

TOC
// A Pool is a set of temporary objects that may be individually saved and retrieved.
一个sync.Pool是一组可以单独保存和检索的临时对象。
// Any item stored in the Pool may be removed automatically at any time without notification. If the Pool holds the only reference when this happens, the item might be deallocated.
存储在池中的任何项目可随时自动删除,无需通知。当池中只有一个引用的情况下,该项目可能会被释放。
A Pool is safe for use by multiple goroutines simultaneously.
一个池可以安全地同时被多个goroutine使用.【线程安全】
// Pool's purpose is to cache allocated but unused items for later reuse, relieving pressure on the garbage collector. That is, it makes it easy to
build efficient, thread-safe free lists. However, it is not suitable for all
free lists.
//池的目的是缓存已分配但未使用的项目,释放垃圾收集器上的压力。也就是说,这使得构建高效、线程安全的自由列表。然而,它不适用于所有自由列表。
An appropriate use of a Pool is to manage a group of temporary items silently shared among and potentially reused by concurrent independent clients of a package. Pool provides a way to amortize allocation overhead
across many clients.
池的一个适当用途是管理一组临时项,这些临时项在包的并发独立客户端之间默默共享,并可能被其重用。池提供了一种在许多客户机上分摊分配开销的方法
// An example of good use of a Pool is in the fmt package, which maintains a dynamically-sized store of temporary output buffers. The store scales under load (when many goroutines are actively printing) and shrinks when quiescent.
一个很好地使用池的例子是fmt包,它维护了临时输出缓冲区的动态大小存储。存储在高负载下缩放(当许多gorroutine正在主动打印时),在静止时缩小.
On the other hand, a free list maintained as part of a short-lived object is not a suitable use for a Pool, since the overhead does not amortize well in that scenario. It is more efficient to have such objects implement their own free list
另一方面,作为短生存周期对象的一部分维护的空闲列表不适合用于池,因为在这种情况下开销不会很好地摊销。让这样的对象实现自己的自由列表更有效
Pool 池的模式是通用型的(存储对象的类型为interface{}),所有的类型的对象都可以进行使用。注意的是,作为使用方不能对 Pool 里面的对象个数做假定,同时也无法获取 Pool 池中对象个数。
第一个步骤就是创建一个 Pool 实例,关键一点是配置 New 方法,声明 Pool 元素创建的方法。
var studentPool = sync.Pool{
New: func() interface{} {
return new(Student)
},
}stu := studentPool.Get().(*Student)
json.Unmarshal(buf, stu)
studentPool.Put(stu)
package syncPool
import (
"bytes"
"io/ioutil"
"sync"
"testing"
)
var pool = sync.Pool{
New: func() interface{} {
return new(bytes.Buffer)
},
}
var fileName = "test_sync_pool.log"
var data = make([]byte, 10000)
func BenchmarkWriteFile(b *testing.B) {
for n := 0; n < b.N; n++ {
buf := new(bytes.Buffer)
buf.Reset() // Reset 缓存区,不然会连接上次调用时保存在缓存区里的内容
buf.Write(data)
_ = ioutil.WriteFile(fileName, buf.Bytes(), 0644)
}
}
func BenchmarkWriteFileWithPool(b *testing.B) {
for n := 0; n < b.N; n++ {
buf := pool.Get().(*bytes.Buffer) // 如果是第一个调用,则创建一个缓冲区
buf.Reset() // Reset 缓存区,不然会连接上次调用时保存在缓存区里的内容
buf.Write(data)
_ = ioutil.WriteFile(fileName, buf.Bytes(), 0644)
pool.Put(buf) // 将缓冲区放回 sync.Pool中
}
}执行结果:
goos: darwin
goarch: amd64
pkg: test/utils/syncPool
cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
BenchmarkWriteFile-12 6405 180915 ns/op 10368 B/op 4 allocs/op
BenchmarkWriteFileWithPool-12 7274 183877 ns/op 128 B/op 3 allocs/op
PASS
ok test/utils/syncPool 3.031s可以看出,性能上并没有多大提升。但是内存消耗少了很多【 10368 B/op => 128 B/op 】 是因为: Pool中的对象,不会反复创建新对象,节省了内存的分配。
那为什么没有明显提升性能呢?
我们通过增加new(bytes.Buffer)的时间,来看看如果对象实例化比较费时的情况下,性能是否有明显的提升。
func newBytesBuffer() *bytes.Buffer {
time.Sleep(time.Millisecond) // 手动增加 1 ms的延迟
return new(bytes.Buffer)
}全部代码如下:
package syncPool
import (
"bytes"
"io/ioutil"
"sync"
"testing"
"time"
)
var pool = sync.Pool{
New: func() interface{} {
return newBytesBuffer()
},
}
var fileName = "test_sync_pool.log"
var data = make([]byte, 10000)
func newBytesBuffer() *bytes.Buffer {
time.Sleep(time.Millisecond)
return new(bytes.Buffer)
}
func BenchmarkWriteFile(b *testing.B) {
for n := 0; n < b.N; n++ {
buf := newBytesBuffer()
buf.Reset() // Reset 缓存区,不然会连接上次调用时保存在缓存区里的内容
buf.Write(data)
_ = ioutil.WriteFile(fileName, buf.Bytes(), 0644)
}
}
func BenchmarkWriteFileWithPool(b *testing.B) {
for n := 0; n < b.N; n++ {
buf := pool.Get().(*bytes.Buffer) // 如果是第一个调用,则创建一个缓冲区
buf.Reset() // Reset 缓存区,不然会连接上次调用时保存在缓存区里的内容
buf.Write(data)
_ = ioutil.WriteFile(fileName, buf.Bytes(), 0644)
pool.Put(buf) // 将缓冲区放回 sync.Pool中
}
}执行结果:
goos: darwin
goarch: amd64
pkg: test/utils/syncPool
cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
BenchmarkWriteFile-12 840 1539251 ns/op 10368 B/op 4 allocs/op
BenchmarkWriteFileWithPool-12 6866 174601 ns/op 129 B/op 3 allocs/op
PASS
ok test/utils/syncPool 3.951s可以很明显看出,时间消耗【 1539251 ns/op => 174601 ns/op 】有了明显的降低。
也就是说,如果创建一个对象比较耗时或者消耗内存的化,使用Pool的化,会明显提升性能和内存消耗。
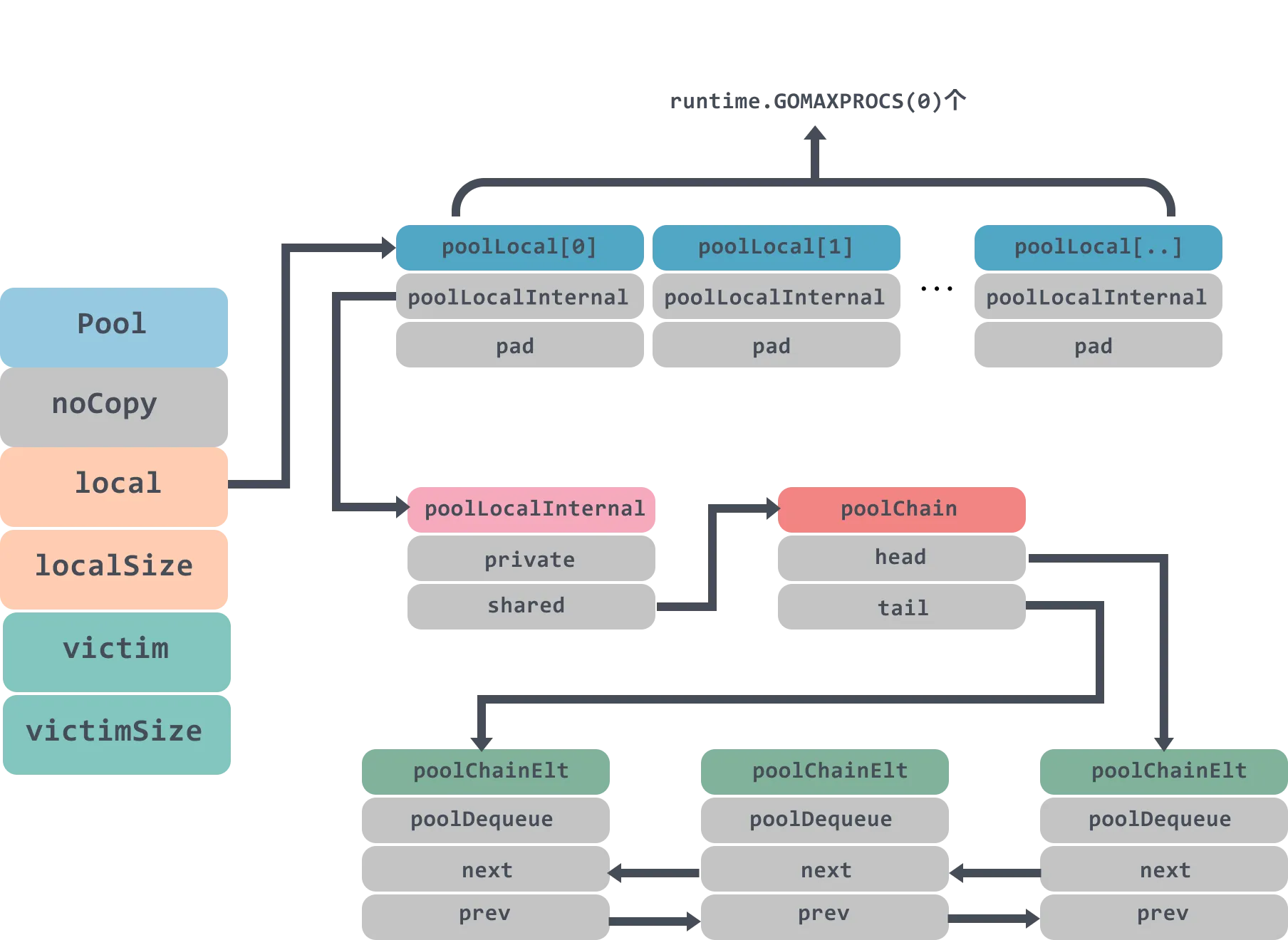
type Pool struct {
// 用于检测 Pool 池是否被 copy,因为 Pool 不希望被 copy。用这个字段可以在 go vet 工具中检测出被 copy(在编译期间就发现问题)
noCopy noCopy // A Pool must not be copied after first use.
// 实际指向 [P]poolLocal,数组大小等于 P 的数量;每个 P 一一对应一个 poolLocal
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal
localSize uintptr // size of the local array,[P]poolLocal 的大小
// GC 时,victim 和 victimSize 会分别接管 local 和 localSize;
// victim 的目的是为了减少 GC 后冷启动导致的性能抖动,让分配对象更平滑;
victim unsafe.Pointer
victimSize uintptr
// 对象初始化构造方法,使用方定义
New func() interface{}
}// 每个 P 都会有一个 poolLocal 的本地
type poolLocal struct {
poolLocalInternal
// Prevents false sharing on widespread platforms with
// 128 mod (cache line size) = 0 .
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
// Local per-P Pool appendix.
type poolLocalInternal struct {
private interface{}
shared poolChain
}poolLocalInternal 的定义,其中每个本地对象池,都会包含两项:
pad 从这个属性的定义方式来看,明显是为了凑齐了 128 Byte 的整数倍。为什么会这么做呢?
这里是为了避免 CPU Cache 的 false sharing 问题:
内存数据被 CPU 处理前会先读到 CPU Cache 中(L1、L2、L3),每次读取时是都按照一个 cache line 大小来读的。通常在 intel CPU 上 cache line 大小为 64 bytes,也存在一些 CPU 的 cache line 大小有所不同,譬如 128 bytes 等
在我们的场景中,各个 P 的 poolLocal 是以数组形式存在一起。假设 CPU Cache Line 为 128 byte,而 poolLocal 不足 128 byte 时,那 cacheline 将会带上其他 P 的 poolLocal 的内存数据,以凑齐一整个 Cache Line。如果这时,P 同时在两个不同的 CPU 核上运行,将会同时去覆盖刷新 CacheLine,造成 Cacheline 的反复失效。
从名字大概就可以猜出,poolChain 是个链表结构,且是双向链表。 每一个节点是 poolChainElt struct 对象。poolChainElt struct 中的 poolDequeue struct 是一段数组空间,类似于 ringbuffer,是一个无锁环形队列。Pool 池管理的对象存储在 poolDequeue 的 vals[] 数组里,即缓存对象存储在环形队列 poolDequeue 中
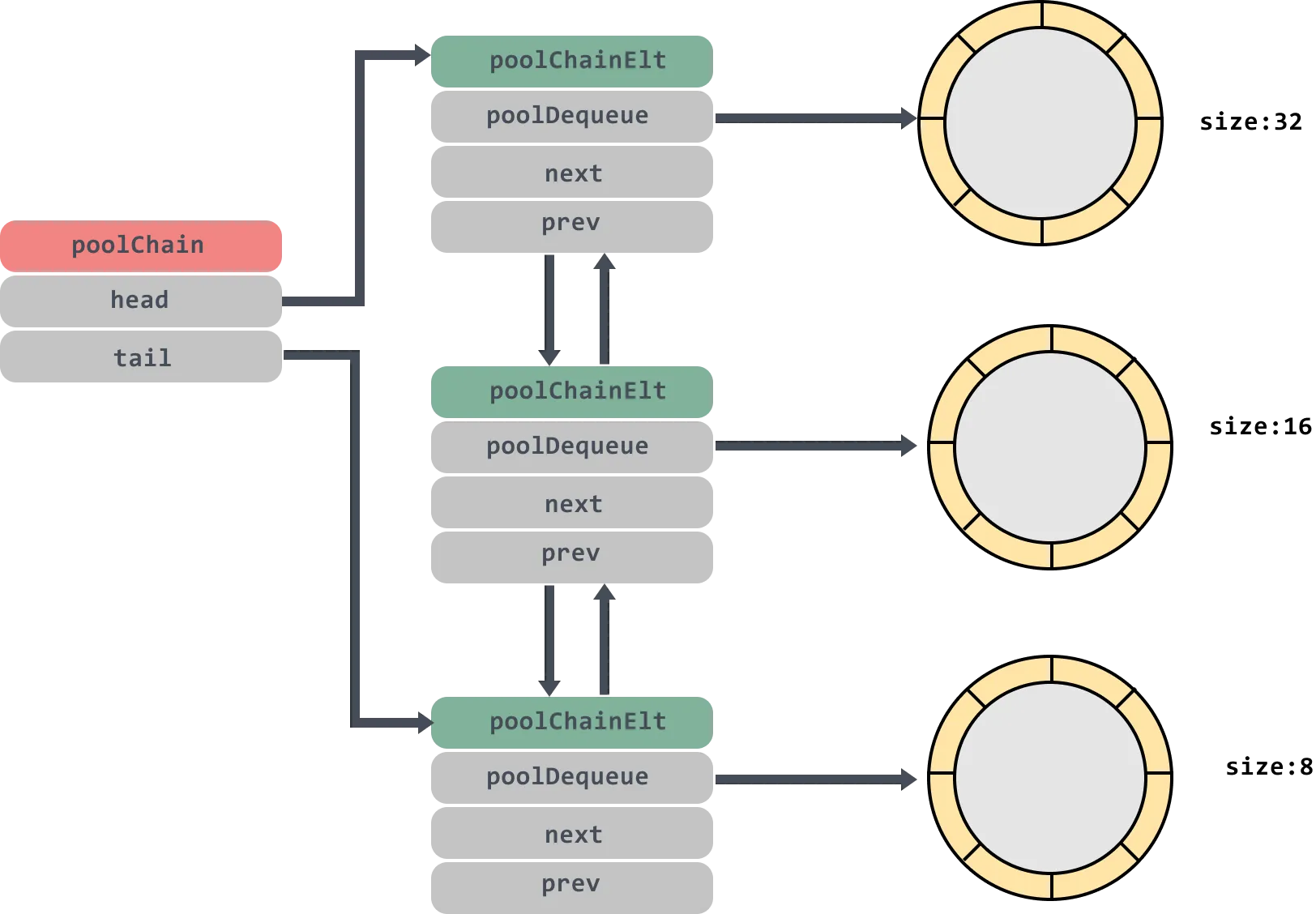
// poolChain is a dynamically-sized version of poolDequeue.
// poolChain是poolDequeue的动态大小版本
//
// This is implemented as a doubly-linked list queue of poolDequeues
// where each dequeue is double the size of the previous one. Once a
// dequeue fills up, this allocates a new one and only ever pushes to
// the latest dequeue. Pops happen from the other end of the list and
// once a dequeue is exhausted, it gets removed from the list.
// 这被实现为poolDequeues的双链接列表队列,其中每个队列的大小是前一个队列的两倍.
// 一旦一个退出队列填满,这将分配一个新的队列,并且只会推送到最新的退出队列.
// Pops发生在列表的另一端,一旦排完队,它就会从列表中删除。
// head is the poolDequeue to push to. This is only accessed
// by the producer, so doesn't need to be synchronized.
// head 是poolDequeue Push的地方。这只由生产者访问,因此不需要同步。
// tail is the poolDequeue to popTail from. This is accessed
// by consumers, so reads and writes must be atomic.
// tail是popTail的poolDequeue.这是由用户访问的,因此读写必须是原子的.
type poolChain struct {
head *poolChainElt
tail *poolChainElt
}
// next is written atomically by the producer and read
// atomically by the consumer. It only transitions from nil to
// non-nil.
//
// prev is written atomically by the consumer and read
// atomically by the producer. It only transitions from
// non-nil to nil.
// next由生产者原子地编写,由消费者原子地读取。它只从零过渡到非零
// prev由消费者原子地编写,由生产者原子地读取。它只从非零过渡到零。
type poolChainElt struct {
poolDequeue // 本质是个数组内存空间,管理成 ringbuffer 的模式;
next, prev *poolChainElt // 前向、后向指针
}
// poolDequeue is a lock-free fixed-size single-producer,
// multi-consumer queue. The single producer can both push and pop
// from the head, and consumers can pop from the tail.
// poolDequeue是一个无锁固定大小的单生产者、多消费者队列。单个生产者可以从头部推动和弹出,消费者可以从尾部弹出。
type poolDequeue struct {
headTail uint64 // 高32位为头部索引,低32位为尾部索引
vals []eface
}使用 ring buffer 是因为它有以下优点:
为什么headTail 变量将 head 和 tail 打包在了一起?
是为了实现lock free。对于一个 poolDequeue 来说,可能会被多个 P 同时访问就会出现并发问题。
例如: 当 ring buffer 空间仅剩一个的时候,即 head - tail = 1 。 如果多个 P 同时访问 ring buffer,在没有任何并发措施的情况下,两个 P 都可能会拿到对象, 这样就容易引起问题。
为了不引入Mutex锁,sync.Pool是使用 atomic 包中的 CAS 操作完成的.
atomic.CompareAndSwapUint64(&d.headTail, ptrs, ptrs2)在更新 head 和 tail 的时候,也是通过原子变量 + 位运算进行操作的。例如,当实现 head++ 的时候,需要通过以下代码实现:
const dequeueBits = 32
atomic.AddUint64(&d.headTail, 1<<dequeueBits)代码逻辑
func (c *poolChain) pushHead(val interface{}) {
d := c.head
// Initialize the chain.
if d == nil {
const initSize = 8 // 初始长度为8
d = new(poolChainElt)
d.vals = make([]eface, initSize)
c.head = d
storePoolChainElt(&c.tail, d)
}
if d.pushHead(val) {
return
}
// The current dequeue is full. Allocate a new one of twice the size.
// 当前的dequeue已经满了,创建一个两倍空间的新的链表节点,最大值为(1<<32)/4 = 1073741824
newSize := len(d.vals) * 2
if newSize >= dequeueLimit { // Can't make it any bigger.
newSize = dequeueLimit
}
// 拼接链表
d2 := &poolChainElt{prev: d}
d2.vals = make([]eface, newSize)
c.head = d2
storePoolChainElt(&d.next, d2)
d2.pushHead(val)
}
func (d *poolDequeue) pushHead(val interface{}) bool {
ptrs := atomic.LoadUint64(&d.headTail)
head, tail := d.unpack(ptrs)
// Ring式队列,头尾相等则队列已满
if (tail+uint32(len(d.vals)))&(1<<dequeueBits-1) == head {
return false
}
slot := &d.vals[head&uint32(len(d.vals)-1)]
// Check if the head slot has been released by popTail.
typ := atomic.LoadPointer(&slot.typ)
if typ != nil {
// Another goroutine is still cleaning up the tail, so
// the queue is actually still full.
return false
}
// The head slot is free, so we own it.
if val == nil {
val = dequeueNil(nil)
}
*(*interface{})(unsafe.Pointer(slot)) = val
// Increment head. This passes ownership of slot to popTail
// and acts as a store barrier for writing the slot.
atomic.AddUint64(&d.headTail, 1<<dequeueBits)
return true
}代码逻辑
func (c *poolChain) popHead() (interface{}, bool) {
d := c.head
for d != nil {
if val, ok := d.popHead(); ok {
return val, ok
}
// There may still be unconsumed elements in the previous dequeue, so try backing up.
d = loadPoolChainElt(&d.prev)
}
return nil, false
}
func (d *poolDequeue) popHead() (interface{}, bool) {
var slot *eface
for {
ptrs := atomic.LoadUint64(&d.headTail)
head, tail := d.unpack(ptrs)
// 判断队列是否为空
if tail == head {
return nil, false
}
head-- // head位置是队头的前一个位置,所以此处要先退一位
ptrs2 := d.pack(head, tail) // 新的 headTail 值
// 通过 CAS 判断当前没有并发修改就拿到数据
if atomic.CompareAndSwapUint64(&d.headTail, ptrs, ptrs2) {
slot = &d.vals[head&uint32(len(d.vals)-1)]
break
}
}
// 取出数据
val := *(*interface{})(unsafe.Pointer(slot))
if val == dequeueNil(nil) {
val = nil
}
// 重置slot,typ和val均为nil
*slot = eface{}
return val, true
}代码逻辑
func (c *poolChain) popTail() (any, bool) {
d := loadPoolChainElt(&c.tail)
if d == nil {
return nil, false
}
for {
d2 := loadPoolChainElt(&d.next)
if val, ok := d.popTail(); ok {
return val, ok
}
if d2 == nil {
return nil, false
}
// 将c.tail指向d2,指针前移实现链表收缩
if atomic.CompareAndSwapPointer((*unsafe.Pointer)(unsafe.Pointer(&c.tail)), unsafe.Pointer(d), unsafe.Pointer(d2)) {
storePoolChainElt(&d2.prev, nil)
}
d = d2
}
}
代码逻辑
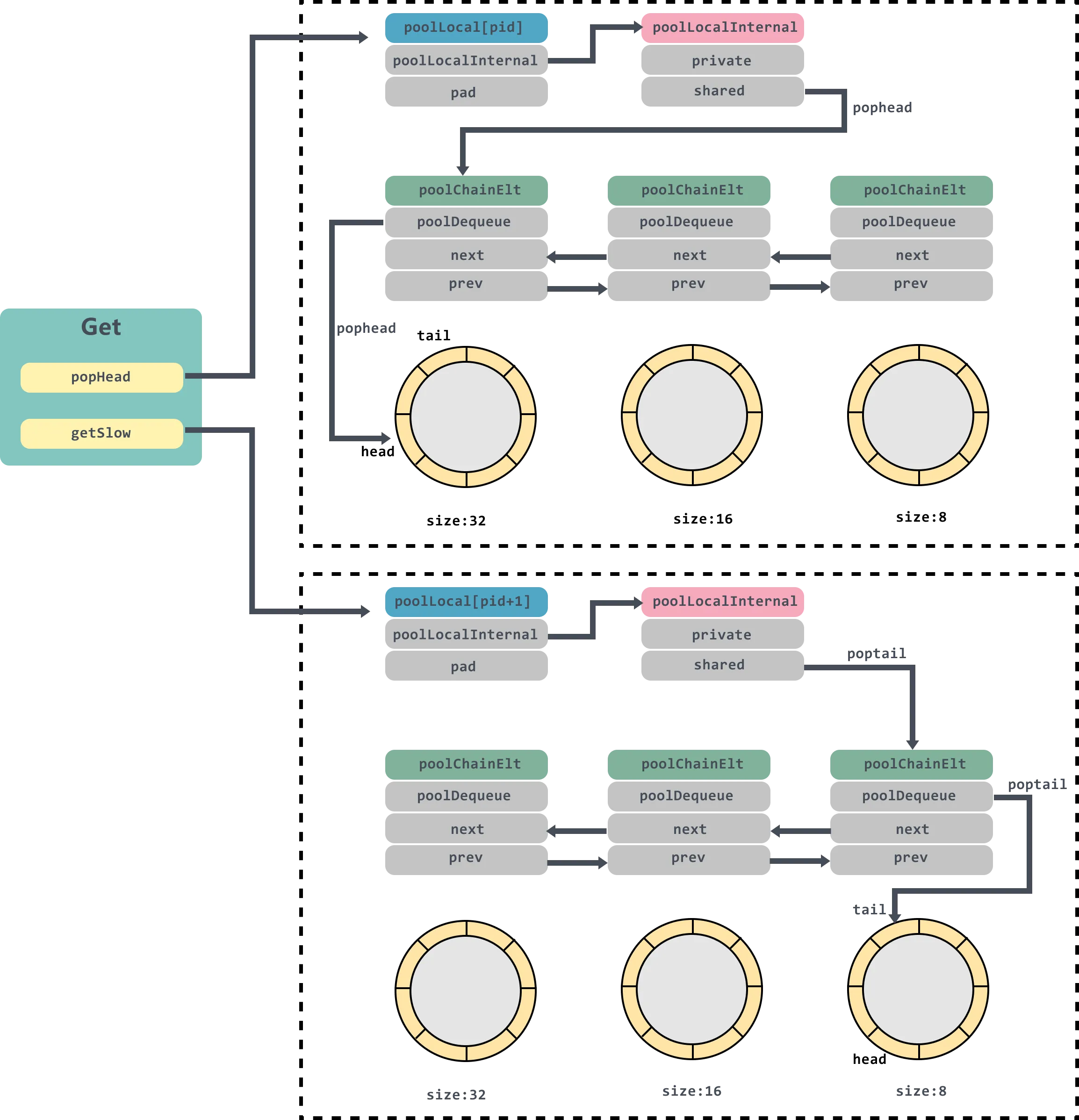
func (p *Pool) Get() interface{} {
if race.Enabled {
race.Disable()
}
// 把当前的goroutine固定在当前的P上,返回当前的P上的*poolLocal
l, pid := p.pin()
// 先从本地local的private字段获取元素,此private只能被当前的P访问
// 其他P是不能访问的,一个P同一时间只能有1个goroutine在运行,所以
// 直接访问l.private并不需要加锁
x := l.private
l.private = nil
// private中没有元素
if x == nil {
// 从当前的本地local.shared中头部出队一个元素。
x, _ = l.shared.popHead()
if x == nil {
// 如果从local.shared也没有拿到,则从其他P中的l.shared中偷1个
// 如果shared中也没有,产生从victim中获取
x = p.getSlow(pid)
}
}
// G-M 锁定解除;上锁的逻辑在 pin() 中
runtime_procUnpin()
if race.Enabled {
race.Enable()
if x != nil {
race.Acquire(poolRaceAddr(x))
}
}
// 走到这里说明,private, local.shared, 其他P中的local.shared, 本地local.victim,
// 其他P中的local.victim都没有缓存了,如果设置New函数,调用New函数创建一个元素返回
if x == nil && p.New != nil {
x = p.New()
}
// 走到这里说明没有设置New函数,返回nil
return x
}代码逻辑
Pool.pin() 函数中如果
Processor.ID小于Pool.localSize(如果大于,其实就是localSize=0、Pool 实例未初始化),就返回Pool.local数组中的第Processor.ID个元素和Processor.ID。 而Pool.local数组大小就是P的数量
代码逻辑
为什么解除pin后重新加pin?
llPoolsMu一个全局Mutex锁, 上锁会比较慢可能被阻塞
为什么要重新检查pid和localSize?
在解除绑定后,pinSlow 可能被其他的线程调用过了,p.local 可能会发生变化。因此这时候需要再次对 pid 进行检查
func (p *Pool) pinSlow() (*poolLocal, int) {
// 解除pin
runtime_procUnpin()
// 加上全局锁
allPoolsMu.Lock()
defer allPoolsMu.Unlock()
// pin住
pid := runtime_procPin()
s := p.localSize
l := p.local
// 重新对pid进行检查
if uintptr(pid) < s {
return indexLocal(l, pid), pid
}
// 初始化local前会将pool放入到allPools数组中
if p.local == nil {
allPools = append(allPools, p)
}
// 当前P的数量
size := runtime.GOMAXPROCS(0)
local := make([]poolLocal, size)
atomic.StorePointer(&p.local, unsafe.Pointer(&local[0]))
atomic.StoreUintptr(&p.localSize, uintptr(size))
return &local[pid], pid
}代码逻辑
什么是victim?
victim 是上一轮被清理的对象池, 从 victim 取对象也是 popTail 的方式.
func (p *Pool) getSlow(pid int) interface{} {
size := atomic.LoadUintptr(&p.localSize) // load-acquire
locals := p.local // load-consume
// 遍历locals列表,从其他的local的shared列表尾部获取对象
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i+1)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
size = atomic.LoadUintptr(&p.victimSize)
if uintptr(pid) >= size {
return nil
}
locals = p.victim
l := indexLocal(locals, pid)
// victim的private不为空则返回
if x := l.private; x != nil {
l.private = nil
return x
}
// 遍历victim对应的locals列表,从其他的local的shared列表尾部获取对象
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// 获取不到,将victimSize置为0
atomic.StoreUintptr(&p.victimSize, 0)
return nil
}Put 就是将缓存对象放入当前 P 对应的数据桶中,它也有渐进的逻辑:优先将变量放入 private 区中,对应的在 Get 时会先取这个位置上的对象;private 区如果已经被占用了,就放入 shared 双向链表中。
代码逻辑
func (p *Pool) Put(x interface{}) {
if x == nil {
return
}
if race.Enabled {
if fastrand()%4 == 0 { // Randomly drop x on floor.
return
}
race.ReleaseMerge(poolRaceAddr(x))
race.Disable()
}
// 初始化;禁用抢占; 获取对应的 poolLocal(poolLocalInternal) 对象
l, _ := p.pin()
// 尝试放到最快的位置,这个位置也跟 Get 请求的顺序是一一对应的;
if l.private == nil {
l.private = x
x = nil
}
if x != nil { // 复用 x 变量来控制逻辑
l.shared.pushHead(x) // 放到 shared 双向链表中
}
runtime_procUnpin() // G-M 锁定解除,pin中有加锁
if race.Enabled {
race.Enable()
}
}Golang 的 runtime 将会在 每轮 GC 前,触发调用 poolCleanup 函数。
代码逻辑
func poolCleanup() {
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
oldPools, allPools = allPools, nil
}某一时刻 P 只会调度一个 G。
目的是避免获取不到全局锁 allPoolsMu 却一直占用当前 P 的情况。而 runtime_procUnpin 和 runtime_procPin 之间,本 G 可能已经切换到其他 P 上,而 []poolLocal 也可能已经被初始化。
因为 copy 后,对于同一个 Pool 实例中的 cache 对象,就有了两个指向来源。原 Pool 清空之后,copy 的 Pool 没有清理掉,那么里面的对象就全都泄露了。并且 Pool 的无锁设计的基础是多个 Goroutine 不会操作到同一个数据结构,Pool 拷贝之后则不能保证这点(因为存储的成员都是指针)。
Go sync.Pool 保姆级教程
