

原文:原创视觉定位框架、简单易用——XRLocalization帮你快速搭建大规模场景XR应用
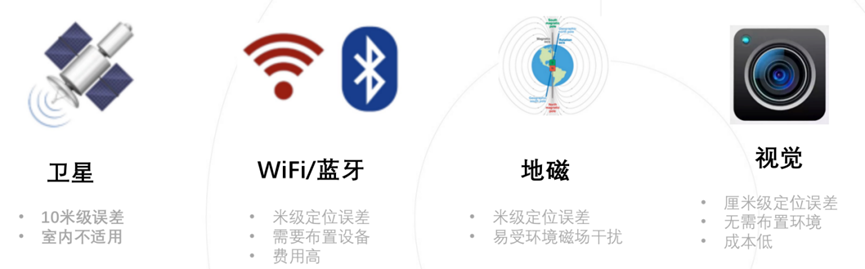
定位在生活中的应用很普遍,随着科技的发展,已经涌现出了多种多样的定位技术。譬如常用的全球定位系统GPS(Global Positioning System), 它通过卫星进行定位,有效定位精度在10米左右,但只适用于室外开阔地带。
针对室内场景,可以基于WiFi、蓝牙或地磁进行定位,有效定位精度在米级。视觉定位通常能够达到分米甚至厘米级的定位精度,适用于室内外场景,无需布置场景,已在自动驾驶、机器人和扩展现实等领域广泛应用。
视觉定位(Visual Localization)根据相机拍摄的图像解算出相机相对场景地图的6DoF位姿。不同于SLAM(Simultaneous Localization and Mapping)进行同步定位与地图构建,视觉定位一般是基于一个预先构建好的地图进行全局定位。

根据地图表达形式的不同, 可以分为基于学习的(Learning-based)和基于结构的(Structure-based)视觉定位。基于学习的视觉定位通过学习的方式将地图隐式地表达成网络模型,定位时通过直接回归相机位姿或回归场景坐标。
基于结构的视觉定位通常利用SfM(Structure from Motion)或SLAM技术生成离线场景地图,定位时先抽取查询图像的视觉特征,再利用特征匹配技术获取与地图的关联,即2D-3D点对应,再使用PnP(Perspective-n-Point)[1]算法解算相机的位姿。
因为基于学习的视觉定位方法往往泛化性较差,而且在大规模场景上的性能也明显差于基于结构的视觉定位方法,所以目前工业界一般还是采用基于结构的视觉定位方法,但往往会对其中的部分模块用学习的方法进行改进,譬如特征检测和描述、特征匹配等。
目前社区存在很多开源视觉定位算法,但基本都是用来进行算法评估,不能直接作为定位服务进行使用。我们搭建的开源视觉定位算法库XRLocalization,不仅可以直接作为定位服务使用,而且还可以提供基于实际应用条件下的各个模块的算法评估。
XRLocalization是OpenXRLab空间计算平台中基于Python的视觉定位算法库。该库是一个基于结构的视觉定位算法库,能够支持在超大规模场景下鲁棒、高效、高精度定位, 且具有以下特性。
为了使得研究者方便验证各个部分对定位的影响,以及根据自己的应用场景需求对算法进行不同的配置,XRLocalization采用层次化和模块化的设计。自上而下分成三层,包括基础模块层、工具与算法层和应用接口层,如下图所示。
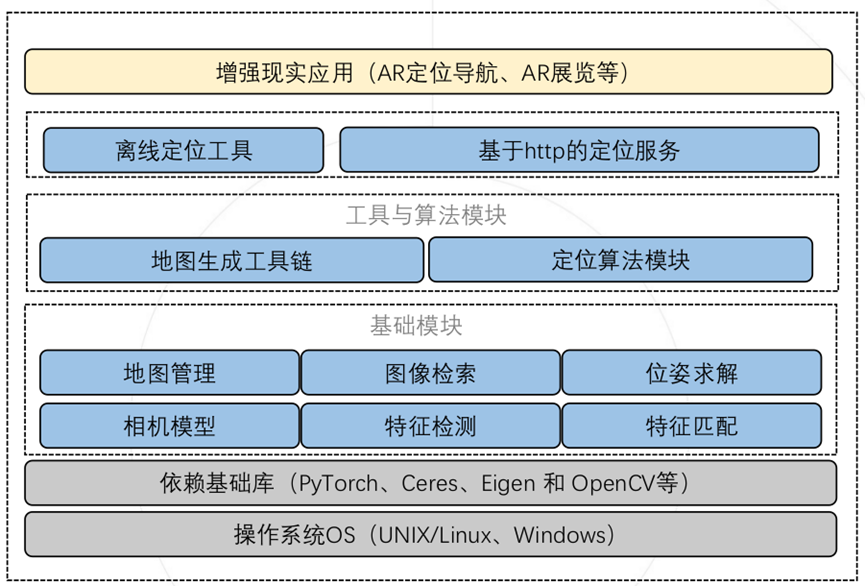
通过将定位过程中涉及的相关基础算法进行模块化封装,形成六个基础模块,分别为相机模型、特征检测、图像检索、特征匹配、位姿求解以及地图管理模块。各个模块之间相互解耦,并向上提供统一的接口。
相机模块支持了目前常用的相机模型。特征检测模块以统一的接口支持图像局部特征抽取和全局特征抽取,目前已经支持D2Net[2]特征和SuperPoint[3]特征,全局特征已经支持NetVLAD[4]特征。
特征匹配模块也以统一的接口支持2D-2D特征匹配和2D-3D特征匹配,包括最近邻匹配NN、针对2D-2D匹配的SuperGlue[5]和2D-3D匹配的GAM[6][7]。需要注意的是由于License的限制,SuperPoint和SuperGlue在代码仓库中没有直接支持,需要研究者根据提供的文档自己进行配置。
基于这些基础模块可以很方便地构建出一套完整的视觉定位流程。定位算法模块已经提供了一个层次视觉定位算法流程。如下图所示,给定定位图像和定位地图,算法依次执行特征检测、图像检索、共视搜索、特征匹配和位姿求解,从而获得相机的位姿。
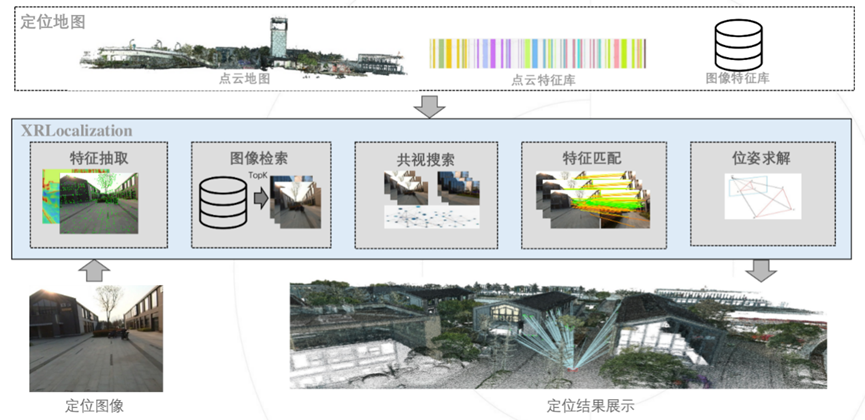
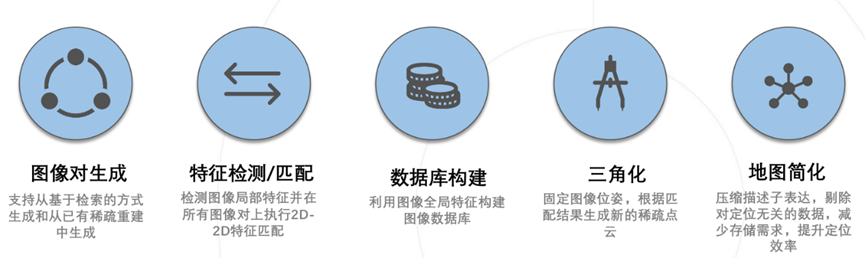
定位地图一般采用SfM或SLAM技术获得。通常情况下,由于定位的时间和建图时间存在差异,尤其室外场景往往面临着光照和季节变化等挑战,为了提高鲁棒性,定位时的特征通常采用表达能力更强的基于深度学习的特征,而常用的SfM多采用SIFT[8]特征。因此,需要将SfM模型转成定位需要用的地图。为了方便,我们基于基础模块提供的能力提供了一套地图生成工具链,方便用户进行不同特征地图的验证。
XRLocalization提供两种应用模式,一种是离线定位测试模式, 用于离线测试定位结果或用来测试Benchmark,评估模块算法性能;另一种是在线的定位服务,XRLocalizaiton作为一个服务端应用,在线监听客户端请求,并返回相机位姿,用于端云结合的XR应用。
XRLocalization支持使用json文件对算法的运行模式进行配置,如下图所示。譬如,我们可以通过配置mode参数选择是做2D-2D定位还是2D-3D定位;通过配置local_feature参数,选择使用不同的局部特征;通过配置matcher参数,选择不同的特征匹配方法。

为了让用户更方便地使用XRLocalization, 我们提供了完善的文档和教程,包括了如何配置环境,如何添加自己想要使用的特征,如何使用地图工具链生成定位地图,如何在benchmark上进行评测以及如何启动一个在线的定位服务等等。如果在配置环境出现了一些奇怪的问题,我们还提供了Dockerfile,可以直接构建docker镜像。
同时,我们也提供了已经构建好的docker镜像可以直接从仓库进行拉取:
另外,如果大家在使用XRLocalization过程中遇到任何问题,非常欢迎在github上提交issue,我们会尽力及时的帮助解决问题。同时也欢迎大家向仓库贡献代码,一起改进XRLocalization。
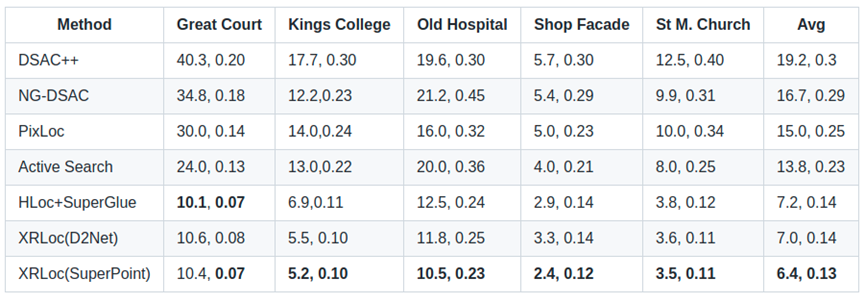
下表是XRLocalization在Cambridge Landmarks数据集[9]上与其他SOTA方法的评测结果,数据记录了定位的中位数误差,分别为位置误差(cm)和角度误差(°)。从结果可以看出,不管是和基于学习的直接回归场景坐标的方法,还是基于结构的方法比较,XRLocalization在精度上具有很大的领先性。不仅如此,XRLocalization的效率也要远高于当前的SOTA方法HLoc+SuperGlue[5],比其快6倍。
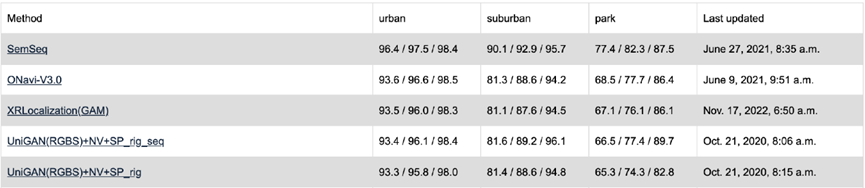
下面是XRlocalization在大规模长期视觉定位Benchmark[10]上的评测结果. 在两个数据集上XRLocalization均采用单相机进行定位,没有采用Rig方式。

下面是XRLocalization在室外数据上的定位结果展示,每张图像均是独立定位,没有使用时序上的信息。从定位结果可以看出,整体的轨迹非常平滑,且成功率很高,几乎所有的图像的位姿均被准确地求解出来。

下面是XRLocalization在室内办公场景的定位结果,在定位的结果上绘制了一些预先摆放的虚拟物体。和上面室外场景一样,这里的每张图像也是独立解算,可以看出,摆放的虚拟物体几乎没有抖动,体现了定位的高精度和高成功率。

视觉定位是当前较为活跃的一个研究领域,还有许多挑战需要研究者去攻破,譬如长期视觉定位等。XRLocalization提供了一个开放且易于扩展的框架平台,欢迎大家在此平台上进行二次开发。独木不成林,我们诚挚地邀请社区的小伙伴加入我们,让我们一同将XRLocalization打造成更加易用和强大的开源代码库。同时, 也欢迎小伙伴们以任何形式给我们提供宝贵的意见和建议~
1. 【CVPR2022 Oral】Manhattan-SDF:从多视角图像做三维场景重建
2. 书籍推荐-《基于深度学习的计算机视觉》
3. 书籍推荐 - 《基于C++的机器学习实操》
4. 书籍推荐 -《自主移动机器人导论》
5. 书籍推荐-《3D计算机视觉》
6. 三维局部描述子综述
