

导读:springboot2 项目监控服务 ,采用Micormeter度量指标库,帮助我们监控应用程序的度量指标,并将其发送到Prometheus中。监控指标有系统负载、内存使用情况、应用程序的响应时间、吞吐量、错误率等。
micrometer 度量指标库,对springboot应用程序监控指标的采集主要体现在JVM的众多的监控项。
序号 | 指标 | 类型 | 含义 | 原文 |
|---|---|---|---|---|
1 | logback_events_total | counter | 记录到日志的错误级别事件数 | Number of error level events that made it to the logs |
2 | system_cpu_usage | gauge | 整个系统的“最近cpu使用情况” | The "recent cpu usage" for the whole system |
3 | system_load_average_1m | gauge | 系统负载 | The sum of the number of runnable entities queued to available processors and the number of runnable entities running on the available processors averaged over a period of time |
4 | system_cpu_count | gauge | java虚拟机可用的处理器数量 | The number of processors available to the Java virtual machine |
5 | process_start_time_seconds | gauge | 自unix时代以来进程的开始时间(秒) | Start time of the process since unix epoch. |
6 | process_cpu_usage | gauge | java虚拟机进程的“最近CPU使用” | The "recent cpu usage" for the Java Virtual Machine process |
7 | process_uptime_seconds | gauge | java虚拟机的运行时间 | The uptime of the Java virtual machine |
8 | process_files_open_files | gauge | 打开文件描述符数量 | The open file descriptor count |
9 | process_files_max_files | gauge | 最大文件描述符数量 | The maximum file descriptor count |
10 | tomcat_sessions_expired_sessions_total | counter | tomcat过期会话数总计 | |
11 | tomcat_sessions_rejected_sessions_total | counter | tomcat拒绝会话数总计 | |
12 | tomcat_sessions_active_max_sessions | gauge | tomcat_活跃会话最大数量 | |
13 | tomcat_sessions_created_sessions_total | counter | tomcat会话创建会话总数 | |
14 | tomcat_sessions_active_current_sessions | gauge | tomcat当前活跃会话数 | |
15 | tomcat_sessions_alive_max_seconds | gauge | 最大tomcat会话存活时间 | |
16 | jvm_classes_loaded_classes | gauge | Java虚拟机中当前加载的类数 | The number of classes that are currently loaded in the Java virtual machine |
17 | jvm_classes_unloaded_classes_total | counter | 未加载的classes数 | The total number of classes unloaded since the Java virtual machine has started execution |
18 | jvm_memory_used_bytes | gauge | 内存使用大小 | The amount of used memory |
19 | jvm_memory_max_bytes | gauge | 可用于内存管理的字节的最大内存量 | The maximum amount of memory in bytes that can be used for memory management |
20 | jvm_memory_committed_bytes | gauge | 提交给Java虚拟机使用的内存量(字节) | The amount of memory in bytes that is committed for the Java virtual machine to use |
21 | jvm_buffer_memory_used_bytes | gauge | JVM缓冲区已用内存 | An estimate of the memory that the Java virtual machine is using for this buffer pool |
22 | jvm_buffer_total_capacity_bytes | gauge | 缓冲区的总容量的估计 | An estimate of the total capacity of the buffers in this pool |
23 | jvm_buffer_count_buffers | gauge | 当前缓冲区数 | An estimate of the number of buffers in the pool |
24 | jvm_gc_pause_seconds | summary | GC暂停时间 | Time spent in GC pause |
25 | jvm_gc_pause_seconds_max | gauge | GC最大暂停时间 | Time spent in GC pause |
26 | jvm_gc_max_data_size_bytes | gauge | 老年代内存池的最大大小 | Max size of old generation memory pool |
27 | jvm_gc_memory_allocated_bytes_total | counter | 在一次GC之后到下一次GC之前,年轻一代内存池的大小增加 | Incremented for an increase in the size of the young generation memory pool after one GC to before the next |
28 | jvm_gc_live_data_size_bytes | gauge | full GC后的老年代内存池大小 | Size of old generation memory pool after a full GC |
29 | jvm_gc_memory_promoted_bytes_total | counter | 从GC之前到GC之后老年代内存池大小正增长的计数 | Count of positive increases in the size of the old generation memory pool before GC to after GC |
30 | jvm_threads_states_threads | gauge | 当前处于NEW状态的线程数 | The current number of threads having NEW state |
31 | jvm_threads_live_threads | gauge | 当前活动线程数,包括守护进程线程和非守护进程线程 | The current number of live threads including both daemon and non-daemon threads |
32 | jvm_threads_daemon_threads | gauge | 当前守护进程线程的数量 | The current number of live daemon threads |
33 | jvm_threads_peak_threads | gauge | JVM峰值线程数 | The peak live thread count since the Java virtual machine started or peak was reset |
34 | http_server_requests_seconds | summary | http请求调用情况 | |
35 | http_server_requests_seconds_max | gauge |
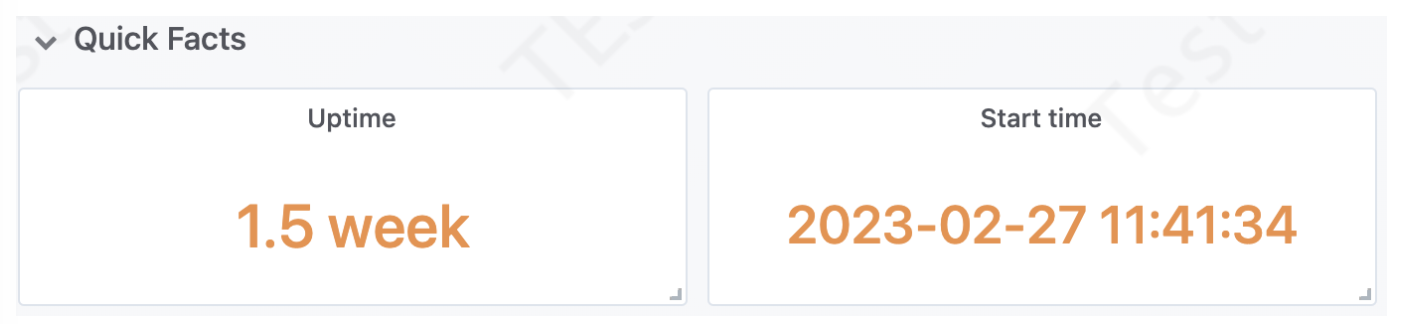
Start time: JVM启动时间 - 即:根据该指标可以知道目前程序启动的时间
Uptime: JVM运行时间 - 即:根据该指标可以知道目前程序运行时长
JVM中的IO操作是应用程序中非常重要的一部分,因此需要监控和衡量相应的指标来保证系统的正常运行。
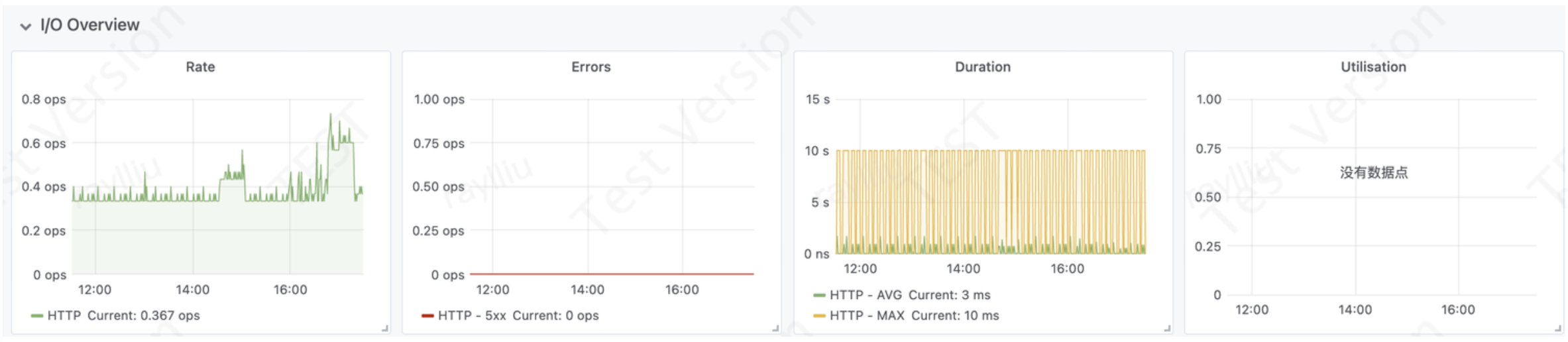
Rate 图中的: QPS :每秒查询率,是一台服务器每秒能够响应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
简单的说,QPS = req/sec = 请求数/秒。它代表的是服务器的机器的性能最大吞吐能力。
Duration 图中:AVG:指Average Latency 平均等待时间,请求处理时长(min:最小值,max:最大值,avg:平均值,current:实时)
JVM中IO衡量指标的详细解释和问题定位场景的举例:

java虚拟机把堆内存划分为三个区域:年轻代,老年代,和永久代. 1,年轻代: 年轻代又分为一个Eden区和两个Survivor区(一个from Survivor和一个to Survivor),每次只会使用Eden和其中一个Survivor区,这么分配的原因是年轻代采用了”复制”算法来回收.当创建新的对象时,(大部分情况下)这个对象所占的空间会在Eden区分配,如果Eden区的空闲空间不足,这时虚拟机会触发一次Minor GC,将Eden区和from Survivor区中还存活的对象转移到to Survivor区中. 在经历若干次Minor GC之后,如果对象还是存活,那就会被移到老年代中去. 2,老年代(old) 存放系统中长期存活的对象,比如通过spring托管的一些单例对象,如service对象,dao对象等.还有一部分是在Minor GC后年轻代的空间仍然不足时,从年轻代转移过来的对象,这部分对象一般是导致系统发生Full GC的主要原因. 3,永久代(perm) 存储已被虚拟机加载的类信息,常量,静态变量,即时编译器编译后的代码等数据.

Heap Used: 堆内存使用率; 根据:堆内存已使用(字节)/ 堆内存大小(字节) 计算得出
Non-Heap used: 堆外内存使用率; 根据: 堆外内存已使用(字节)/ 堆外内存大小(字节) 计算得出
常见问题:
内存使用率高;长时间达到70% 以上;
当应用程序中堆内存使用率一致很高,且不下降时。势必造成程序中的内存资源耗尽,出现卡死情况;
可以根据老年代使用率来查看;如使用率超过90%;
其他常见问题:
场景一:内存溢出,JVM堆区或方法区放不下存活及待申请的对象。如:高峰期系统出现 OOM(Out of Memory)异常,需定位内存瓶颈点来指导优化。
场景二:内存泄漏,不会再使用的对象无法被垃圾回收器回收。如:系统运行一段时间后出现 Full GC,甚至周期性 OOM 后需人工重启解决。
场景三:内存占用高。如:系统频繁 GC ,需定位影响服务实时性、稳定性、吞吐能力的原因。
问题分析(出现的问题有):
1、内存分配的问题
2、长期持有supersql big 对象消耗内存
3、死锁问题
4、poll长连接较多或者其他导致兵法线程增多
具体问题分析参照下述监控指标
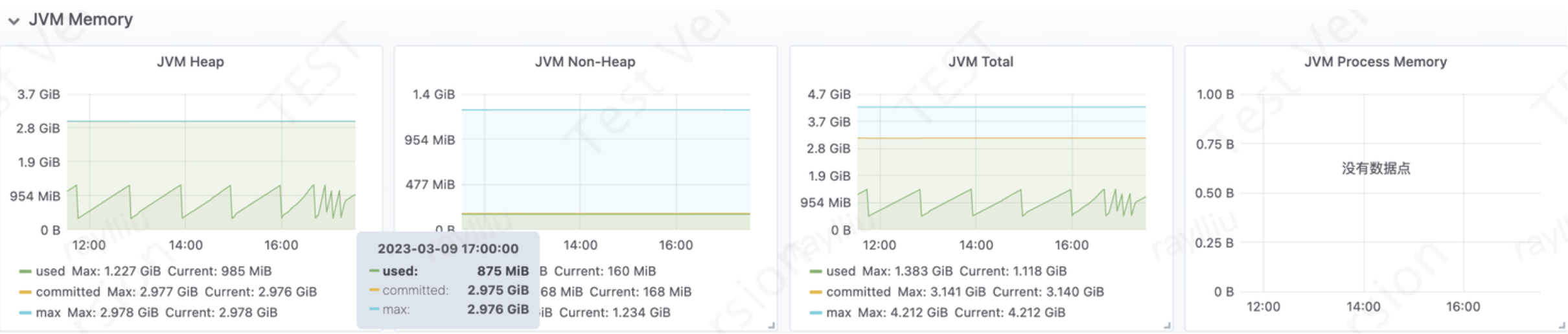
JVM Memory指标的详细解释和生产环境中如何定位问题场景的举例: JVM Memory指标包括以下几个方面:
2. JVM Non-Heap Memory:非堆内存指的是JVM中存放类信息、方法信息、常量等数据的内存区域。Non-Heap Memory指标可分为以下几个维度:
3. JVM Total JVM 内存使用总量
综上所述,通过监控Micrometer中的JVM Memory指标,可以定位生产环境中的一些内存问题,进而采取相应的优化措施提高系统性能。
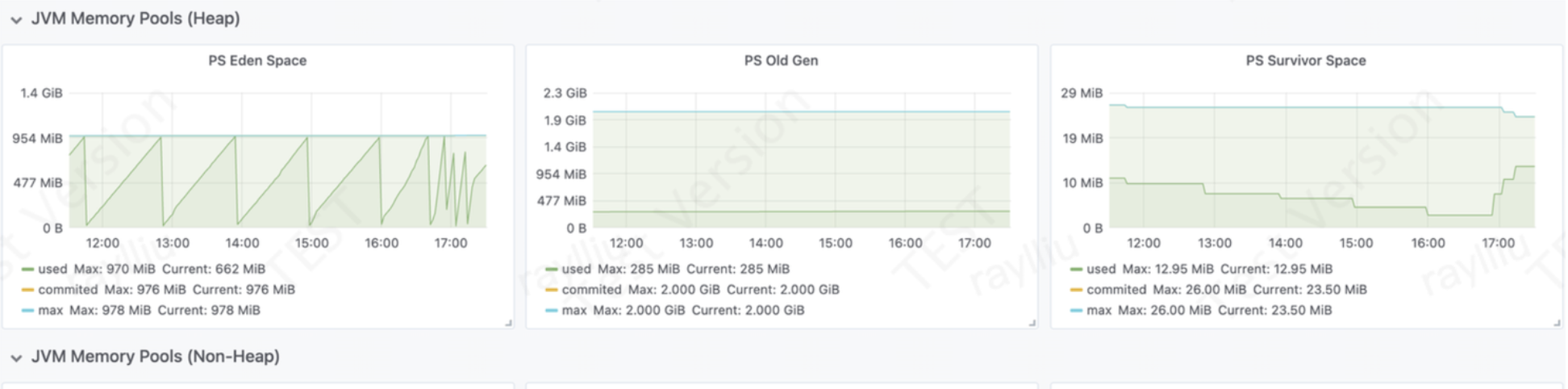
PS Eden Space:新生代
PS Old Gen:老年代
一般情况新创建的对象会放到新生代中,只有经过一定次数的GC后还没有被回收的对象,我们认为这部分对象在未来也会长时间存在,所以会把这部分的对象转移到老年代的区域中去。
PS Survivor Space:新生代
GC把垃圾对象回收后如果不对存活下来的对象进行整理,那么就会出现很多不连续的内存空间,这也就是我们常说的空间碎片,因为没有连续的空间分配,这样就可能造成我们一个大对象过来我们没有对应的连续空间分配,但是内存里其实是有能够容纳对象的总空间的。
所以为了减少这种空间碎片,我们就使用了另一种方式,把新生代分为了Eden 区和Survior 区,在进行垃圾回收时,先把存活的对象复制到 Survior 区,然后再对Eden区统一进行清理,这样的话Eden区每次GC过后都是留下的一片连续的空间。
2. Memory Pool指标可分为以下几个维度:
通过监控JVM Memory Pools(Heap)指标,我们可以发现以下问题:
综上所述,通过监控JVM Memory Pools(Heap)指标,我们可以及时发现和解决Java应用程序中的内存问题,提高系统性能。
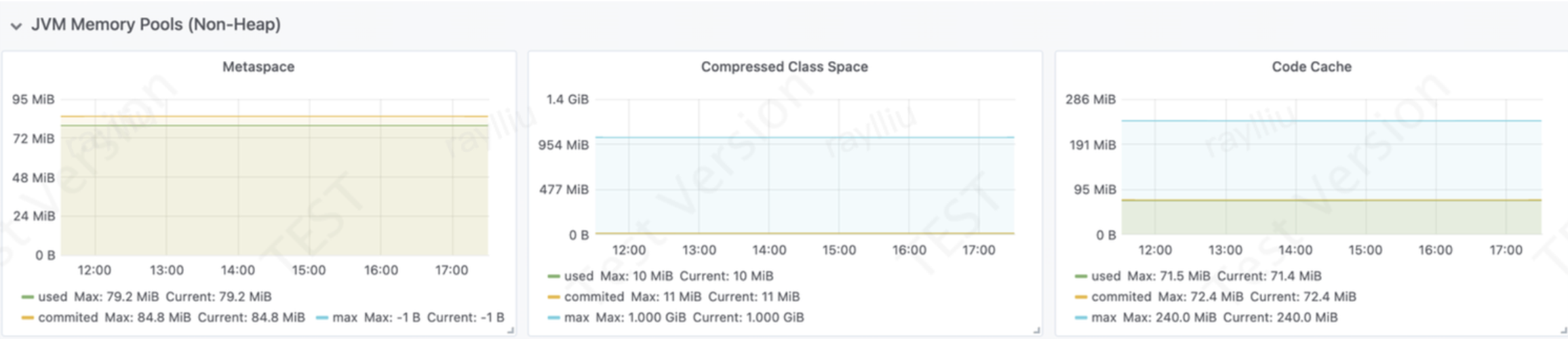
JVM Memory Pools(Non-Heap)指标用于监控Java应用程序的非堆内存使用情况,包括Metaspace、Code Cache、Compressed Class Space等。它提供了多个维度的指标,可以帮助我们深入了解Java非堆内存的使用状况,发现问题并进行针对性的优化。
非堆内存也叫做PermGen space(永久代),与新生代和老年代概念对齐,就是说是永久保存的区域, 用于存放Class和Meta信息,Class在被Load的时候被放入该区域,GC应该不会对PermGen space进行清理。
综上所述,通过监控JVM Memory Pools(Non-Heap)指标,我们可以及时发现和解决Java应用程序中的非堆内存问题,提高系统性能。
服务内存占用过高的原因排查思路:
相关命令:
1、free -m # 查看内存使用情况,后面加个m是以M为单位显示
2、查看哪几个进程内存占用最高:top -c,输入大写M,以内存使用率从高到低排序
VSS- Virtual Set Size 虚拟耗用内存(包含共享库占用的内存)
RSS- Resident Set Size 实际使用物理内存(包含共享库占用的内存)
PSS- Proportional Set Size 实际使用的物理内存(比例分配共享库占用的内存)
USS- Unique Set Size 进程独自占用的物理内存(不包含共享库占用的内存)
一般来说内存占用大小有如下规律:VSS >= RSS >= PSS >= USS
3、通过jmap -heap 进程id 命令排除是由于堆分配内存问题
jmap -heap 21114
4. 查看进程中占用资源最大的前20个对象(主要在对应程序启用用户下执行)
jmap -histo:live 19424 |head -20
5. jstat查看进程的内存使用情况
jstat -gcutil 19424
现在:可以根据上述监控指标得出,并且配合log中定位代码存在不合理情况
log中查看
一般情况下出现下列异常可直接定位: 堆溢出: java.lang.OutOfMemoryError:Java heap spcace 栈溢出: java.lang.StackOverflowError 方法区溢出: java.lang.OutOfMemoryError:PermGen space
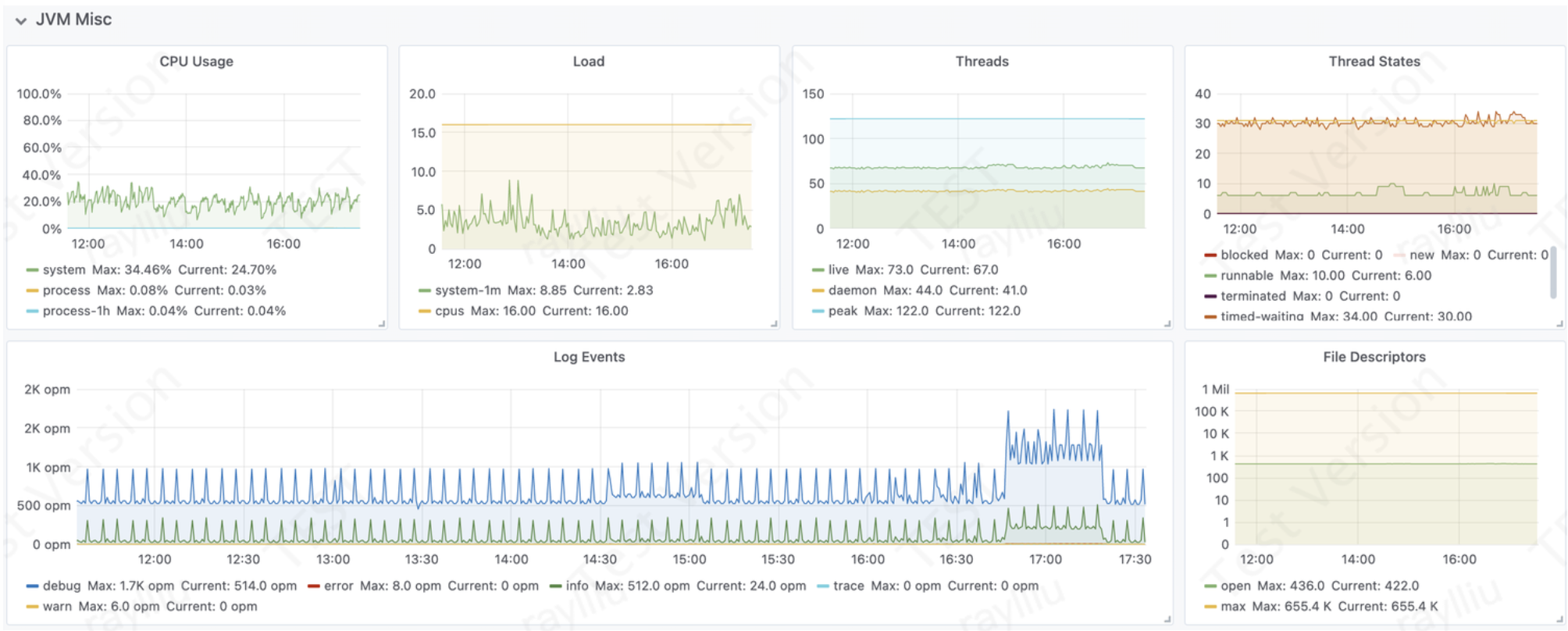
system: CPU花了多少比例的时间在内核空间运行。分配内存、IO操作、创建子进程……都是内核操作
cpu负载:负载表示的是“等待进程的平均数”,运行态(running)和不可中断状态(interruptible)才会被加入到负载等待进程中,具体为下面两种情况:
NEW:尚未启动的线程的线程转台
RUNNABLE:可运行线程的线程状态。线程在运行或者正在获取CPU时间片
BLOCKED:线程的线程状态被阻止,正在等待监视器锁。
WAITING:等待线程的线程状态。
TIMED_WAITING:具有指定等待时间的等待线程的线程状态。调用某个线程的具有指定正等待时间的方法时,所处于指定等待时间的等待线程的线程状态。
TERMINATED:终止线程的线程状态。
每分钟上报的日志数量
file descriptors是一个非负整数,一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。
程序打开一个现有文件或者创建一个新文件,内核向该进程返回一个文件描述符。
open: JVM当前打开的文件描述符数;
max: JVM进程最大可以打开的文件描述符数;
常见问题:
java应用程序,频繁的IO读写,创建过多的线程,CPU都会较高,而线程死锁或者死循环基本是导致cpu高的原因。
后台常用命令:
jstack -1 pid # 打印进程的对战信息,结合代码查找占用CPU的问题。
Garbage Collection指标用于监控Java应用程序的垃圾回收情况
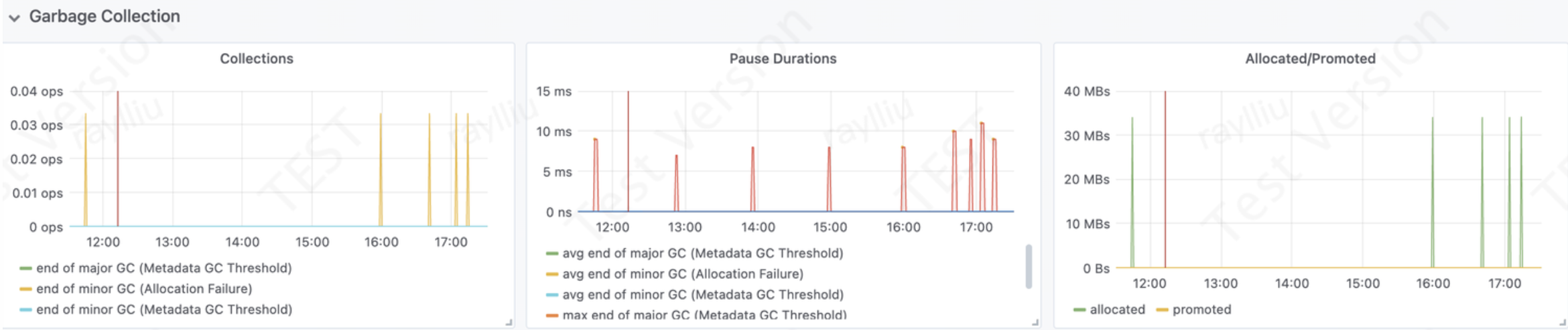
collections图:
1、Metadata GC threshold是指元数据空间的GC阈值。在JVM中,元数据空间是用来存储Java类信息、常量池、方法信息等元数据的空间。当元数据空间满了之后,就会触发元数据空间的GC,回收无用的元数据信息。 Metadata GC threshold指标用于监控元数据空间的GC阈值。当元数据空间的使用率超过了阈值,就会触发元数据空间的GC。Metadata GC threshold指标可以用来监控元数据空间的使用情况,以及GC对元数据空间的影响程度。
a)end of minor GC:表示minor GC结束的时间戳,即新生代垃圾回收结束的时间戳。在JVM中,新生代的GC次数远远多于老年代,因此用end of minor GC指标来刻画新生代GC的情况。end of minor GC指标可以用来监控新生代GC的频率和时间间隔,以及GC的效率和吞吐量。
b) end of major GC:表示major GC结束的时间戳,即老年代垃圾回收结束的时间戳。在JVM中,老年代的GC次数比新生代少,但是GC的影响更大,因此用end of major GC指标来刻画老年代GC的情况。end of major GC指标可以用来监控老年代GC的频率和时间间隔,以及GC的效率和吞吐量。
2) ops/sec: 每秒操作数
3) allocation failure:表示在GC过程中出现内存分配失败的次数。allocation failure指标可以用来监控内存的使用情况,以及GC对内存使用的影响程度。如果allocation failure指标持续增长,就说明内存不足,可能需要增加堆内存或优化程序的内存使用方式。
pause durations图:
表示GC暂停的时间。GC暂停是指在GC期间应用程序的执行被中断了,这段时间内应用程序无法执行任何操作。
pause durations指标可以用来监控GC的效率和吞吐量,以及GC对应用程序的影响程度。
Allocated/Promoted图:
1)allocated表示当前GC周期中新生代分配的对象大小;
2)promoted表示当前GC周期中老年代晋升的对象大小;
allocated/promoted指标可以用来监控垃圾回收的内存使用情况,以及GC对内存使用的影响程度。
综上所述,通过监控Garbage Collection指标,我们可以及时发现和解决Java应用程序中的垃圾回收问题,提高系统性能。
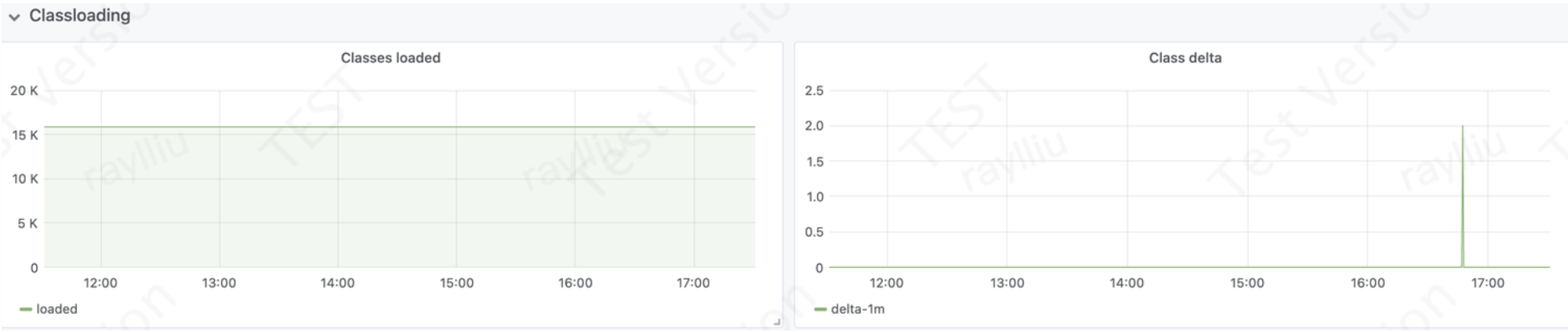
Class loaded 和 Class delta是Java虚拟机(JVM)的两个指标,用于衡量JVM加载和卸载类的情况。
Class loaded 指标表示JVM自启动以来已经加载的类的总数。这个指标可以用来判断应用程序是否存在类加载过多的问题。如果Class loaded指标的增长速度太快,那么就可能存在内存泄漏或者类重复加载等问题。
Class delta 指标表示自上次垃圾回收以来,类加载器动态加载和卸载的类的数量。这个指标可以用来判断应用程序是否存在类加载和卸载不平衡的情况。如果Class delta指标的值过大,说明有太多的类被加载和卸载,可能会导致JVM性能下降。
综合来说,Class loaded和Class delta指标可以用来监控JVM的类加载和卸载状况,帮助开发人员发现和解决可能存在的性能问题。
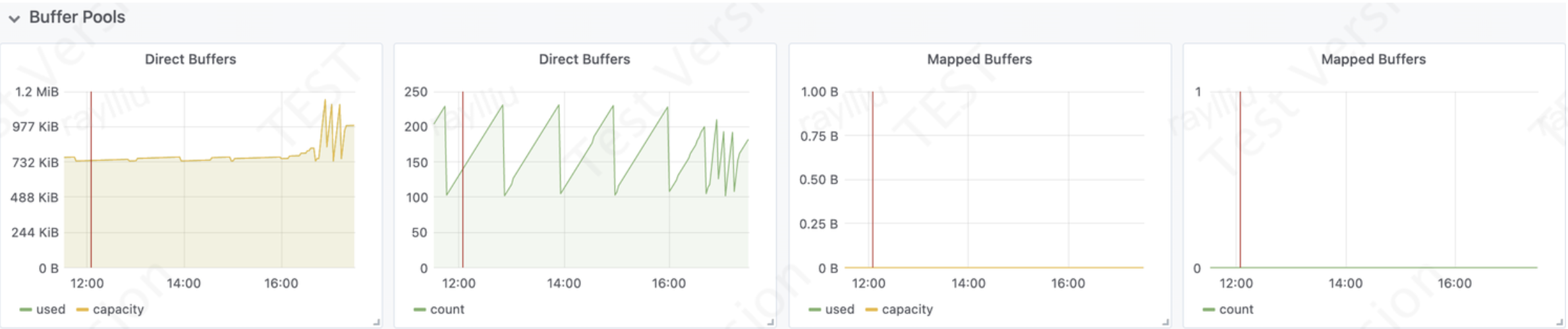
DirectBuffer和MappedByteBuffer是Java NIO(New IO)中的两种缓冲区类型,用于进行内存映射和直接内存访问。这两种缓冲区类型在不同的场景下具有不同的衡量指标和定位问题的方法。
DirectBuffer衡量指标:
指标模版:
https://grafana.com/search/?term=micrometer
