注意:请文明上网,本文仅作为学习用。讲述的是思路和方法,所以对被测试网站关键数据进行隐藏。如有需要,可学习思路后自行找测试对象进行学习。


根据以上【需求细节】,我们已经大概明白需要做啥,就是要下载一个大的分类下的小类中的内容:
requests.get方法;etree.HTML和tree.xpath方法;a标签,那么需要使用BeautifulSoup进行页面解析;html格式的文件中,那我们要用到基本的数据写入,比如open和write方法;html原格式保存到excel中,那需要对html和excel格式进行解析,需要使用pandas进行处理;Path方法;Pyinstaller处理。工具 | 版本 | 用途 |
|---|---|---|
| V3.7.0 | 脚本设计 |
| V4.11.1 | html页面数据解析 |
| V4.6.3 |
|
| V1.1.5 | excel数据处理 |
| V2.24.0 | 页面数据请求 |
requirements.txt,直接使用pip install -r requirements.txt即可安装需要的包;beautifulsoup4==4.11.1
lxml==4.6.3
pandas==1.1.5
requests==2.24.0import requests
from lxml import etree
from bs4 import BeautifulSoup
import pandas
import os
import time
from pathlib import Pathclass Tools(object):
"""公共方法(工具)作为基类被后续调用""" def get_category(self,
curt_url,
curt_xpath,
curt_list,
curt_headers):
"""
请求方法封装
:param curt_url: 请求地址
:param curt_xpath: 对应table xpath
:param curt_list: 存放列表
:param curt_headers: 请求头
:return: 无返回
"""time.sleep(1),避免请求太过频繁;requests.get方法,获取目标地址数据,其中要加入两个参数,主要避免请求报SSl错误:res = requests.get(curt_url,
verify=False,
headers=curt_headers) etree.HTML方法返回的数据进行html转换:tree = etree.HTML(res.content) tree.xpath方法获取该页面中指定元素的内容:div = tree.xpath(curt_xpath) div_str = etree.tostring(div[0])
div_str1 = str(div_str, "UTF-8") BeautifulSoup方法解析页面html,获取a标签的所有链接内容,就是大类或小类的名字对应的链接了;soup = BeautifulSoup(div_str1)
for k in soup.find_all('a'):
curt_list.append(k['href']) get_category方法源码: def get_category(self,
curt_url,
curt_xpath,
curt_list,
curt_headers):
"""
请求方法封装
:param curt_url: 请求地址
:param curt_xpath: 对应table xpath
:param curt_list: 存放列表
:param curt_headers: 请求头
:return: 无返回
"""
time.sleep(1)
res = requests.get(curt_url,
verify=False,
headers=curt_headers) # 接口数据请求方法
tree = etree.HTML(res.content) # 获取返回数据的内容
div = tree.xpath(curt_xpath) # 获取当前页面需要的table xpath对应的内容
div_str = etree.tostring(div[0]) # 格式转换
div_str1 = str(div_str, "UTF-8") # byte转为str
# print(div_str1)
soup = BeautifulSoup(div_str1) # BeautifulSoup解析页面html
for k in soup.find_all('a'): # 获取a标签
curt_list.append(k['href']) def write_html(self, file, txt):
"""
公共方法:把获取的数据写入文本内容到文件【html格式】
:param file: 文件名
:param txt: 文本内容
:return: 返回成功或失败
"""
try:
with open(file, 'w', encoding='utf-8') as f:
f.write(txt)
time.sleep(3)
f.close()
return f"{file}写入: 成功"
except:
return f"{file}写入: 失败" def html_to_excel(self,
base_dir,
big_dir,
small_dir,
full_path,
new_file_path):
"""
将html文件转换成excel格式的文件
:param base_dir: 文件存放基地址,默认脚本的上一层目录
:param big_dir: 大类目录
:param small_dir: 小类目录
:param excel_dir: 存放excel目录
:param sheet_n: 存放sheet的名称=小类
:param full_path: 所有sheet合并目录
:param new_file_path: 最终合并的某个小类的excel
:return:无返回
"""①打开指定目录下的html格式文件; ②循环遍历所有的html格式文件,使用pandas.read_html进行数据读取; ③使用pandas.ExcelWriter方法写入excel; ④写入excel后是每个html存放在每个sheet中; ⑤合并所有的sheet为一个excel。
def html_to_excel(self,
base_dir,
big_dir,
small_dir,
full_path,
new_file_path):
"""
将html文件转换成excel格式的文件
:param base_dir: 文件存放基地址,默认脚本的上一层目录
:param big_dir: 大类目录
:param small_dir: 小类目录
:param excel_dir: 存放excel目录
:param sheet_n: 存放sheet的名称=小类
:param full_path: 所有sheet合并目录
:param new_file_path: 最终合并的某个小类的excel
:return:无返回
"""
excel_dir = base_dir + "\\" + big_dir + "\\" + small_dir + "\\"
sheet_n = small_dir
# sheet_n = "1-陶瓷电容器"
os.chdir(excel_dir)
for filename in os.listdir(excel_dir):
print(filename)
try:
with open(excel_dir + filename, 'rb') as f:
df = pandas.read_html(f.read(), header=1, encoding='utf-8')
bb = pandas.ExcelWriter(excel_dir + filename + ".xlsx")
df[0].to_excel(bb, index=False)
bb.close()
except Exception as e:
print("异常:" + e)
time.sleep(3)
workbook = pandas.ExcelWriter(full_path)
folder_path = Path(excel_dir)
file_list = folder_path.glob('*.xlsx*')
for i in file_list:
stem_name = i.stem
data = pandas.read_excel(i, sheet_name=0)
data.to_excel(workbook, sheet_name=stem_name, index=False)
time.sleep(2)
workbook.save()
workbook.close()
time.sleep(2)
data2 = pandas.read_excel(full_path, sheet_name=None)
data3 = pandas.concat(data2, ignore_index=True)
# new_file_path = "合并.xlsx"
data3.to_excel(new_file_path, sheet_name=sheet_n, index=False)category_list = [] # 存放所有大类
category_list_small = [] # 存放所有小类 def __init__(self):
# self.tools = Tools()
self.url = 'xxxx' # 目标网站
self.headers = {'Connection': 'close'} # 请求头,避免ssl报错
# self.big_num = 3 # 第几个大类,从0开始
# self.small_num = 0 # 第几个小类,从0开始
self.net_xpath = '/html/body/div[5]/div/div[2]' # 网站所有大类的table xpath
self.xpath_big = ['/html/body/div[3]/div[2]'] # 对应大类中的小类的table xpath
self.xpath_small = ['/html/body/div[4]/div'] # 对应小类的内容table xpath def get_big_category(self):
"""获取网站中所有的类别,存放列表中"""
self.get_category(self.url,
self.net_xpath,
category_list,
self.headers)
print(f"1========={category_list}") def get_small_category(self, big_num):
"""获取某个大类中小类所有的类别,存放列表中"""
self.get_category(f'{self.url}{category_list[big_num]}',
self.xpath_big[0],
category_list_small,
self.headers)
print(f"获取的大类是: {category_list[big_num]} ,如下:") def get_small_content(self, i, small_num):
"""获取小类中所有内容"""
print(f"获取的大类对应的小类是:{category_list_small[small_num]}")
time.sleep(1)
url_1 = f'{self.url}{category_list_small[small_num]}?page={i}'
print(f"请求的小类的域名为:{url_1}")
res = requests.get(url_1, verify=False, headers=self.headers)
tree = etree.HTML(res.content)
div = tree.xpath(self.xpath_small[0])
div_str = etree.tostring(div[0])
div_str1 = str(div_str, "UTF-8")
time.sleep(2)
return div_str1def main():
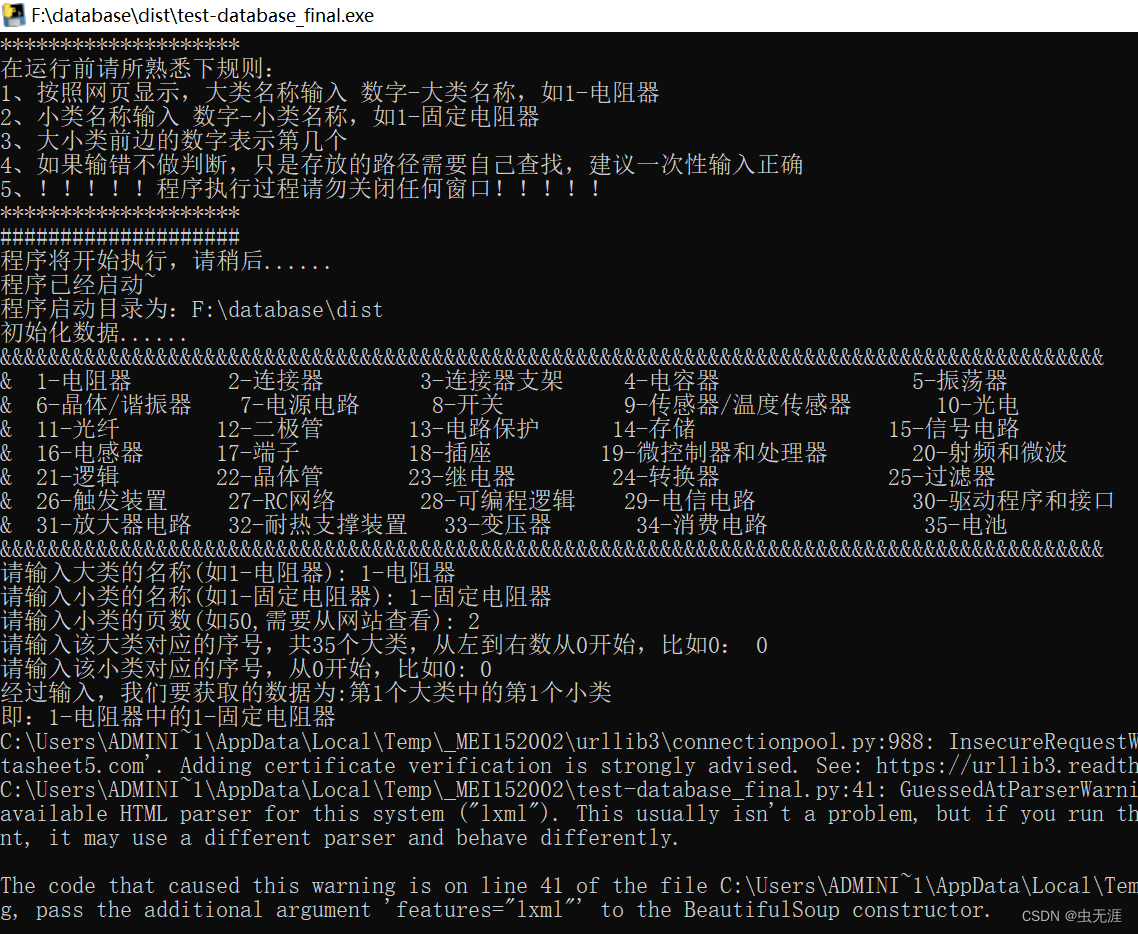
print("*" * 20)
print("在运行前请所熟悉下规则:\n"
"1、按照网页显示,大类名称输入 数字-大类名称,如1-电阻器\n"
"2、小类名称输入 数字-小类名称,如1-固定电阻器\n"
"3、大小类前边的数字表示第几个\n"
"4、如果输错不做判断,只是存放的路径需要自己查找,建议一次性输入正确\n"
"5、!!!!!程序执行过程请勿关闭任何窗口!!!!!")
print("*" * 20) base_file = os.path.dirname(os.path.abspath("test_database_final.py"))
print("#" * 20)
print("程序将开始执行,请稍后......\n"
"程序已经启动~\n"
f"程序启动目录为:{base_file}\n"
"初始化数据......")
print("&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&\n"
"1-电阻器 2-连接器 3-连接器支架 4-电容器 5-振荡器 \n"
"6-晶体/谐振器 7-电源电路 8-开关 9-传感器/温度传感器 10-光电 \n"
"11-光纤 12-二极管 13-电路保护 14-存储 15-信号电路 \n"
"16-电感器 17-端子 18-插座 19-微控制器和处理器 20-射频和微波 \n"
"21-逻辑 22-晶体管 23-继电器 24-转换器 25-过滤器 \n"
"26-触发装置 27-RC网络 28-可编程逻辑 29-电信电路 30-驱动程序和接口 \n"
"31-放大器电路 32-耐热支撑装置 33-变压器 34-消费电路 35-电池 \n"
"&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&") big = input("请输入大类的名称(如1-电阻器): ")
small = input("请输入小类的名称(如1-固定电阻器): ")
num = int(input("请输入小类的页数(如50,需要从网站查看): "))
b_n = int(input("请输入该大类对应的序号,共35个大类,从左到右数从0开始,比如0: "))
m_n = int(input("请输入该小类对应的序号,从0开始,比如0: "))
print(f"经过输入,我们要获取的数据为:第{b_n + 1}个大类中的第{m_n + 1}个小类\n"
f"即:{big}中的{small}") data_base = DataBase()
data_base.get_big_category()
data_base.get_small_category(b_n) for i in range(1, num+1):
get_content = data_base.get_small_content(i, m_n)
print(f"第{i}次获取:获取的数据开始写入文件,文件名为:第{i}页.html")
file = f"{base_file}\\{big}\\{small}"
if os.path.exists(file) is False:
os.makedirs(file)
data_base.write_html(file=f"{file}\\第{i}页.html",
txt=get_content)
time.sleep(1) data_base.html_to_excel(base_file,
big,
small,
f"{small}sheet.xlsx",
f"{small}.xlsx")def main():
print("*" * 20)
print("在运行前请所熟悉下规则:\n"
"1、按照网页显示,大类名称输入 数字-大类名称,如1-电阻器\n"
"2、小类名称输入 数字-小类名称,如1-固定电阻器\n"
"3、大小类前边的数字表示第几个\n"
"4、如果输错不做判断,只是存放的路径需要自己查找,建议一次性输入正确\n"
"5、!!!!!程序执行过程请勿关闭任何窗口!!!!!")
print("*" * 20)
base_file = os.path.dirname(os.path.abspath("test_database_final.py"))
print("#" * 20)
print("程序将开始执行,请稍后......\n"
"程序已经启动~\n"
f"程序启动目录为:{base_file}\n"
"初始化数据......")
print("&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&\n"
"1-电阻器 2-连接器 3-连接器支架 4-电容器 5-振荡器 \n"
"6-晶体/谐振器 7-电源电路 8-开关 9-传感器/温度传感器 10-光电 \n"
"11-光纤 12-二极管 13-电路保护 14-存储 15-信号电路 \n"
"16-电感器 17-端子 18-插座 19-微控制器和处理器 20-射频和微波 \n"
"21-逻辑 22-晶体管 23-继电器 24-转换器 25-过滤器 \n"
"26-触发装置 27-RC网络 28-可编程逻辑 29-电信电路 30-驱动程序和接口 \n"
"31-放大器电路 32-耐热支撑装置 33-变压器 34-消费电路 35-电池 \n"
"&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&")
big = input("请输入大类的名称(如1-电阻器): ")
small = input("请输入小类的名称(如1-固定电阻器): ")
num = int(input("请输入小类的页数(如50,需要从网站查看): "))
b_n = int(input("请输入该大类对应的序号,共35个大类,从左到右数从0开始,比如0: "))
m_n = int(input("请输入该小类对应的序号,从0开始,比如0: "))
print(f"经过输入,我们要获取的数据为:第{b_n + 1}个大类中的第{m_n + 1}个小类\n"
f"即:{big}中的{small}")
data_base = DataBase()
data_base.get_big_category()
data_base.get_small_category(b_n)
for i in range(1, num+1):
get_content = data_base.get_small_content(i, m_n)
print(f"第{i}次获取:获取的数据开始写入文件,文件名为:第{i}页.html")
file = f"{base_file}\\{big}\\{small}"
if os.path.exists(file) is False:
os.makedirs(file)
data_base.write_html(file=f"{file}\\第{i}页.html",
txt=get_content)
time.sleep(1)
data_base.html_to_excel(base_file,
big,
small,
f"{small}sheet.xlsx",
f"{small}.xlsx")if __name__ == "__main__":
main()
input('Press Enter to exit…')# -*- coding:utf-8 -*-
# 作者:NoamaNelson
# 日期:2022/10/11
# 文件名称:test_database_final.py
# 作用:xxx
# 博客:https://blog.csdn.net/NoamaNelson
import requests
from lxml import etree
from bs4 import BeautifulSoup
import pandas
import os
import time
from pathlib import Path
class Tools(object):
"""公共方法(工具)作为基类被后续调用"""
def get_category(self,
curt_url,
curt_xpath,
curt_list,
curt_headers):
"""
请求方法封装
:param curt_url: 请求地址
:param curt_xpath: 对应table xpath
:param curt_list: 存放列表
:param curt_headers: 请求头
:return: 无返回
"""
time.sleep(1)
res = requests.get(curt_url,
verify=False,
headers=curt_headers) # 接口数据请求方法
tree = etree.HTML(res.content) # 获取返回数据的内容
div = tree.xpath(curt_xpath) # 获取当前页面需要的table xpath对应的内容
div_str = etree.tostring(div[0]) # 格式转换
div_str1 = str(div_str, "UTF-8") # byte转为str
# print(div_str1)
soup = BeautifulSoup(div_str1) # BeautifulSoup解析页面html
for k in soup.find_all('a'): # 获取a标签
curt_list.append(k['href']) # 循环获取href链接
def write_html(self, file, txt):
"""
公共方法:把获取的数据写入文本内容到文件【html格式】
:param file: 文件名
:param txt: 文本内容
:return: 返回成功或失败
"""
try:
with open(file, 'w', encoding='utf-8') as f:
f.write(txt)
time.sleep(3)
f.close()
return f"{file}写入: 成功"
except:
return f"{file}写入: 失败"
def html_to_excel(self,
base_dir,
big_dir,
small_dir,
full_path,
new_file_path):
"""
将html文件转换成excel格式的文件
:param base_dir: 文件存放基地址,默认脚本的上一层目录
:param big_dir: 大类目录
:param small_dir: 小类目录
:param excel_dir: 存放excel目录
:param sheet_n: 存放sheet的名称=小类
:param full_path: 所有sheet合并目录
:param new_file_path: 最终合并的某个小类的excel
:return:无返回
"""
excel_dir = base_dir + "\\" + big_dir + "\\" + small_dir + "\\"
sheet_n = small_dir
# sheet_n = "1-陶瓷电容器"
os.chdir(excel_dir)
for filename in os.listdir(excel_dir):
print(filename)
try:
with open(excel_dir + filename, 'rb') as f:
df = pandas.read_html(f.read(), header=1, encoding='utf-8')
bb = pandas.ExcelWriter(excel_dir + filename + ".xlsx")
df[0].to_excel(bb, index=False)
bb.close()
except Exception as e:
print("异常:" + e)
time.sleep(3)
workbook = pandas.ExcelWriter(full_path)
folder_path = Path(excel_dir)
file_list = folder_path.glob('*.xlsx*')
for i in file_list:
stem_name = i.stem
data = pandas.read_excel(i, sheet_name=0)
data.to_excel(workbook, sheet_name=stem_name, index=False)
time.sleep(2)
workbook.save()
workbook.close()
time.sleep(2)
data2 = pandas.read_excel(full_path, sheet_name=None)
data3 = pandas.concat(data2, ignore_index=True)
# new_file_path = "合并.xlsx"
data3.to_excel(new_file_path, sheet_name=sheet_n, index=False)
category_list = [] # 存放所有大类
category_list_small = [] # 存放所有小类
class DataBase(Tools):
def __init__(self):
# self.tools = Tools()
self.url = 'xxxxx' # 目标网站
self.headers = {'Connection': 'close'} # 请求头,避免ssl报错
# self.big_num = 3 # 第几个大类,从0开始
# self.small_num = 0 # 第几个小类,从0开始
self.net_xpath = '/html/body/div[5]/div/div[2]' # 网站所有大类的table xpath
self.xpath_big = ['/html/body/div[3]/div[2]'] # 对应大类中的小类的table xpath
self.xpath_small = ['/html/body/div[4]/div'] # 对应小类的内容table xpath
def get_big_category(self):
"""获取网站中所有的类别,存放列表中"""
self.get_category(self.url,
self.net_xpath,
category_list,
self.headers)
print(f"1========={category_list}")
def get_small_category(self, big_num):
"""获取某个大类中小类所有的类别,存放列表中"""
self.get_category(f'{self.url}{category_list[big_num]}',
self.xpath_big[0],
category_list_small,
self.headers)
print(f"获取的大类是: {category_list[big_num]} ,如下:")
def get_small_content(self, i, small_num):
"""获取小类中所有内容"""
print(f"获取的大类对应的小类是:{category_list_small[small_num]}")
time.sleep(1)
url_1 = f'{self.url}{category_list_small[small_num]}?page={i}'
print(f"请求的小类的域名为:{url_1}")
res = requests.get(url_1, verify=False, headers=self.headers)
tree = etree.HTML(res.content)
div = tree.xpath(self.xpath_small[0])
div_str = etree.tostring(div[0])
div_str1 = str(div_str, "UTF-8")
time.sleep(2)
return div_str1
def main():
print("*" * 20)
print("在运行前请所熟悉下规则:\n"
"1、按照网页显示,大类名称输入 数字-大类名称,如1-电阻器\n"
"2、小类名称输入 数字-小类名称,如1-固定电阻器\n"
"3、大小类前边的数字表示第几个\n"
"4、如果输错不做判断,只是存放的路径需要自己查找,建议一次性输入正确\n"
"5、!!!!!程序执行过程请勿关闭任何窗口!!!!!")
print("*" * 20)
base_file = os.path.dirname(os.path.abspath("test_database_final.py"))
print("#" * 20)
print("程序将开始执行,请稍后......\n"
"程序已经启动~\n"
f"程序启动目录为:{base_file}\n"
"初始化数据......")
print("&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&\n"
"1-电阻器 2-连接器 3-连接器支架 4-电容器 5-振荡器 \n"
"6-晶体/谐振器 7-电源电路 8-开关 9-传感器/温度传感器 10-光电 \n"
"11-光纤 12-二极管 13-电路保护 14-存储 15-信号电路 \n"
"16-电感器 17-端子 18-插座 19-微控制器和处理器 20-射频和微波 \n"
"21-逻辑 22-晶体管 23-继电器 24-转换器 25-过滤器 \n"
"26-触发装置 27-RC网络 28-可编程逻辑 29-电信电路 30-驱动程序和接口 \n"
"31-放大器电路 32-耐热支撑装置 33-变压器 34-消费电路 35-电池 \n"
"&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&")
big = input("请输入大类的名称(如1-电阻器): ")
small = input("请输入小类的名称(如1-固定电阻器): ")
num = int(input("请输入小类的页数(如50,需要从网站查看): "))
b_n = int(input("请输入该大类对应的序号,共35个大类,从左到右数从0开始,比如0: "))
m_n = int(input("请输入该小类对应的序号,从0开始,比如0: "))
print(f"经过输入,我们要获取的数据为:第{b_n + 1}个大类中的第{m_n + 1}个小类\n"
f"即:{big}中的{small}")
data_base = DataBase()
data_base.get_big_category()
data_base.get_small_category(b_n)
for i in range(1, num+1):
get_content = data_base.get_small_content(i, m_n)
print(f"第{i}次获取:获取的数据开始写入文件,文件名为:第{i}页.html")
file = f"{base_file}\\{big}\\{small}"
if os.path.exists(file) is False:
os.makedirs(file)
data_base.write_html(file=f"{file}\\第{i}页.html",
txt=get_content)
time.sleep(1)
data_base.html_to_excel(base_file,
big,
small,
f"{small}sheet.xlsx",
f"{small}.xlsx")
if __name__ == "__main__":
main()
input('Press Enter to exit…')pyinstaller -F test_database_final.py