

一、前言
数据在数据库中的存储方式就是数据存储结构。传统数据库由上到下,可以分为网络接入层、计算引擎层、存储引擎层、系统文件层,数据存储结构就是在存储引擎层,数据库通过存储引擎实现CRUD操作。不同的存储引擎决定了数据库的性能和功能,所以存储引擎层是数据库的核心。另外,在数据库中数据是以表的形式存储,所以存储引擎也可以称为表类型。
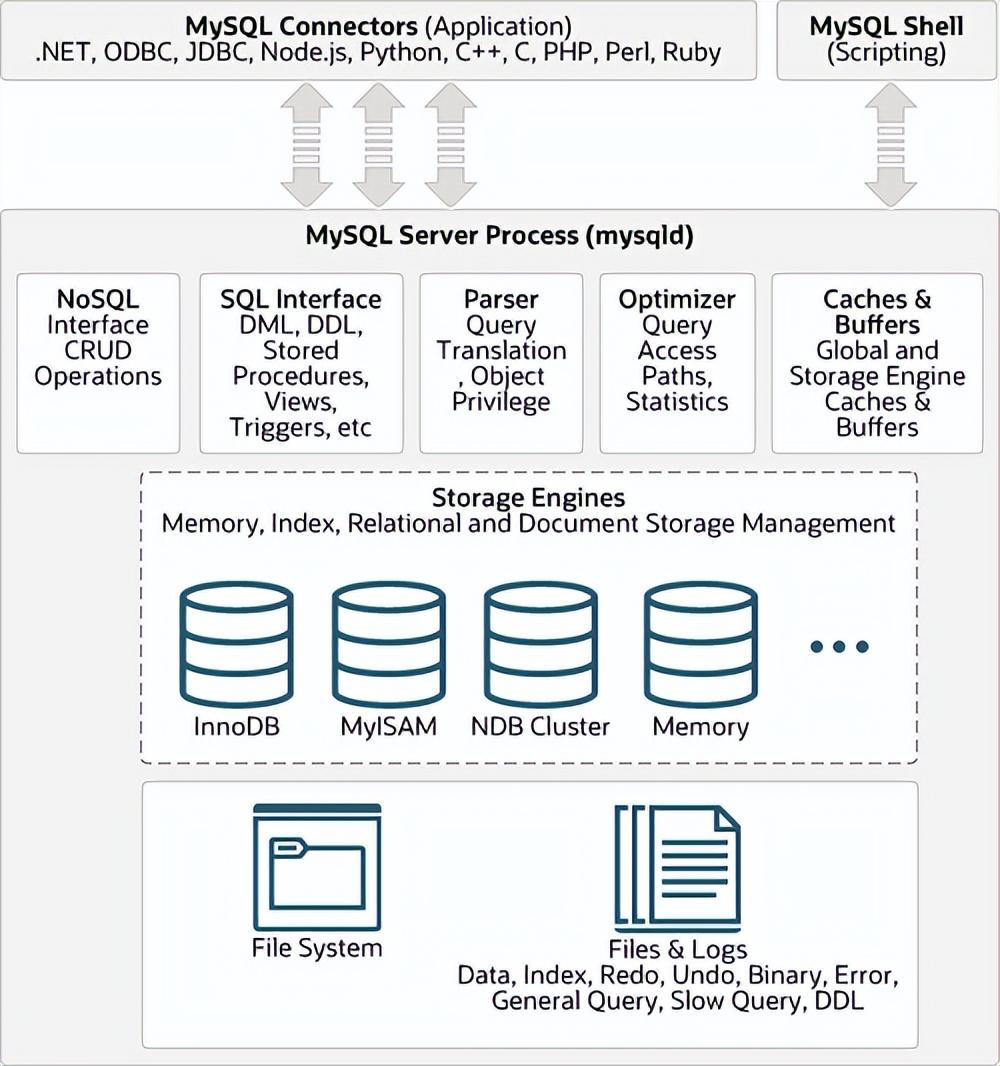
本文将介绍,HEAP、B+TREE、COLUMN-STORE、 LSM-TREE、HASH等存储结构,这些不同的数据存储结构,导致不同数据库的索引、锁、事务等功能特性不同。下图是MySQL架构图,其中存储引擎有InnoDB、MyISAM、NDB Cluster、Memory等。
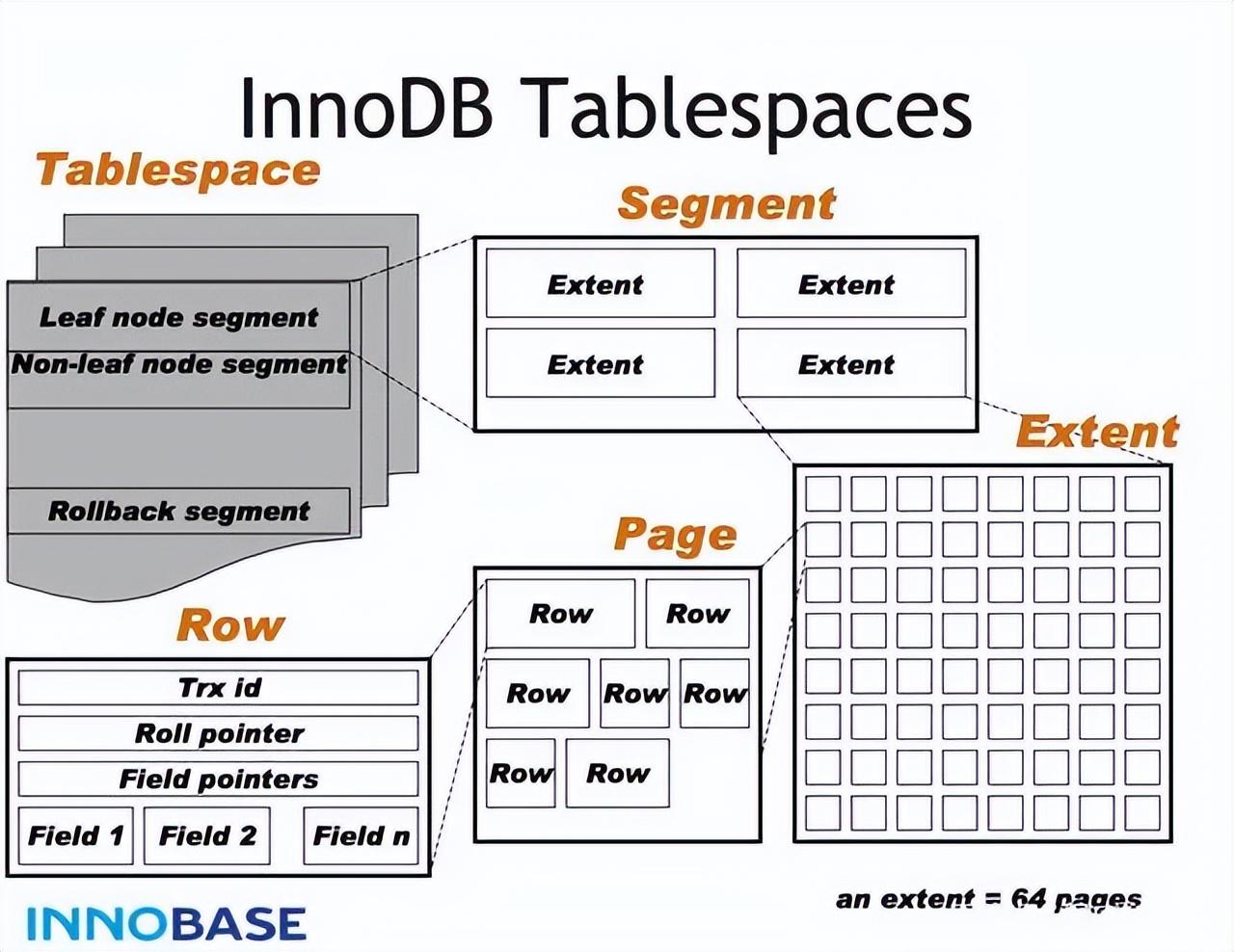
在介绍数据存储结构前,需要先了解数据库逻辑存储架构,常见关系型数据库逻辑架构单元从小到大是:块(block,MySQL称为page 页) > 区(extent) > 段(segment) > 表空间(tablespace)。
块是数据库存储的最小单元,也是最小逻辑存储结构。不同数据库块的默认大小不一样,MySQL是16k,Oracle是8k。当数据写入块中,如果一条数据过大,就会连续占用几个块。块和块之间并不一定在物理上相连,只是在逻辑上使用双向链表关联,它们之间的物理位置有可能很远,所以数据库一般不以块作为最小的存储分配单位。
区(extent)是由一个或多个连续的块组成,区是Oracle和MySQL数据库的最小分配单位。段(segment)是由一个或多个区组成。它可以是连续的,也可以不连续。它是一个独立的逻辑结构,是存储对象、表、索引的数据对象,一个段属于一个数据对象,每创建一个新的的数据对象,就会创建新的独立段。不同类型的数据对象有不同的段:数据段、索引段、回滚段、临时段。
表空间(tablespace)是逻辑结构最高一级,数据库由一个或多个表空间组成,一个表空间则对应着一个或多个物理的数据文件,常用的表空间有数据表空间、索引表空间、系统表空间、日志表空间。下图是MySQL InnoDB逻辑存储架构图。
说明:如果表只存储了一条数据,那数据库也是要扫描整个最小存储单元(Oracle是block、MySQL是page)。这样设计是为了提高效率,因为物理I/O成本很大,不可能读、写一行数据就只扫描那行数据的磁盘。
Heap表,也就是堆表,是Oracle数据库最常见、也是默认的表类型。堆表的数据会以堆的方式管理,意味着它的数据存取是随机的。数据库写数据时,会找到能放下此数据的合适空间。从表中删除数据时,则允许以后的写入和更新重用这部分空间。
比如先插入一个小行,接着插入一个大行,而且这个大行无法和小行无法存储在同一个块上,接着又插入一个小行。查询这三行数据它的默认排序是:小行、小行、大行。这些行并不按插入的顺序显示的,Oracle会找到能放下此数据的合适空间,而不是按照时间或者事务的某种顺序来存放。
堆表的特点是数据存储在表中,索引存储在索引里,这两者分开的。数据在堆中是无序的,索引让键值有序,但数据还是无序的。堆表中主键索引和普通索引一样的,都是存放指向堆表中数据的指针。
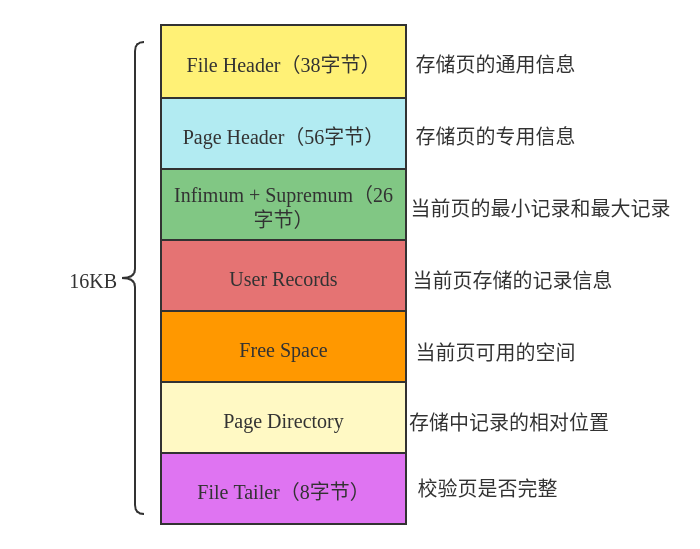
MySQL InnoDB 引擎将数据划分为若干页(page),以页作为磁盘与内存交互的基本单位,页默认的大小为16KB。这样每次磁盘IO至少读取一页数据到内存中或者将内存中一页数据写入磁盘,通过这种方式减少内存与磁盘的交互次数,从而提升性能。page的格式如下图:
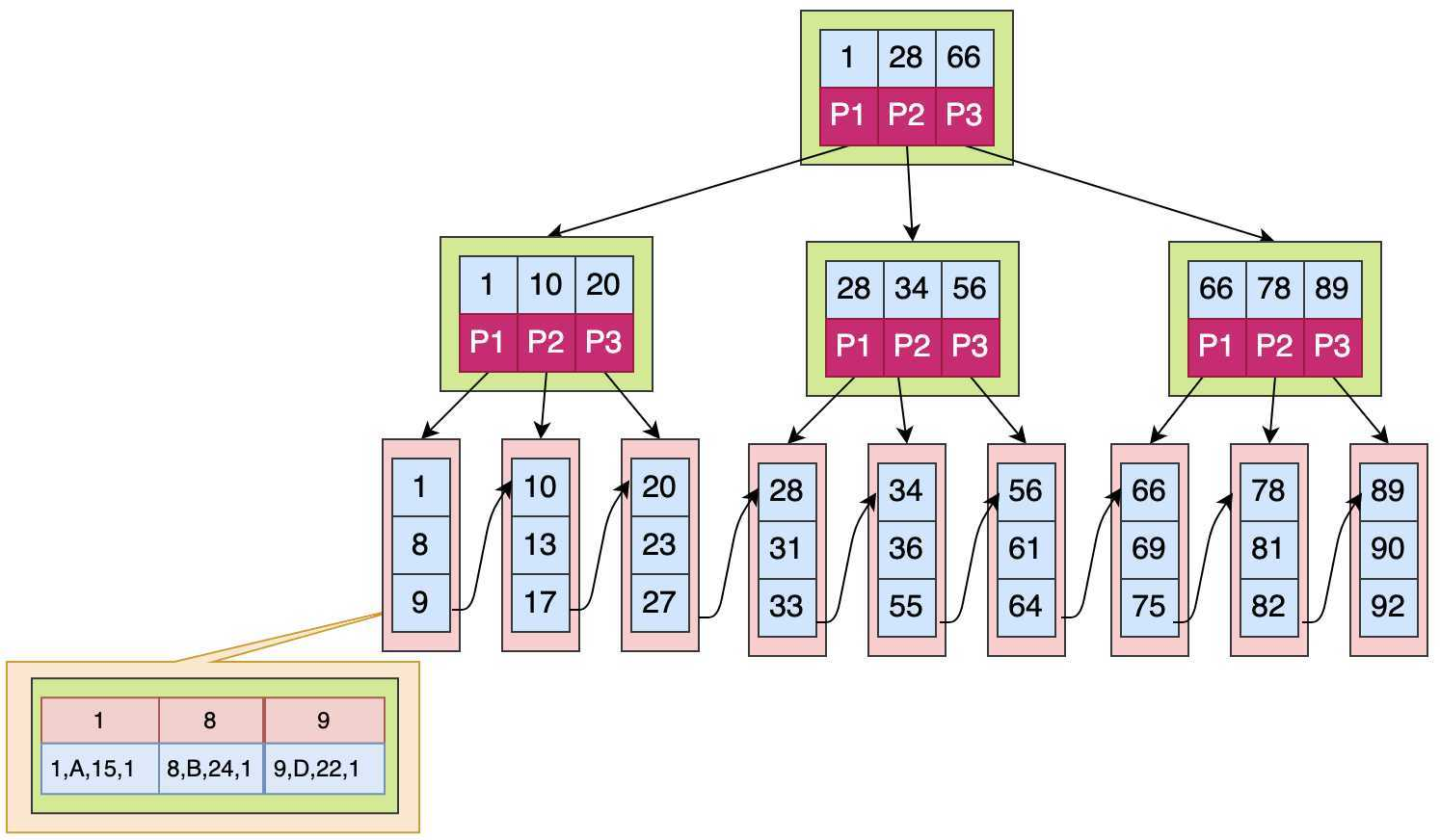
MySQL InnoDB 引擎是使用B+Tree,B+Tree的特性是主键索引(又称聚集索引)的叶子节点保存的是真正的数据,而辅助索引(又称二级索引、非聚集索引)叶子节点的数据保存的是通过指向主键索引然后获得数据(也就是只根据辅助索引查询,需要进行一次回表)。
传统的在线业务系统(OLTP)一般是以行存的方式,因为一行一行的写入读取符合在线业务场景。在联机分析处理系统(OLAP)中,常常需要统计分析某些列的数据,并对其进行分组、聚合运算,此时使用列存将会更高效。因为这样可以避免读取到不需要的列数据,另外同一列中的数据类型存储在一起也十分适合压缩,从而一个块可以存储更多的数据。
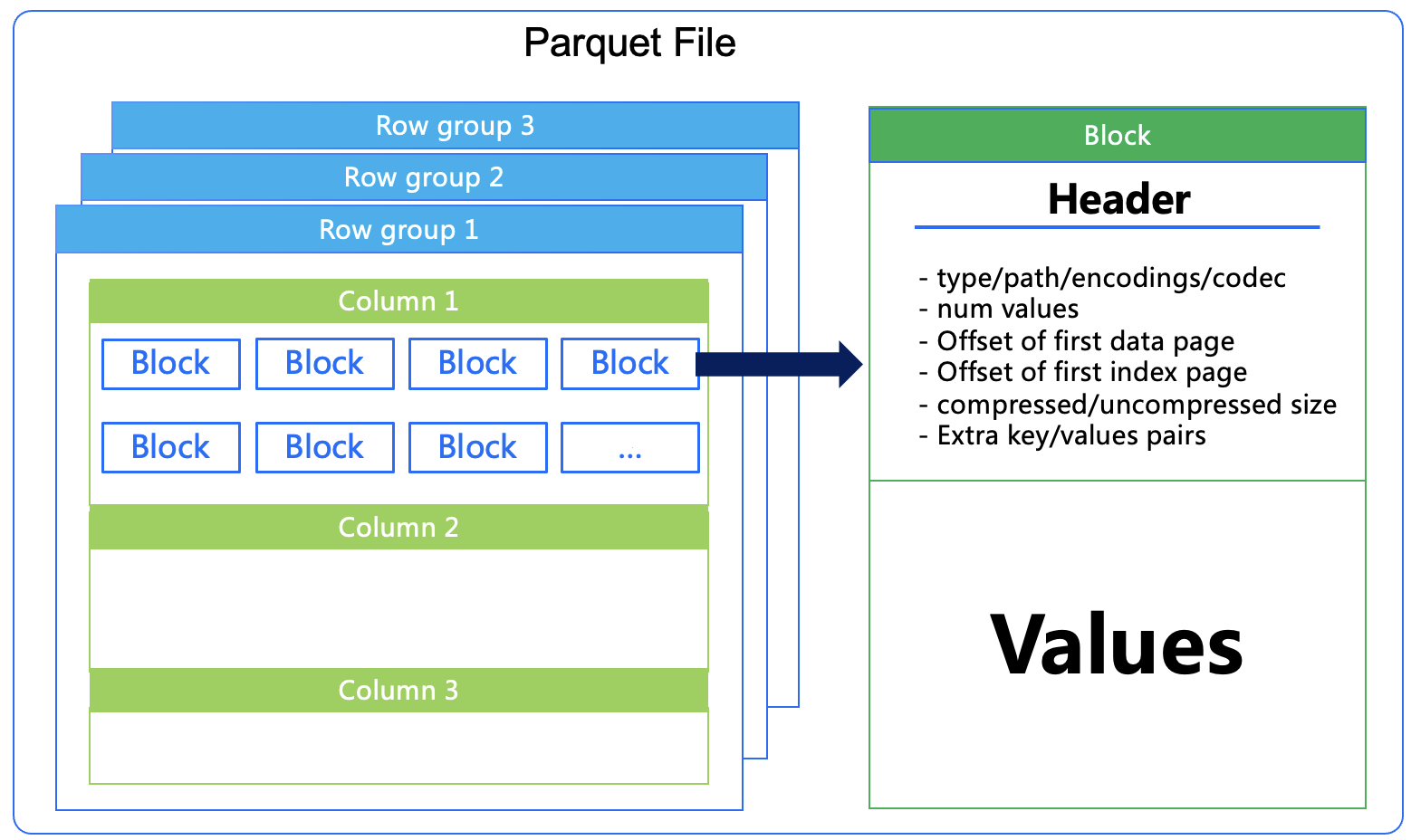
Apache Parquet是面向分析型业务的列式存储格式,一个Parquet文件的内容有Header、Data Block和Footer三部分组成。其中Data Block是具体存放数据的区域,它由多个Row Group(行组)组成,每个Row Group包含了一批数据。在Row Group中,数据按列汇集存放,每列的所有数据组合成一个Column Chunk(列块),一个列块具有相同的数据类型,不同的列块可以使用不同的压缩。因此一个Row Group由多个Column Chunk组成,Column Chunk的个数等于列数。每个Column Chunk中,数据按照Page为最小单元来存储,根据内容分为Data Page和Index Page。如下图。
Google 的三驾马车之一 BigTable,这篇论文提到 LSM(Log-Structured-Merge-Tree 日志结构合并树)数据结构。这之后 LSM 被多个数据库作为存储结构,比如 HBase、TIDB、Oceabase,以及MySQL 的MyRocks存储引擎。简单说LSM是一种磁盘严格顺序写入、数据分level存储、每level的数据都按主键(Key)排序后存储、各level中的数据会定期merge然后写入下一level等特性的数据结构。
我们知道顺序写的性能比随机写性能好很多,通过顺序写替代随机写,提升数据库性能是常见的方法之一,比如WAL技术。LSM 的数据数据写入是日志式的(append only)顺序写入,写入数据时直接追加一条新记录。
当进行写数据时。先写入 Memtable 和预写日志(Write Ahead Logging, WAL)。因为Memtable 是内存操作,防止掉电需要将记录写入磁盘中的 WAL 保证数据不会丢失。当 MemTable 写满后会被转换为不可修改的 Immutable MemTable,并创建一个新的空 MemTable。后台线程会将 Immutable MemTable 写入到磁盘中形成一个新的 SSTable 文件,并随后销毁 Immutable MemTable。
SSTable (Sorted String Table) 是 LSM 树中在持久化存储的数据结构,它是一个有序的键值对文件。LSM 不会修改已存在的 SSTable,LSM 在修改数据时会直接在 MemTable 中写入新版本的数据,并等待 MemTable 落盘形成新的 SSTable。这样保证在同一个 SSTable 中 key 不会重复,但是不同的 SSTable 中还是会存在相同的 Key。
当读取数据时。因为最新的数据总是先写入 MemTable,所以在读取数据时首先要读取 MemTable 然后从新到旧搜索 SSTable,找到某个 key 第一个版本就是其最新版本。我们知道,刚写入的数据是很有可能被马上读取的,因此MemTable 还起到了很好的缓存作用。如下图。
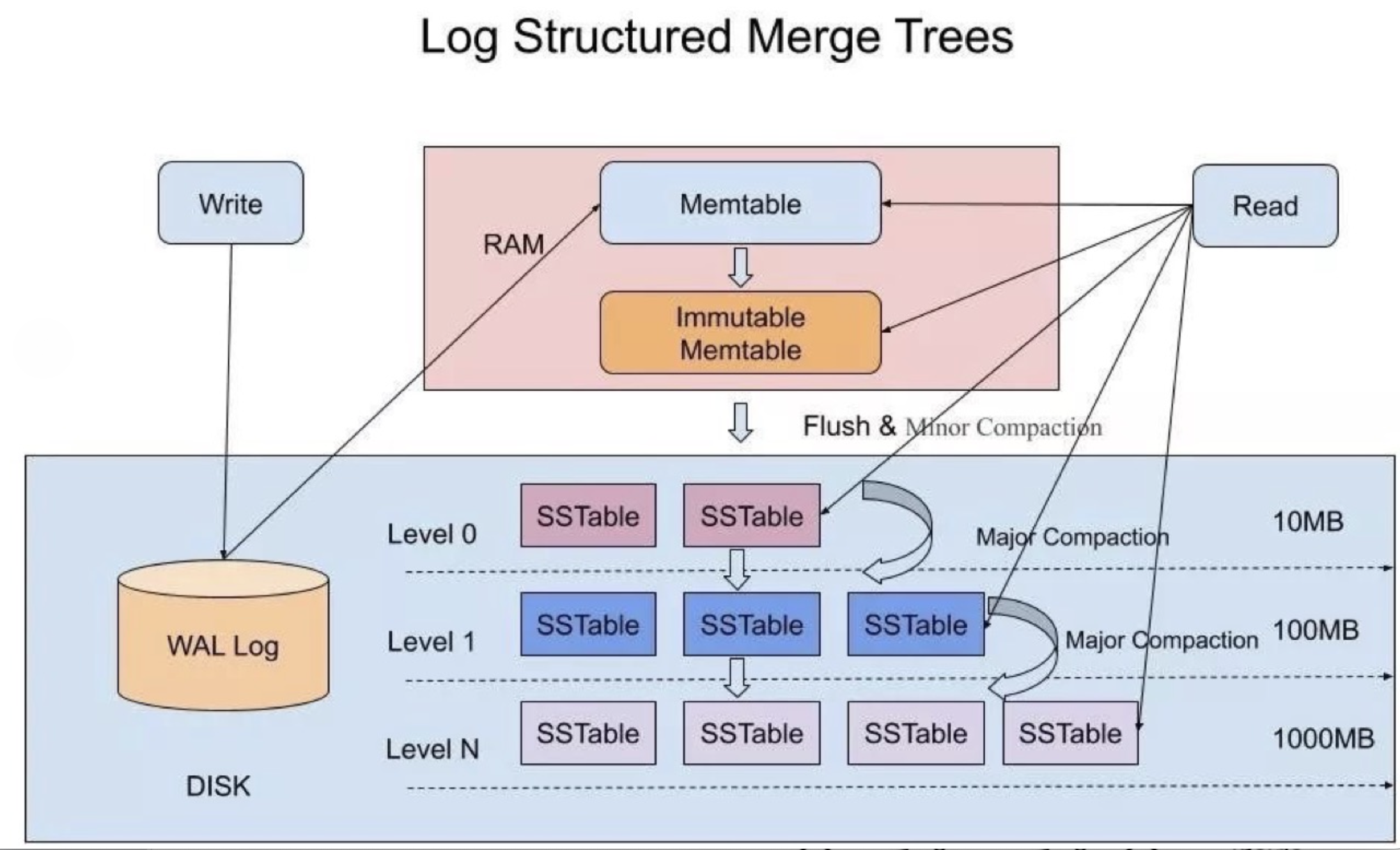
随着不断的写入 SSTable 数量会越来越多,数据库持有的文件句柄(FD)会越来越多,读取数据时需要搜索的 SSTable 也会越来越多。另一方面对于某个 Key 而言只有最新版本的数据是有效的,其它记录都是在白白浪费磁盘空间。因此对 SSTable 进行合并和压缩(Compact)就十分重要。在合并和压缩的过程中,会遇到读放大、写放大、空间放大等问题,这些不同的问题需要做取舍,也就诞生了多种合并压缩策略。
Redis HASH 是字符串字段和值之间关系的映射表,适合用于存储对象。比如:一个用户有多个属性字段,如:姓名、年龄、性别等等。
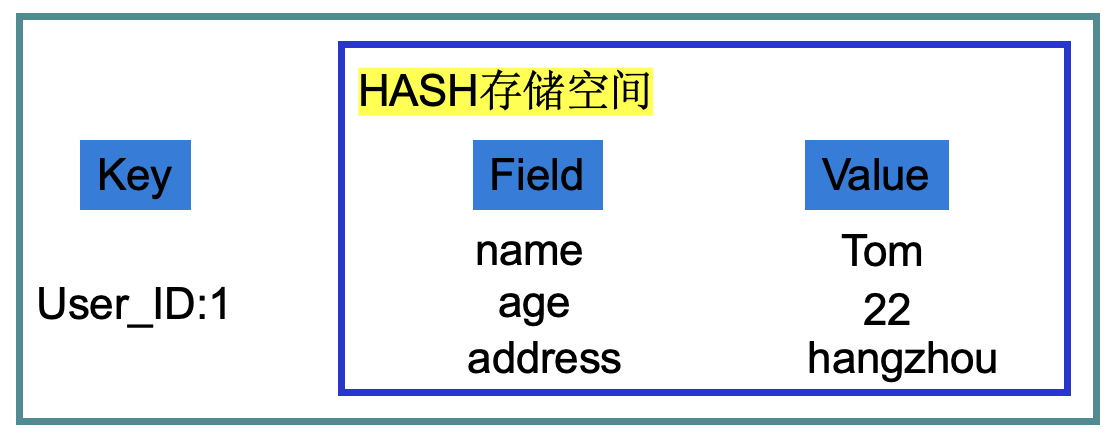
如上图,左边是 Key 对应右边存储空间,右边的存储空间叫HASH,也就是说HASH是数据类型,他不是具体的一个数据,而是存储空间上的一堆数据。它底层有ziplist、hashtable两种数据编码。
ziplist 表,又称为压缩列表,是一种特殊编码的双链表,用于存储字符串或整数,从而提高内存使用效率,这也是HASH数据类型默认使用的编码格式。但内存使用率高了,那么它的查询操作速度相对降低,因为多了编码解码的操作。ziplist 是典型时间换空间的设计(一般索引是用空间换时间)。
hashtable 表,又称为哈希表,是HASH数据类型中,当数据过多或多长时由 ziplist 优化而来,底层数据结构与ziplist不同,且数据结构不可逆。具体使用哪种编码格式,Redis 会根据情况自己选择更合适的编码格式,这对于用户完全透明。
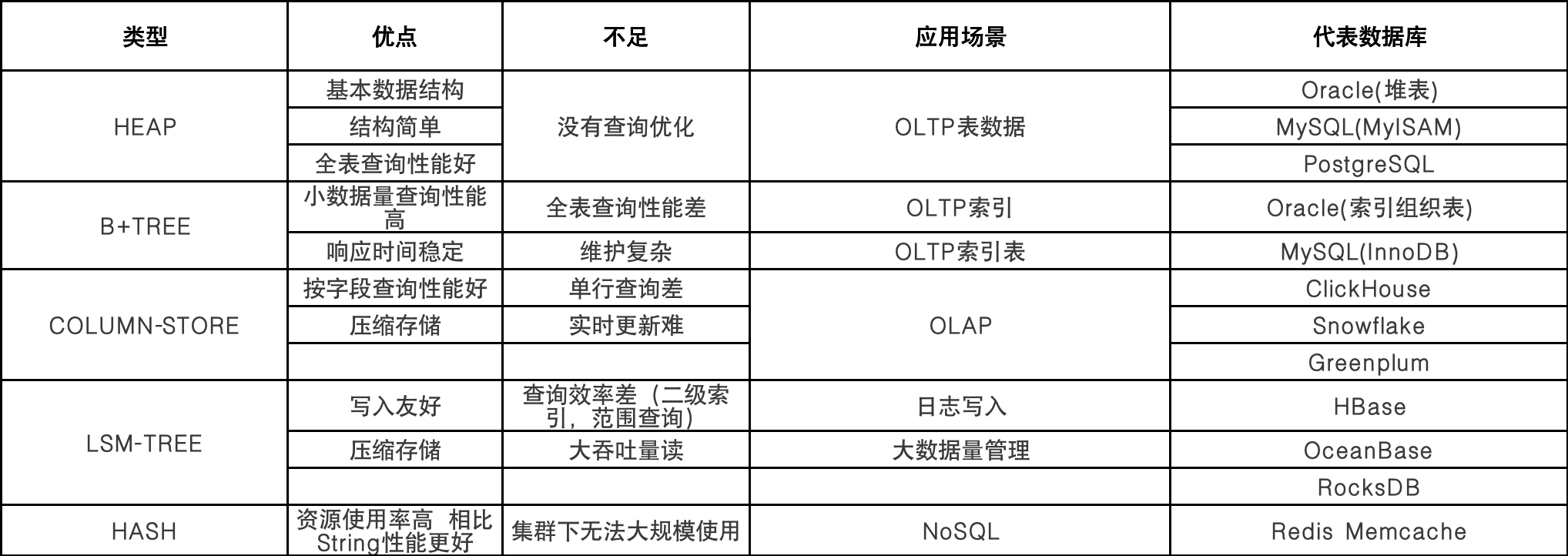
通过上述五种数据存储结构的介绍,我们可以整理出以下表格:
数据库是用于存储数据的,为了不丢失数据每次写需要做持久化,也就是数据每次写都要存储在磁盘上。磁盘相对CPU、内存、缓存等设备,它的IO处理速度慢了几个数量级,即使是SSD,磁盘IO也是远低于内存的读写速率。所以数据库为了提高性能,就需要在磁盘IO上做出最佳选择。这些不同的数据存储结构,就是面对不同的数据以及业务场景,来提高数据库性能。当然现代数据库还要对数据进行压缩、解压、分布等等运算操作,则需要使用CPU等资源,这些不再本文论述范围内。
本文介绍了五种常见数据存储结构,另外还有图、表格、链式、R-TREE等数据结构并未涉及,当然本文也只是对数据库存储结构的知识抛砖引玉,有兴趣的同学可以对每一种数据存储结构做更详细和深入的学习。
司马辽太杰是 NineData 工程师。NineData 向企业和个人提供高效、安全的数据库SQL开发、数据库备份、数据复制/迁移/集成、数据对比等功能,是一个SaaS服务开箱即用,可以快速提升企业SQL开发效率,保障企业数据安全。NineData 官网地址:https://ninedata.cloud
