本文主要内容如下:
搜索引擎现在是用得越来越多了,比如我们日志系统中用到的 ELK 就用到了搜索引擎 Elasticsearch(简称 ES)。
那对于搜索这种技术来说,最看重的是搜索的结果的准确性和搜索的响应时间。ES 的准确性可以通过 倒排索引算法来保证,那响应时间就需要磁盘或缓存来支持了,那么磁盘和缓存会带来哪些坑呢? ( 其实不论是分布式的,还是单机模式下的搜索引擎都会遇到这个问题。 )
Elasticsearch 是现如今用的最广泛的搜索引擎。它是一个分布式的开源搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。
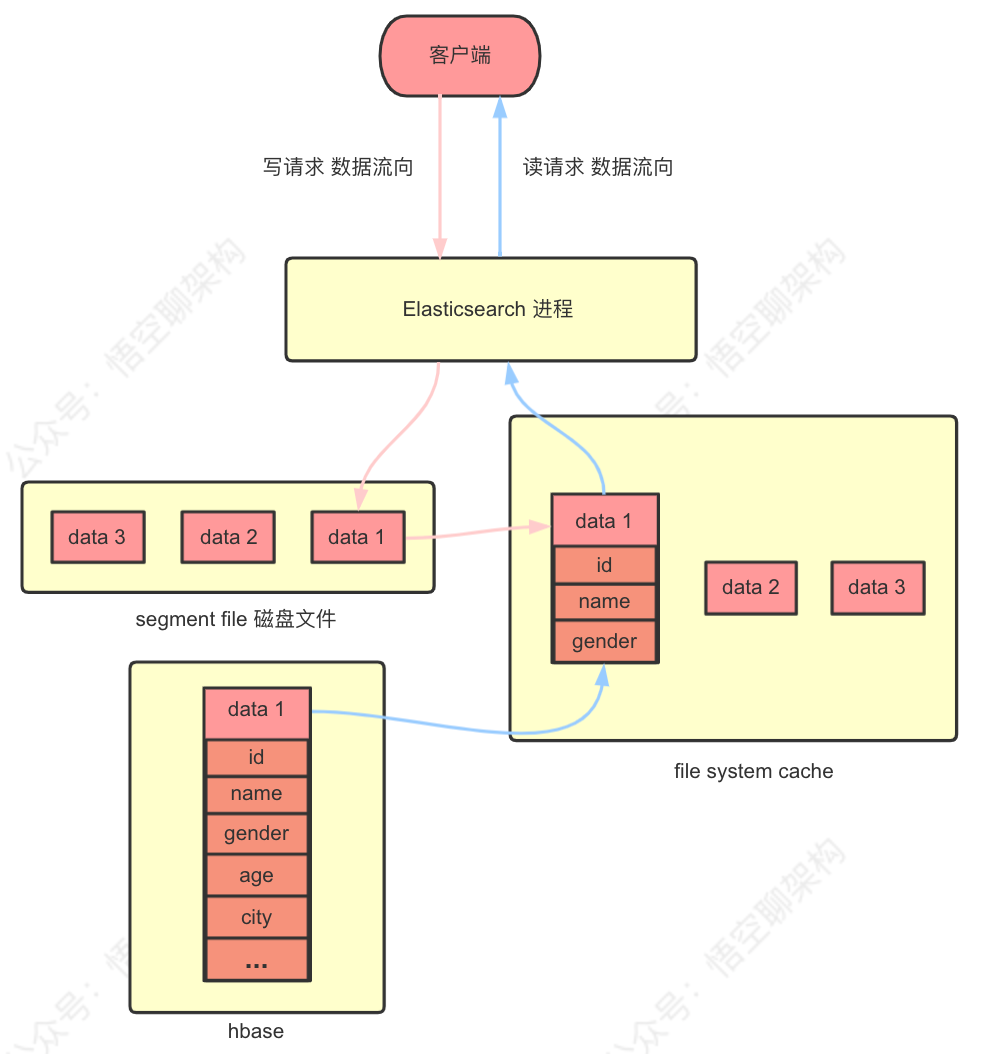
ES 的工作原理:往 ES 里写数据时,实际是写到磁盘文件,查询时,操作系统会将磁盘文件里的数据自动缓存 filesystem cache 里面。如果给 filesystem cache 更多的内存,尽量让内存可以容纳所有的 idx segment file 索引数据文件,则搜索的时候走内存,性能较好。
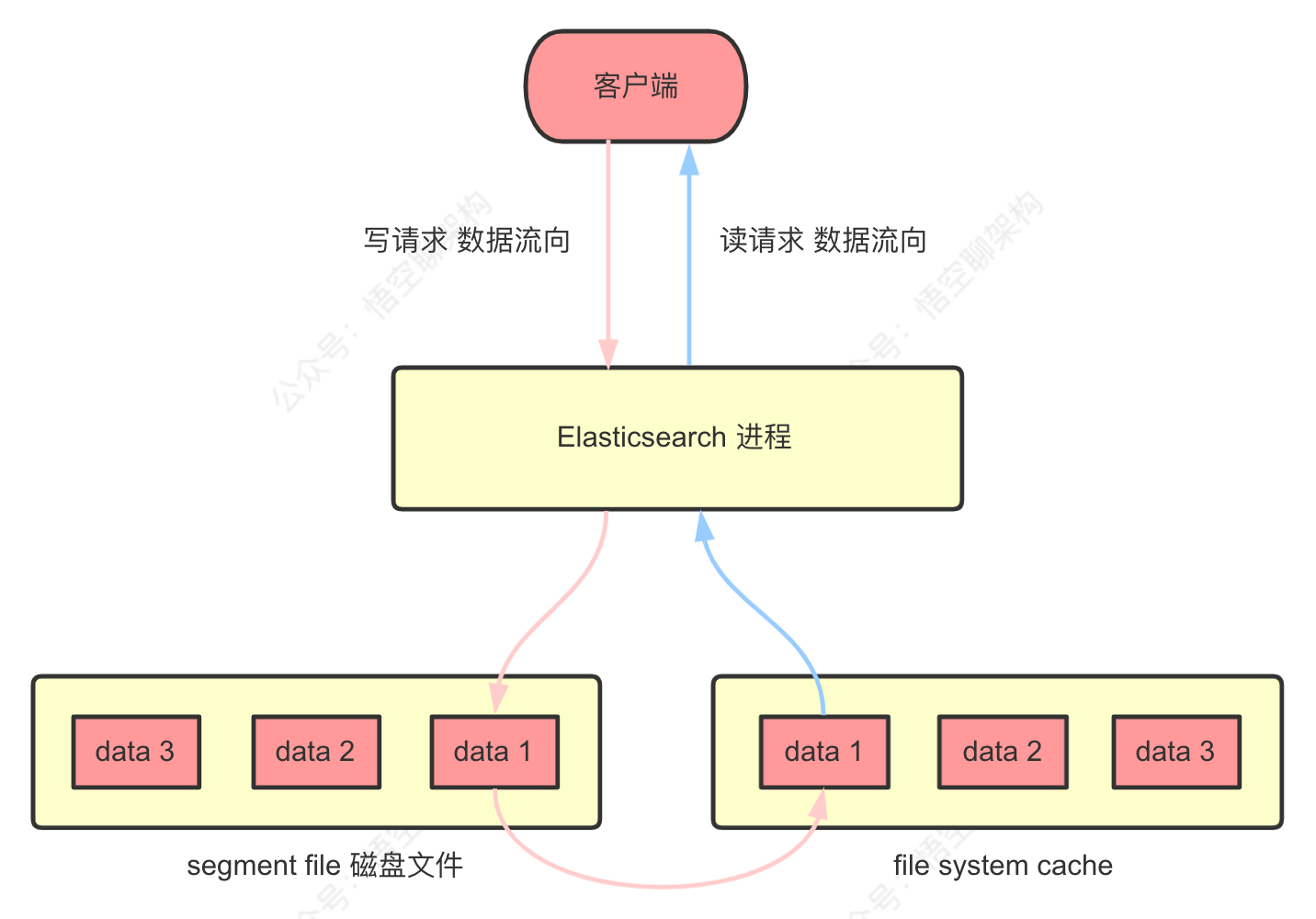
坑:首先如果访问磁盘那一定很慢,而走缓存会快很多。但如果很多没用的字段数据都丢到缓存里面,则会浪费缓存的空间,所以很多数据还是存在磁盘里面的,那么大部分查询走的数据库,则会带来性能问题。
ES 节点 3 台机器,每台机器 32 G 内存,总内存 96 G,给 ES JVM 堆内存是 16 G,那么剩下来给 cache 的是 16 G,总共 ES 集群的的 cache 占用内存 48 G ,如果所有的数据占据磁盘空间 600 G,那么每台机器的数据量是 200 G,而查询时,有 150 G 左右的的数据是走磁盘查询的,那么走 cache 的概率是 48 G/ 600 G = 8%,也就是说大量查询是走磁盘的。
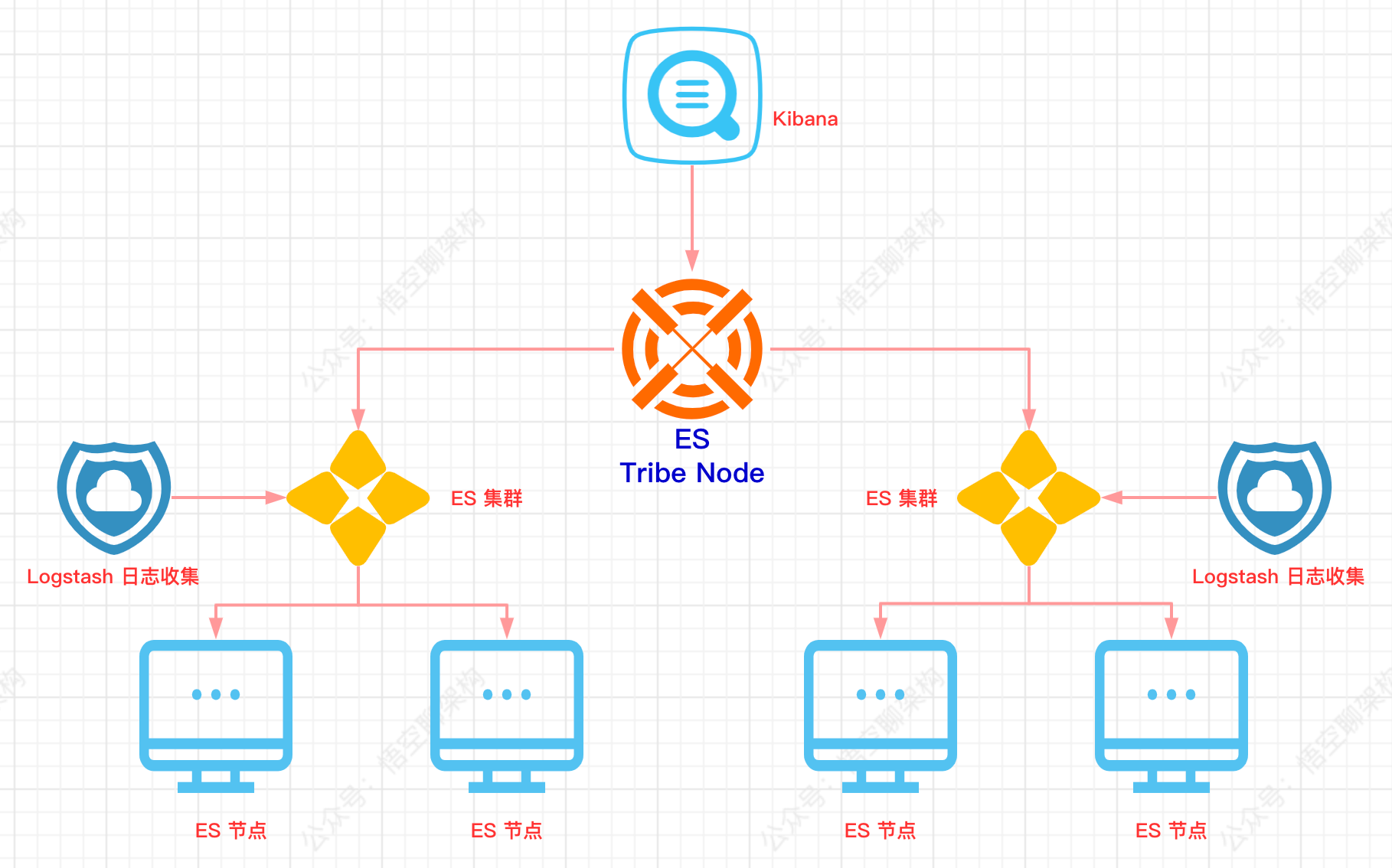
通常情况下,我们会使用 ES 的集群模式,在集群规模不大的情况下,性能还算可以,但如果集群规模变得很大,则会遇到集群瓶颈,也就是说集群扩大,性能提升甚微,甚至不增反降。
ES 的集群也是采用中心化的分布式架构,整个集群只有一个是 Master 节点。而它的职责非常重要:负责整个集群的元数据管理,元数据包含全局的配置信息、索引信息、节点信息,如果元数据发生改变,则需要 master 节点将变更信息发布到集群的其他节点。
另外因为 master 节点的任务处理是单线程的,所以每次处理任务时,需要等待全部节点接收到变更信息,并处理完变更的任务后,才算完成了变更任务。
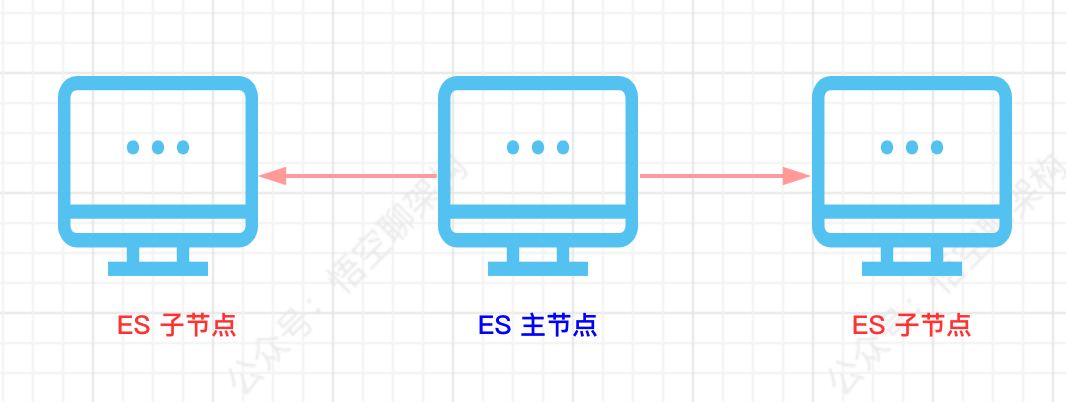
那么这样的架构会带来什么问题:
假死,比如 JVM 的内存爆了,但是进程还活着,那么响应 master 节点的时间会非常长,今而影响单个同步信息任务的完成时间。解决方案:采用 ES 的 tribe node 特性实现 ES 多集群。文中后面会介绍下 tribe node 的原理。
ES 的被广泛应用到多个场景,比如查询日志、查询商品资料、数据聚合等。而这些场景的需求又有非常大的差异,这也是一个坑。

解决方案:按业务场景划分 ES 集群,同样采用 ES tribe node 功能。
ES tribe node 功能原理图如下所示: