

尽管在日常的开发工作中,开发团队已经在发布产品前花费大量资源和精力进行软件测试,但实际上,已发布的软件仍然有一些错误,而这些错误往往表现为release版本运行时崩溃
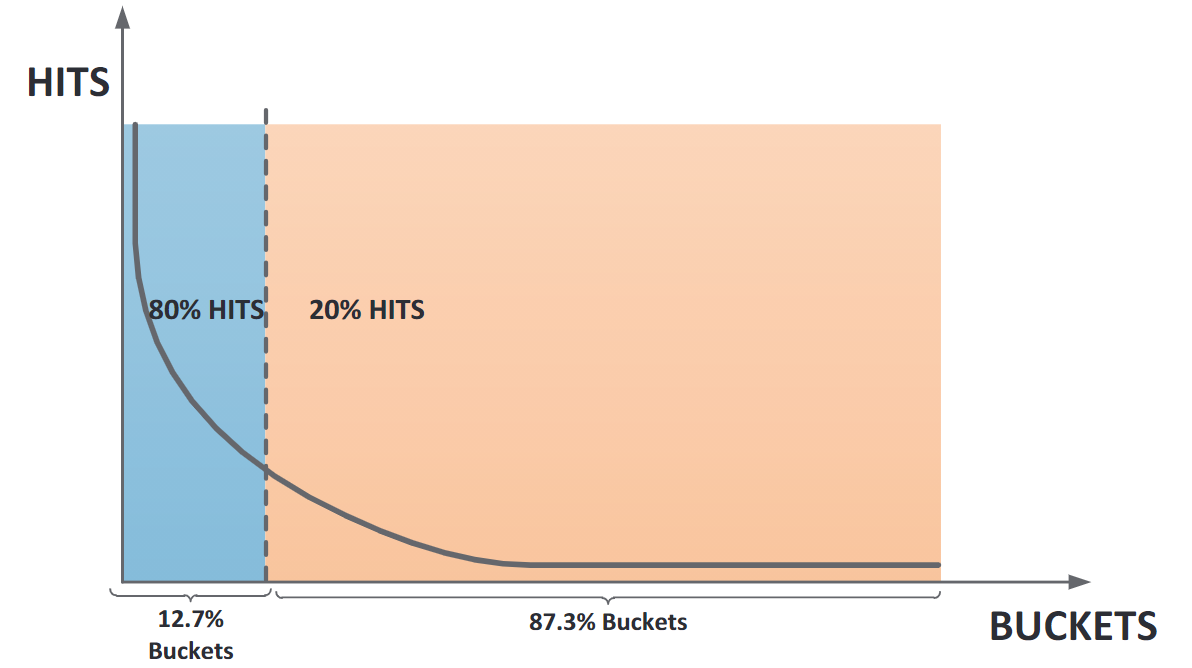
针对这个现象,微软部署了一套分布式系统WER(Windows Error Reporting)用于自动从崩溃现场收集崩溃信息、聚类到各个Bucket,当某个Bucket内的崩溃次数达到某个阈值后,WER会自动为其生成错误报告,并将其提供给开发人员;WER已经在运行的十几年内证明了其价值,收集了数十亿词崩溃报告,大大加快了开发人员的Debug流程,但另一方面,WER也仍存在一些问题,如“第二个Bucket问题”以及“长尾巴”问题(见下图)
ReBucket算法就是为了解决这些已知问题而产生的一种堆栈聚类算法
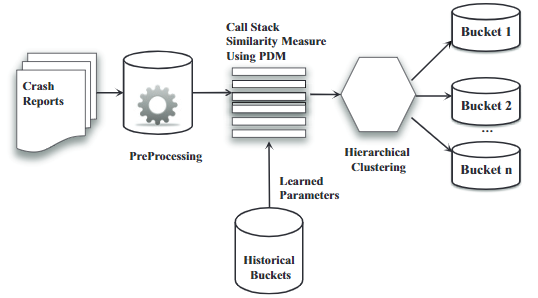
在ReBucket算法中,对于一系列新到达的崩溃信息(一个时间片内到达的崩溃信息),首先我们对其进行预处理,以提取简化的堆栈信息。然后使用层次聚类方法将崩溃报告聚类到相应的Bucket内;同时可以使用历史Bucket数据构建的训练模型训练在PDM中使用到的参数,下图为ReBucket算法的总流程图
在计算PDM并进行聚类前我们需要从原始堆栈信息中删除以下几种函数(方法),以提取我们真正需要的堆栈信息:
在计算堆栈间相似度的过程中需要用到两个度量:
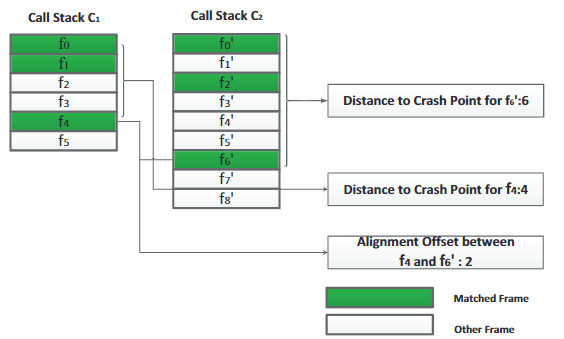
以上图中的两个堆栈为例,对于两个堆栈C1C_1C1和C2C_2C2,崩溃点都位于顶部帧,C1C_1C1中的f0f_0f0,f1f_1f1,f4f_4f4与C2C_2C2中的f0f_0f0,f2f_2f2,f6f_6f6匹配,则可以很明显地算出f4f_4f4和f6f_6f6的对齐偏移为2
在ReBucket算法中,我们使用PDM来衡量两个堆栈之间的相似度,而PDM是基于以下两个观点的:
基于这两个观点,两个堆栈C1C_1C1和C2C_2C2之间的相似度可以由以下流程得出:
定义LLL为C1C_1C1和C2C_2C2之间所有公共帧序列(子序列)的集合,LiL_iLi为公共帧序列之一,Si,1,Si,2,…Si,kS_{i, 1}, S_{i, 2},\ldots S_{i, k}Si,1,Si,2,…Si,k为LiL_iLi内相匹配的函数
L={L1,Ls,L3…}Li={Si,1,Si,2,Si,3,…Si,k…}L=\left{L_{1}, L_{s}, L_{3} \ldots\right} \quad L_{i}=\left{S_{i, 1}, S_{i, 2}, S_{i, 3}, \ldots S_{i, k} \ldots\right}L={L1,Ls,L3…}Li={Si,1,Si,2,Si,3,…Si,k…}
定义POS(Cq,Si,k)POS(C_q, S_{i,k})POS(Cq,Si,k)为Si,kS_{i,k}Si,k在CqC_qCq堆栈内的位置,lll为堆栈C1C_1C1和C2C_2C2中帧数量的最小值,由下列公式(1)(1)(1)可得出C1C_1C1和C2C_2C2之间的相似度:
{sim(C1,C2)=maxLi∈LQ(Li)∑j=0le−cjQ(Li)=∑si,k∈Lie−cmin(Pos(C1,si,k),Pos(C2,si,k))e−o∣Pos(C1,si,k)−Pos(C2,si,k)∣(1)\left{ \begin{array}{lr} \operatorname{sim}\left(C_{1}, C_{2}\right)=\frac{\max_{L_{i}\in L} \left Q\left(L_{i}\right) \right }{\sum_{j=0}^{l} e^{-cj}} \\ Q\left(L_{i}\right)=\sum_{s_{i, k} \in L_{i}}e^{-c \min \left( \operatorname{Pos}\left(C_{1}, s_{i, k}\right), \operatorname{Pos}\left(C_{2}, s_{i, k}\right) \right)}e^{-o \mid \operatorname{Pos}\left(C_{1}, s_{i, k}\right)-\operatorname{Pos}\left(C_{2}, s_{i, k}\right) \mid} \end{array} \right. \quad (1)⎩⎪⎨⎪⎧sim(C1,C2)=∑j=0le−cjmaxLi∈LQ(Li)Q(Li)=∑si,k∈Lie−cmin(Pos(C1,si,k),Pos(C2,si,k))e−o∣Pos(C1,si,k)−Pos(C2,si,k)∣(1)
其中,ccc为到顶部帧的距离系数,ooo为对齐偏移系数。ccc和ooo的值可以根据以往的经验手动设置。后续还有一种基于学习的自动获取最优系数值的方法。Q(Li)Q\left(L_{i}\right)Q(Li)用来衡量在公共帧序列LiL_iLi中匹配的函数的相似度值。其中第一个指数函数考虑了一对匹配函数到顶部帧的最小距离,第二个指数函数考虑最小对齐偏移,到顶部帧的距离以及对齐偏移越小,Q(Li)Q\left( L_i \right)Q(Li)的值越大
从公式(1)(1)(1)中可以看出:堆栈相似性的度量值由Q(Li)Q\left(L_{i}\right)Q(Li)值最大的公共帧序列决定,但穷举所有的公共帧序列效率很低,这里就可以用到求最长公共子序列问题的方法了,用二维动态规划的方法可以高效地求出Q(Li)Q\left(L_{i}\right)Q(Li)值最大的公共帧序列,具体步骤如下:
Mi,j=max{Mi−1,j−1+cost(i,j)Mi−1,jMi,j−1(2)cost(i,j)={e−c∗min(i,j)e−o∗∣i−j∣if ith frame of C1==jth frame of C20 otherwise (3)sim(C1,C2)=Mm,n∑j=0le−cj(4)\begin{array}{lr} M_{i, j}=\max \left{\begin{array}{lr} M_{i-1, j-1} + \operatorname{cost}(i, j) \ M_{i-1, j} \ M_{i, j-1} \end{array}\right. &(2) \\ \operatorname{cost}(i, j)= \left{\begin{array}{lr} e^{-c^{*} \min (i, j)} e^{-o^{*} \left| i-j \right|} & \text {if jth frame of } C_2 \ 0 & \text { otherwise } \end{array}\right. &(3) \\ \operatorname{sim}\left(C_{1}, C_{2}\right)=\frac{M_{m, n}}{\sum_{j=0}^{l} e^{-c j}} &(4) \end{array}Mi,j=max⎩⎨⎧Mi−1,j−1+cost(i,j)Mi−1,jMi,j−1cost(i,j)={e−c∗min(i,j)e−o∗∣i−j∣0if ith frame of C1==jth frame of C2 otherwise sim(C1,C2)=∑j=0le−cjMm,n(2)(3)(4)
通过PDM我们就可以衡量任意两个堆栈的相似度,这也是下面对堆栈进行聚类操作的前提和依据
对堆栈的聚类基于前面通过PDM计算的堆栈相似性度量,如果堆栈之间非常相似,则相关的崩溃报告会被分到相同的Bucket内
对堆栈聚类这里采用层次聚类方法(一种自底向上的聚类方法),其流程大致为:在聚类的开始,每个堆栈都属于其自己的集群;每一次迭代选择**“最近”**的集群并进行合并
为了确定某个集群在一次迭代中应该和哪个集群合并,我们需要定义集群之间的距离度量,这里我们将这个度量定义为两个集群中所有堆栈之间的最大距离(见公式(5)(5)(5),(6)(6)(6)),其中CliCl_iCli和CljCl_jClj为一对集群,C1C_1C1和C2C_2C2分别是CliCl_iCli和CljCl_jClj中的堆栈
distance(Cli,Clj)=maxC1∈Cli,C2∈Cljdist(C1,C2)(5)dist(C1,C2)=1−sim(C1,C2)(6)\begin{array}{lr} \operatorname{distance}\left({Cl}_{i}, {Cl}_{j}\right)=\max_{C_{1} \in {Cl}_{i}, C_{2} \in {Cl}_{j}} \operatorname{ dist }\left(C_{1}, C_{2}\right) & (5) \ \operatorname{ dist }\left(C_{1}, C_{2}\right)=1-\operatorname{sim}\left(C_{1}, C_{2}\right) & (6) \end{array}distance(Cli,Clj)=maxC1∈Cli,C2∈Cljdist(C1,C2)dist(C1,C2)=1−sim(C1,C2)(5)(6)
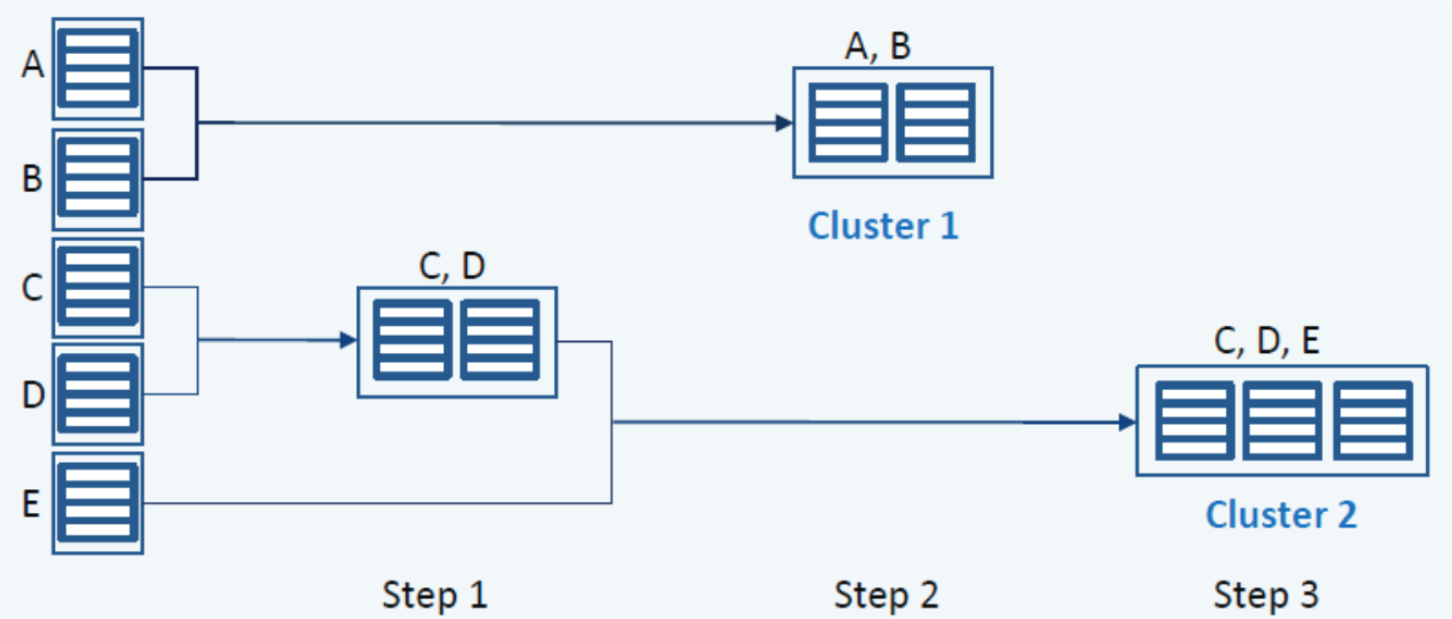
在一次聚类过程中,考虑最坏的情况,所有堆栈都合并为一个集群,则层次聚类方法的时间复杂度为O(n3)O(n^3)O(n3),但在这里我们还会采用距离阈值ddd作为聚类过程的停止标准。ddd的值可以手动设置,也可以通过训练学习;一旦一个集群与其它集群距离的最小值大于距离阈值ddd,则停止对该集群的聚类过程;最后则可以得到一系列包含集群和对应崩溃报告的Bucket,如上图中最后生成了两个Bucket
PDM中用到的两个参数:
分层聚类方法中的距离阈值ddd也是一个需要调优的参数
虽然这些参数都可以手动设置,但因为项目的不同,合适的参数也会不同,所以还是需要一个训练过程来学习这些参数的最优值
首先我们需要根据历史Bucket内的数据和相应的崩溃报告构建数据集,从同一Bucket中提取由开发人员确认的由相同错误引起的崩溃报告作为聚类正确的数据,从不同(不相似)的Bucket中提取由不同错误引起的崩溃报告作为聚类错误的数据(由于异类崩溃报告的数量通常很大,这里提取异类崩溃报告的过程是通过随机采样进行的)。基于获得的重复的和不相似的崩溃报告,收集成对的相似和不相似的堆栈,构建成数据集
对于需要训练的三个参数,它们的值独立变化,不同的参数直接导致不同的聚类性能,所以这里采用一种基于搜索的算法(类似Grid Search),在三个参数的有限集合的笛卡尔积内穷举搜索最优参数组合,流程如下:
// 训练数据集中的堆栈对的数据结构
type trainStackPair struct {
//TODO: 添加堆栈对数据
similarity float64
predictIsSimilar bool
isSimilar bool
}
// 训练参数
func trainParams() (bestParamC float64, bestParamO float64, bestParamD float64) {
var (
trainData []trainStackPair
paramC float64
paramO float64
paramD float64
bestFMeasure float64
)
for paramC <= 2 {
paramO = float64(0)
for paramO <= 2 {
paramD = float64(0)
for paramD <= 1 {
for _, pair := range trainData {
pair.getSimilarity()
if pair.similarity > float64(1 - paramD) {
pair.predictIsSimilar = true
} else {
pair.predictIsSimilar = false // 这里可以删掉,因为bool默认值就是false
}
}
if newFMeasure := getFMeasure(trainData); newFMeasure > bestFMeasure {
bestParamC, bestParamO, bestParamD = paramC, paramO, paramD
bestFMeasure = newFMeasure
}
paramD += 0.01 //d的学习率为0.01
}
paramO += 0.1 //o的学习率为0.1
}
paramC += 0.1 //c的学习率为0.1
}
return
}
func (*trainStackPair) getSimilarity() (similarity float64) {
//TODO: PDM算法获取堆栈间相似度
return
}
func getFMeasure(stackPairs []trainStackPair) (FMeasure float64) {
length := len(stackPairs)
TP, FN, FP, TN := 0, 0, 0, 0
for _, pair := range stackPairs {
if pair.isSimilar {
if pair.predictIsSimilar {
TP += 1
} else {
FN += 1
}
} else {
if pair.predictIsSimilar {
FP += 1
} else {
TN += 1
}
}
}
FMeasure = 2 * float64(TP) / float64(length+TP-TN)
return
}其中ccc,ooo,ddd都初始化为0,最大值分别设定为cmax=2,omax=2,dmax=1c_{max}=2,o_{max}=2,d_{max}=1cmax=2,omax=2,dmax=1,训练中三个参数的学习率(步长)分别固定为0.1, 0.1, 0.01;根据每组参数预测的结果算出F值,最终返回能得到最大F值的参数组
总的来说ReBucket算法可以分为四个模块:
具体实现见下一篇文章
应该放更大的权重在离顶部帧近的帧上,因为bug的根因更容易出现在离顶部帧近的帧上这一观点在实际工程环境中并不对,实际上顶部帧存在许多系统调用 / sdk调用 / hook,所以顶部帧并不一定是bug的根因,这里可能可以利用堆栈预处理中的静态 / 动态白名单机制来解决(动态白名单:当一个方法被review并列入白名单后,若其发生变更,则移出白名单)lock关键字等来分配权重。所以PDM模型应该按照崩溃类型异化