列存储结构来减小行存文件的读取和解压,以及对_source的json解析等代价。虽然ES也有列存储文件,但是它的应用场景是聚合索引,6.x以下ES版本不支持压缩,并且对text类型索引字段无法支持列存。针对频繁的大批量数据拉取场景,可以考虑使用nosql数据库来实现海量数据集的实时读写,代表产品有列存数据库、kv数据库、对象存储等。本文主要介绍列存数据库结合ES构建二级索引的优化。
普通的行式数据库一般压缩率在 3:1 到 5:1 ,而列式数据库的压缩率一般在 8:1 到 30:1 左右,因此nosql数据库拥有高效的储存空间利用率,以更低的存储支撑相同量级的文档数据。尤其在ES的存储磁盘是SSD硬盘,替换为列存数据库后通常使用HDD硬盘,成本更低。
读取多条数据的同一列效率高,因为这些列都是存储在一起的,一次磁盘操作可以数据的指定列全部读取到内存中,同时支持写密集型应用
基于以上分析,我们使用列存数据库存储原始数据,基于ES构建二级索引表,充分利用ES实时全文检索的能力,通过倒排表快速检索命中的文档id,并通过文档id作为key在列存数据库进行高效查询和大数据拉取。
下图以HBase为例构建ES二级索引
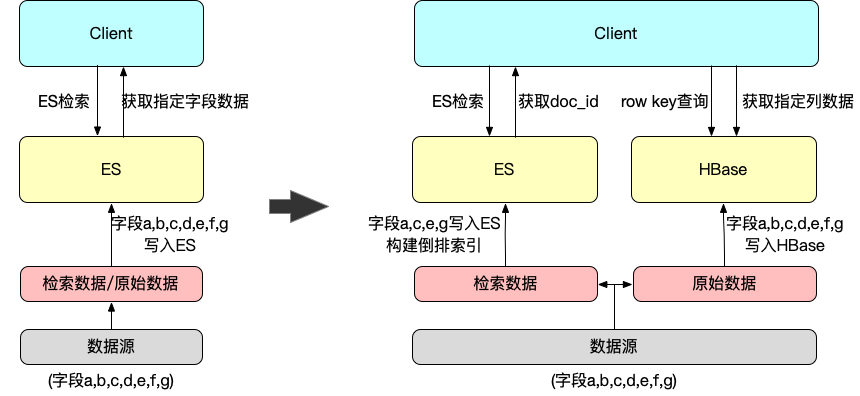
数据源a,b,c,d,e,f,g中,a,c,e,g四个字段是需要索引的,其他为非检索的展示字段。
架构优化前,所有数据都存储在ES,整个检索流程是直接通过ES检索拉取指定展示字段。
优化后,将4个检索字段写入ES构建索引数据,原始数据写入HBase,并设计doc_id为HBase的row key。检索时,ES只负责检索计算,将命中的doc_id拉取至请求侧,然后再用doc_id作为row key查询HBase,拉取指定的展示字段列。做到了存算分离,大大利用了ES的检索能力和HBase的数据读取能力。
和统一存储字段,这增加了查询侧的使用成本。因此我们同样可以使用user api对复杂的处理逻辑进行封装,对上层应用使用依旧是ES查询协议:
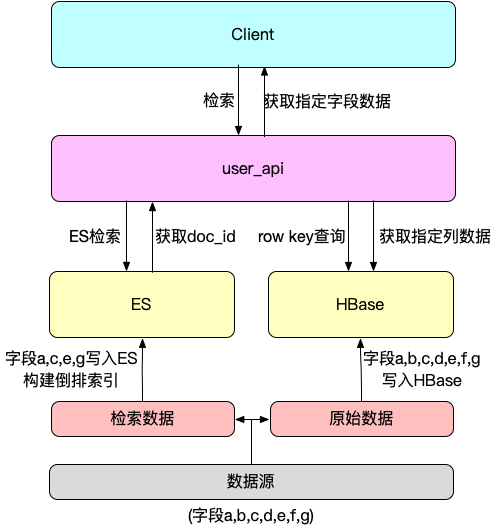
a) 通过ES行存文件裁剪_source字段,不存储文档的原始数据,使用列存数据库代替展示数据的拉取。完成裁剪后,预计可再优化30~50%ES存储优化;
b) _source字段裁剪后,实现了存算分离,ES后续将聚焦于搜索功能,对集群的磁盘IO、CPU和网络带宽的负载压力都有不同程度的优化,提升检索效率;
c) 存储优化后,同样的集群规模可以支持更大量数据的存储搜索,满足更庞大的搜索需求。
本文通过对海量存储搜索场景的痛点剖析,一步一步分析ES存储特性、数据特性,通过构建统一存储字段的方案进行存储和查询优化;然后进一步引进二级索引的方案,非检索的数据(_source)通过列存数据库进行存储,充分利用ES的搜索能力和列存数据库的实时读写能力,成功实现降存储成本、增搜索效率的优化。
优点
完全基于ES的数据存储优化,不需要引入其他组件即可快速实现,针对数值型字段占比高且字段命名字符多的数据优化收益非常明显。
缺点
a) 存储改造成本:数据存储时,需要在存储时通过数据配置映射的具体字段序号对字段值进行连接封装,考虑数据配置的存取维护;
b) 查询改造成本:数值型字段值杂糅在一起,使用的时候无法通过字段名直接读取需要展示的字段值。也需要在抽取解析字段时进行同等反向操作,增加了检索的改造成本。
优点
实现了真正意义上的存算分离,存储成本优化和查询增效的收益都更大
缺点
a) 查询成本:和统一存储字段的引入类似,通过ES搜索命中文档id后,需要再用文档id去列存数据库进行数据查询,需要增加更多的搜索后台技术栈,开发成本更高;
b) 数据一致性:需要保障数据入库HBase和ES的先后顺序和一致性,入ES构建倒排表之前,需要确保文档先落盘列存数据库,以实现用户检索命中的文档可以在列存中查询原始数据列,否则用户查询将面临数据不一致的问题。
c) 维护成本:新增了hbase组件,增加了hbase集群的维护成本。
两个方案有各自的优势和劣势,对待不同的应用场景可以采取不同的方案:统一存储字段方案更轻量,更快速落地,缺点少,收益快;二级索引收益更大,更彻底,但改造成本和后续运维成本会更高,需要考虑更多的细节。
