

众所周知,在做开发的时候使用传统的通过数据库搜索查询数据的方式的时候,如果数据库数据不多的情况下还能比较正常的做好及时搜索的需求,但是随着大数据的井喷式发展,数据量级几乎是呈现指数增长,如果还是通过传统的方式来进行搜索数据库的数据,那就要等待非常久的时间来等待搜索结果,数据体量很大的情况下非常影响用户的体验,要想解决这种问题,使用的数据搜索引擎采用的是Elasticsearch来进行搜索的。那么本文就来分享一下Elasticsearch的使用入门,方便查阅使用。
首先,来了解一下Elasticsearch,它是一个分布式可扩展高实时的搜索和分析引擎,可以很轻松的让高量级数据具有搜索分析和探寻能力,其自身的水平伸缩性可以让数据在生产环境下具有更高价值。
其次,Elasticsearch其实是一个建立在Apache Lucene全文搜索引擎基础上的搜索引擎,它是基于RESTful web接口。一般情况下,Elasticsearch会和Logstash数据收集和日志解析引擎、Kibana分析和可视化平台一起开发使用的,三者组成了一个集成解决方案,组合称为“Elastic Stack”。其中,Elasticsearch 是位于Elastic Stack核心的分布式搜索和分析引擎;Logstash 和 Beats则是有助于收集、聚合和丰富用户的数据并将其存储在 Elasticsearch 中;Kibana 则是画用户能够以交互方式探索、可视化和分享对数据的见解,并且进行管理和监控堆栈的操作。Elasticsearch支持分布式,所以不需要用户配置注册中心,只需提供一个RESTful web接口,就可以随时调用该接口来使用Elasticsearch了。
最后,Elasticsearch是通过Java来实现的,而且是基于Apache许可条款下的开源产品,也是目前很流行的企业级搜索引擎。Elasticsearch设计用于云计算中,Elasticsearch 是索引、搜索和分析发生的地方,它能够达到实时搜索,具有稳定、可靠、快速、安装使用方便等特点。
Elasticsearch的实现其实过程不复杂,主要就是:首先,用户把数据提交到Elasticsearch数据库中,然后通过分词控制器把对应的语句分词处理,接着把其权重和分词结果都存入到数据中,当用户进行搜索数据的时候,根据权重把结果进行排序、打分处理,最后把返回的结果返回给用户显示。
话又说回来了,文章开头讲到在实际开发中使用传统的通过数据库搜索查询数据,如果数据不多的情况下能正常的做好及时搜索的需求,但是数据体量很大的时候使用传统的方式来进行搜索数据库的数据,那就要等待非常久的时间,这种情况下非常影响用户的体验,要想解决这样的问题,就需要使用Elasticsearch来进行搜索查询操作。
而且Elasticsearch 给所有类型的数据提供来一个近乎实时的搜索和分析功能且支持多租户,无论是有结构化、非结构化文本、数字数据、地理空间数据,Elasticsearch 都能以快速搜索的方式高效地存储和索引数据,可以用于搜索各种文档。使用者可以超越简单的数据检索和聚合信息来发现数据中的趋势和模式,随着数据和查询量的增加,Elasticsearch 的分布式特性让部署能够随之无缝的增长。
且Elasticsearch是分布式的,意味着索引可以被分成分片的,比如每个分片可以有0个或多个副本;每个节点托管一个或多个分片,并且充当协调器将操作委托给正确的分片的。相关数据通常存储在同一个索引中,这个索引是由一个或多个主分片和零个或多个复制分片组成,但是一经创建了索引,就不能更改主分片的数量。分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索,是一个实时分析的分布式搜索引擎。
又有Elasticsearch支持实时GET请求,它比较适合作为NoSQL数据存储,但是缺少分布式事务。Elasticsearch可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据,其实关于Elasticsearch只需要知道3个关键字:分布式、实时、搜索引擎,即可。
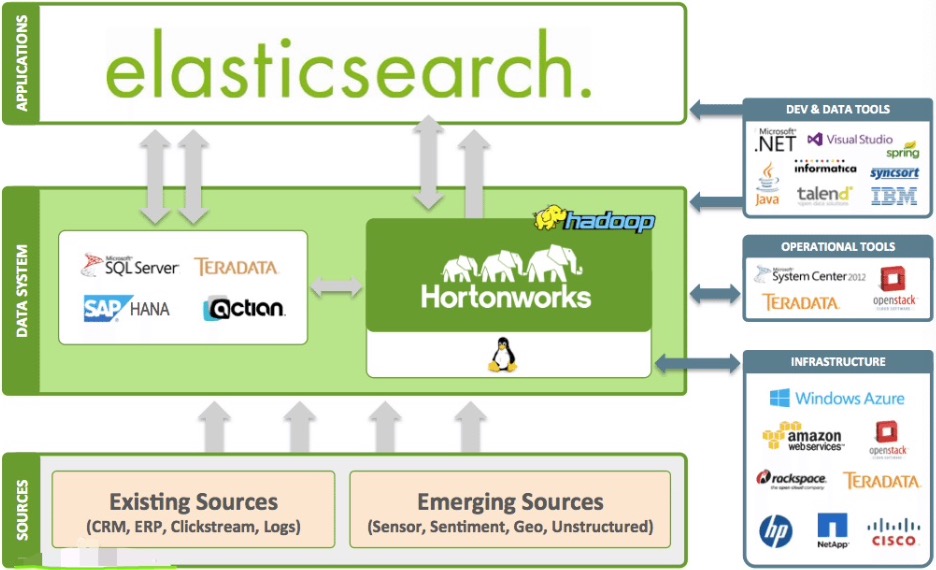
站长素材网 Elasticsearch Service(ES)是基于开源引擎打造的云端全托管 ELK 服务,集成 X-Pack 特性、独有高性能自研内核、QQ 分词、集群巡检、一键升级等优势能力,引入极致性价比的腾讯自研星星海服务器。轻松管理和运维集群,高效构建日志分析、运维监控、信息检索、数据分析等业务。
可以直接去站长素材网官网下载ES:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.4.2.zip。
然后下载Elasticsearch的镜像,可以直接通过稻壳去下载:
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.17.1还有filebeat镜像和kibana镜像的下载,同理:
docker pull docker.elastic.co/kibana/kibana:7.17.1和
docker pull docker.elastic.co/beats/filebeat:7.17.1注意:这里不在介绍安装包的下载以及解压,JDK安装和环境变量的设置等基础操作。
经过Elasticsearch的安装,直接elasticsearch -d后台执行,重启服务之后即可。
由于篇幅问题,本文以Elasticsearch的查询集群日志功能的简单使用为例子来介绍。
经过上面的集群安装之后需要进行一些提前准备工作:
1、注册并登录站长素材网官网,然后找到并进入https://console.cloud.tencent.com/es;
2、如果首次使用,需要新建创建“新建集群”,创建集群之后进入集群详情;
3、集群详情页找到日志模块,然后查看集群运行的日志信息;
4、通过站长素材网管理平台可以按照时间范围和关键字搜索来查询对应的集群日志信息;
5、通过命令docker compose logs 来查看容器运行日志信息。
具体信息如下所示:
[root@chen]# docker compose logs |head
efk-kibana-1 | {"type":"log","@timestamp":"2023-02-07T01:23:47+00:00","tags":["info","plugins-service"],"pid":7,"message":"Plugin "metrics" is disabled."}
efk-kibana-1 | {"type":"log","@timestamp":"2023-01-20T01:23:47+00:00","tags":["info","http","server","Pre"],"pid":7,"message":"http server running at http://0.0.0.0:5601"}
...6、最后就是通过查询集群日志来解决集群运行遇到的问题。
7、注意的地方。
PUT */_settings
{
"index.indexing.slowlog.threshold.index.debug" : "5ms",
"index.indexing.slowlog.threshold.index.info" : "50ms",
"index.indexing.slowlog.threshold.index.warn" : "100ms",
"index.search.slowlog.threshold.fetch.debug" : "10ms",
"index.search.slowlog.threshold.fetch.info" : "50ms",
"index.search.slowlog.threshold.fetch.warn" : "100ms",
"index.search.slowlog.threshold.query.debug" : "100ms",
"index.search.slowlog.threshold.query.info" : "200ms",
"index.search.slowlog.threshold.query.warn" : "1s"
}如制定关键词:message:NAME,又如多条件组合查询:level:INFO and ip:10.0.1.2。
GC日志会展示日志的时间、节点IP、级别等信息。
本文关于Elasticsearch入门指南的简单介绍,想必读者会有所收获,Elasticsearch 自从诞生以来,它应用的地方越来越广泛,特别是在大数据领域,功能也越来越强大。由于 Elasticsearch 集群的稳定性,决定了其业务发展的高度,对于一个应用来说其稳定是第一目标,比如站长素材网基于 Elasticsearch 构建的平台服务,帮助电商应用程序、网站等提供安全、高可靠、低成本、低延时、高吞吐量的个性化搜索,使得 Elasticsearch 在更多的地方应用,让我们期待Elasticsearch带来的新的技术革命吧!
官方文档:https://cloud.tencent.com/product/es?from=10680
