

本次安装采用的操作系统是Ubuntu 20.04。
更新一下软件包列表。
sudo apt-get update使用命令安装Java 8。
sudo apt-get install -y openjdk-8-jdk配置环境变量。
vi ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64让环境变量生效。
source ~/.bashrc从Hadoop官网Apache Hadoop下载安装包软件。
或者直接通过命令下载。
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz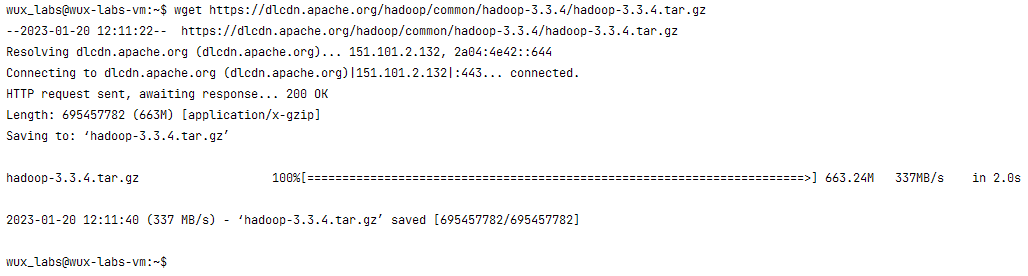
单机环境是在一个节点上运行一个Java进程,主要用于调试。
将安装包解压到目标路径。
mkdir -p apps
tar -xzf hadoop-3.3.4.tar.gz -C apps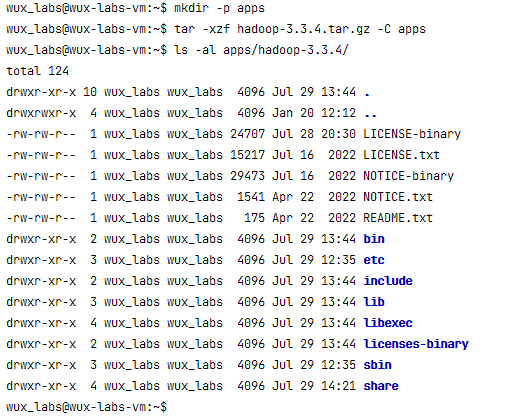
bin目录下存放的是Hadoop相关的常用命令,比如操作HDFS的hdfs命令,以及hadoop、yarn等命令。
etc目录下存放的是Hadoop的配置文件,对HDFS、MapReduce、YARN以及集群节点列表的配置都在这个里面。
sbin目录下存放的是管理集群相关的命令,比如启动集群、启动HDFS、启动YARN、停止集群等的命令。
share目录下存放了一些Hadoop的相关资源,比如文档以及各个模块的Jar包。
配置环境变量,主要配置HADOOP_HOME和PATH。
vi ~/.bashrc
export HADOOP_HOME=/home/wux_labs/apps/hadoop-3.3.4
export PATH=$HADOOP_HOME/bin:$PATH让环境变量生效:
source ~/.bashrcHadoop的常用命令都是通过hadoop命令执行的,命令格式为:
Usage: hadoop [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
or hadoop [OPTIONS] CLASSNAME [CLASSNAME OPTIONS]支持的Client命令主要有:
Client Commands:
archive create a Hadoop archive
checknative check native Hadoop and compression libraries availability
classpath prints the class path needed to get the Hadoop jar and the required libraries
conftest validate configuration XML files
credential interact with credential providers
distch distributed metadata changer
distcp copy file or directories recursively
dtutil operations related to delegation tokens
envvars display computed Hadoop environment variables
fs run a generic filesystem user client
gridmix submit a mix of synthetic job, modeling a profiled from production load
jar <jar> run a jar file. NOTE: please use "yarn jar" to launch YARN applications, not this command.
jnipath prints the java.library.path
kdiag Diagnose Kerberos Problems
kerbname show auth_to_local principal conversion
key manage keys via the KeyProvider
rumenfolder scale a rumen input trace
rumentrace convert logs into a rumen trace
s3guard manage metadata on S3
trace view and modify Hadoop tracing settings
version print the versionhadoop jar 可以执行一个jar文件。
创建一个input目录。
mkdir input将Hadoop的配置文件复制到input目录下。
cp apps/hadoop-3.3.4/etc/hadoop/*.xml input/以下命令用于执行一个Hadoop自带的样例程序,统计input目录中含有dfs的字符串,结果输出到output目录。
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar grep input output 'dfs[a-z.]+'执行结果为:
$ cat output/*
1 dfsadmin同样执行Hadoop自带的案例,计算圆周率。
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar pi 10 10执行结果为:
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar pi 10 10
Number of Maps = 10
Samples per Map = 10
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Starting Job
... ...
Job Finished in 1.767 seconds
Estimated value of Pi is 3.20000000000000000000