

大家好,我是二哥。
最近二哥利用业余时间在复习 eBPF ,为啥说是复习呢?因为我曾经短暂使用过 eBPF 。一晃几年过去了,我在研究 K8s 网络模型和 service mesh 的过程中,反复看到它的出现。它真是一个勤劳的小蜜蜂,哪里都能看到它的身影。而我在几年后重新拾起 eBPF ,对它有了更深的感悟,对它的小巧精悍也有了更多的喜爱。
于是我干脆在公司的年度 Tech Forum 上,和同事一起报了一个 topic "eBPF primer and its use cases in K8s"(eBPF 基础和 K8s 使用案例介绍),希望可以和更多的人分享所思所悟。
eBPF 在 K8s 中的一个使用案例便是:利用 eBPF 实现 socket level 重定向,本篇大致介绍为何需要做 socket level 重定向以及怎么做,最后我们再来看下 Cilium 是如何利用它来将两个 socket 以短路的方式连接到了一起从而大幅提升进程间通信性能的。
我们先来看图1所示的简单例子。进程 A 和进程 B 通过本机的 Loopback 网络设备通信。我们知道,虽然通信双方是走的 Loopback 这个虚拟的设备,从而省去了与真实网络设备相关的排队(Queue Descipline)等待时间,也省去了网络包离开本机后的网络延迟,但网络包在 TCP/IP 协议栈上该走的路可一步都少不了,万一路由表和 iptables 设置得比较复杂,那依旧需要在路由和 net filter 上面花去很多时间。
此外,网络包经过协议栈时,起码要经过 30 个左右的函数调用才能进入设备驱动层,这里的每一个函数都为网络延迟助了一把力。你可以按照下面的方法来体验一下这么多函数调用产生的 call stack 是多么的壮观和吓人。
[root@xx tracing]# cd /sys/kernel/debug/tracing
[root@xx tracing]# echo dev_hard_start_xmit > set_graph_function
[root@xx tracing]# echo nop > current_tracer
[root@xx tracing]# echo function_graph > current_tracer
[root@xx tracing]# cat trace | more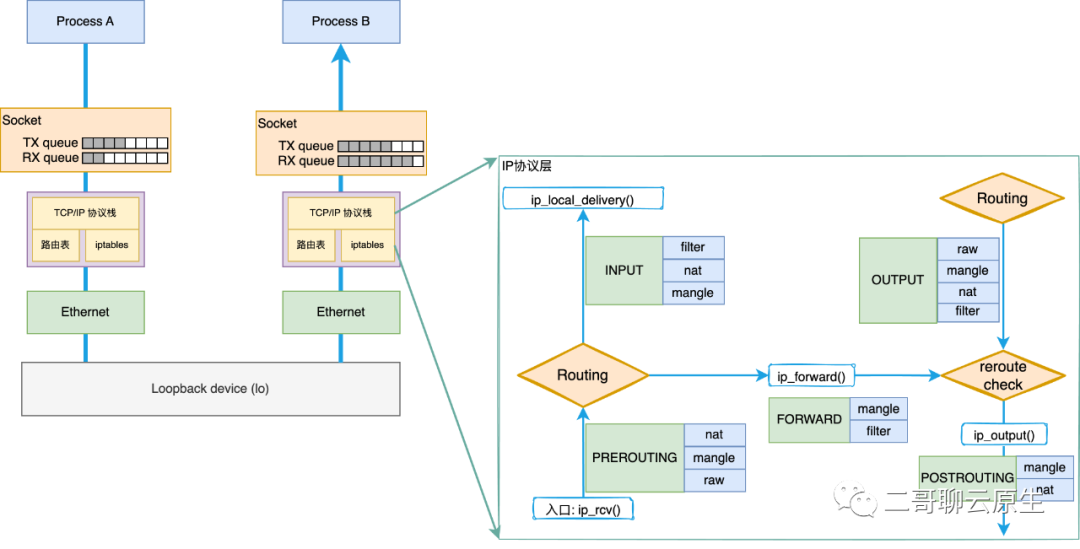
图 1:进程间通过 lo 设备通信
上图中,二哥还在 socket 这一层画出了 TX queue 和 RX queue 。在内核里,它们的准确名字应该是 sk_write_queue 和 sk_receive_queue 。它们和 socket 以及 skb 之间的关系见图 2 。之所以把图 2 画出来是因为:
本文中我会多次说到一个词:网络包。它在图 2 中用黄色的框 sk_buff 表示,它亦被简称为 skb 。
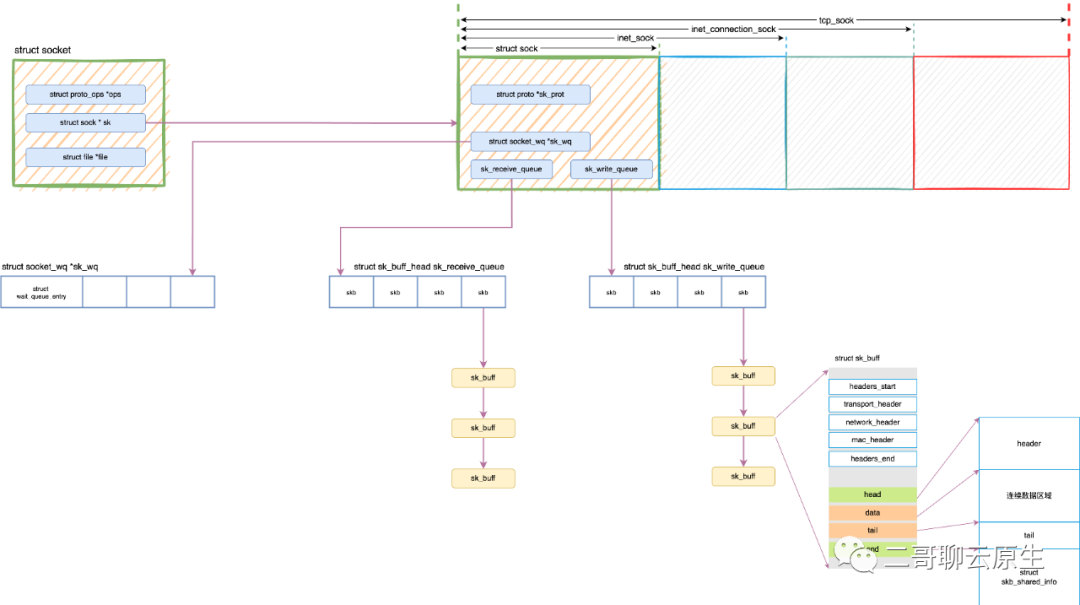
图 2:socket TX queue 和 RX queue
我们在图1 的基础上更进一步,把进程 A 和进程 B 放到一个 network namespace 里面来。你在哪里见过这种方式?是的,sidecar 就是这么玩的。
结合刚才对图 1 的分析,你应该能猜到图 3 这种方式和图 1 没有本质上的差别,它一样会碰到网络低效的问题,因为一个 network namespace 一样会包含它自己的路由表、iptables 、network device 等关键要素。
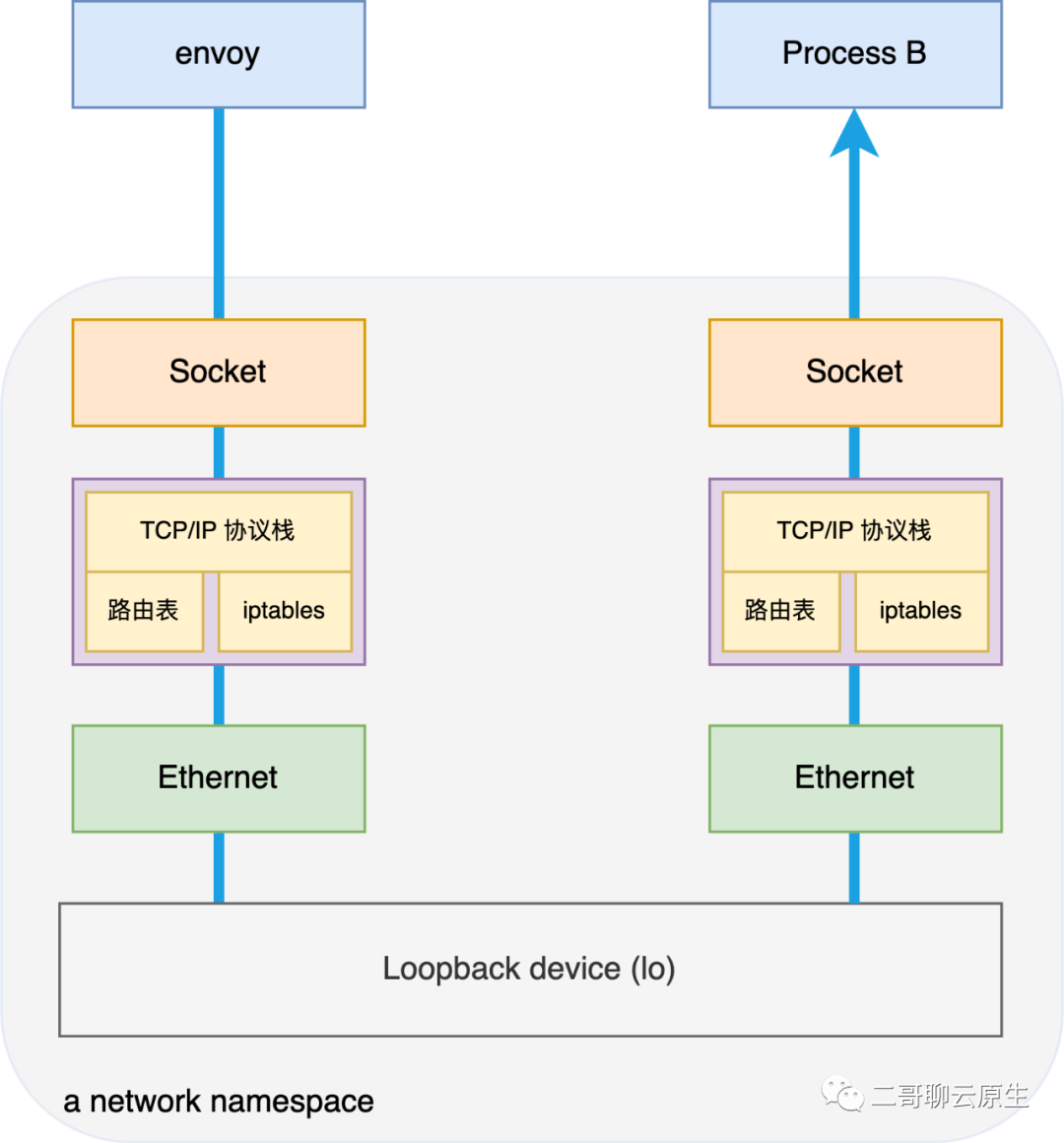
图 3:同一个 network ns 里进程间通过 lo 设备通信
我们把图 3 所涉及到的网络延迟问题再放到 sidecar 的实现场景里面来,如图 4 所示。这就是我们常讲的 sidecar 注入所需要付出的刚性成本。既然是刚性成本,就意味着我们是无法避开这部分消耗的,除非你不用它。
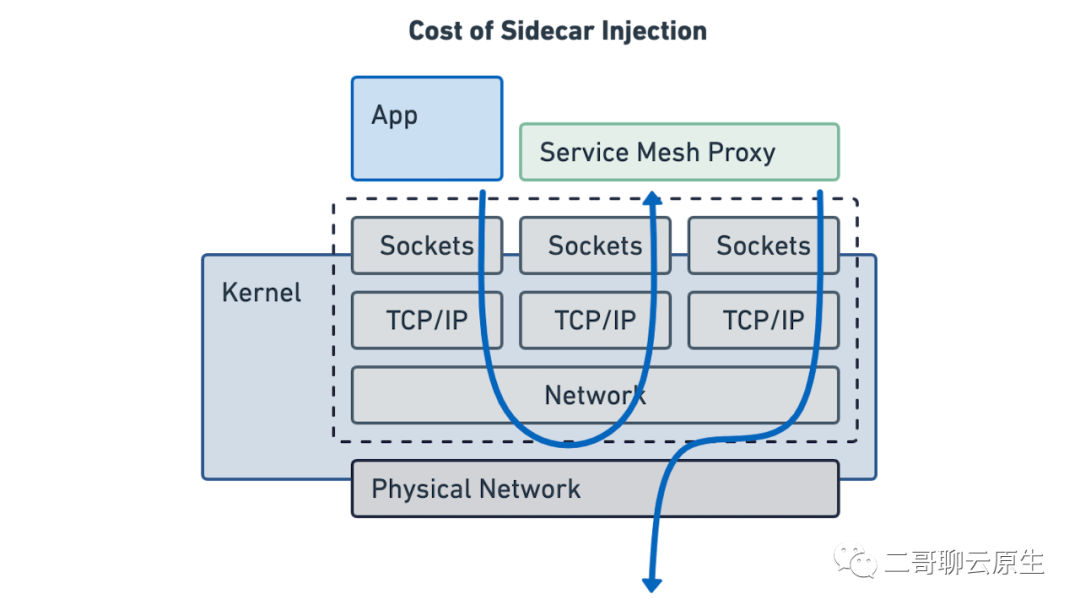
图 4:sidecar 网络成本
通过我们刚才的分析,我们知道所谓的延迟,很大一部分原因是我们的网络包不得已需要经过 TCP/IP 协议栈处理。那如果网络包不经过协议栈的话,不就完美避开这些导致延迟的坑吗?
这个大胆的想法首先由 Cilium 提出来。我将其想法简要地画在了图 5 上。按照图 5 右边的方式的话,从 envoy 发出来的网络包会从它的 socket 层 TX queue 直接被放入了进程 B 的socket 层RX queue 里。对于进程 B 而言,它当然不会在意这个网络包是怎么过来的。这里所说的网络包即为图 2 中所画的 skb 。
这个想法便是 socket level redirect ,我们可以看到它完美地避开了纷繁复杂的协议栈和网络设备层。

图 5:进程间通过 lo 设备通信
图 5 的想法很美好,不过该如何实现呢?这个时候就该 eBPF 登场了。
eBPF 可以用来监听所有的内核 socket 事件如被动建立连接事件(BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB)和主动建立连接事件(BPF_SOCK_OPS_ACTIVE_ESTABLISHED_CB),并将这些新建的 socket 记录到 BPF_MAP_TYPE_SOCKMAP 这种类型的 map 里。图 6 中 _skops 代表了这样的 eBPF 程序,而 sock_hash 则为这里提及的 map ,这种使用场景下,我们把它称为 sockmap。
eBPF 程序还可以用来拦截所有 sendmsg 系统调用,根据系统调用的参数去 map 里查找 peer socket,之后调用 BPF 函数 bpf_msg_redirect_hash() 来绕过 TCP/IP 协议栈,直接将数据发送到对端的 socket RX queue。图 6 中 _sk_msg 代表了这样的 eBPF 程序。

图 6:实现细节图
实现代码位于 https://github.com/LanceHBZhang/socket-acceleration-with-ebpf 。这是二哥从别人的 repo fork 过来的,已经经过测试了,可以使用。
最后,我们来看看 Cilium 是如何利用 eBPF socket level 重定向来实现两个神奇的功能的:
图 7 展示了 Cilium 实现 sideless service mesh 的奥秘:eBPF socket level 重定向。
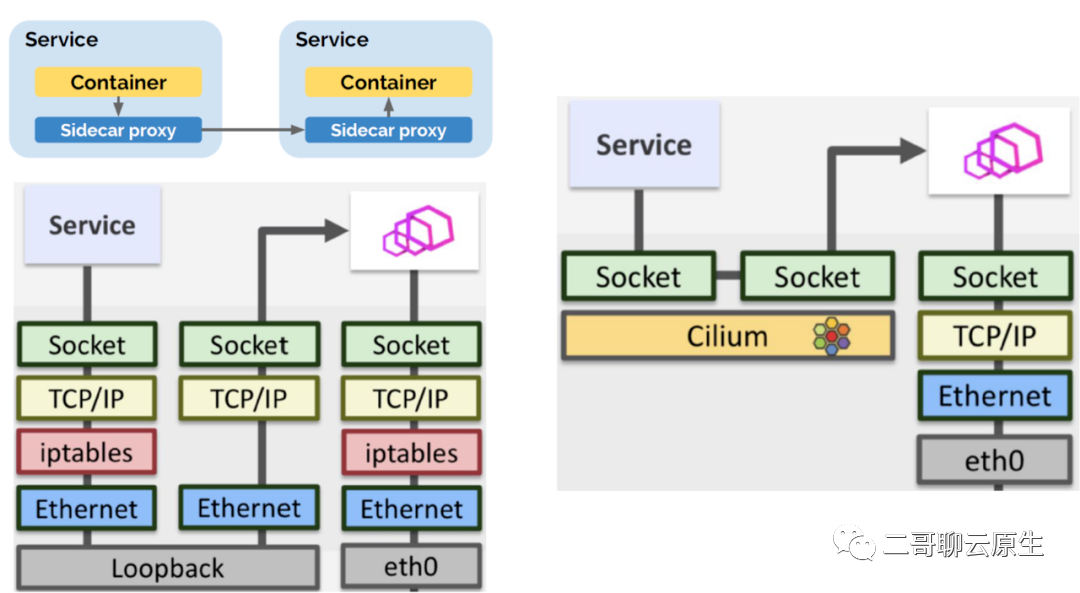
图 7:sideless service mesh
而基于 socket level 重定向这个想法所实现的 sidecarless service mesh,我们看到与传统方式相比,在每秒可处理的请求数上得到了巨幅的提升。
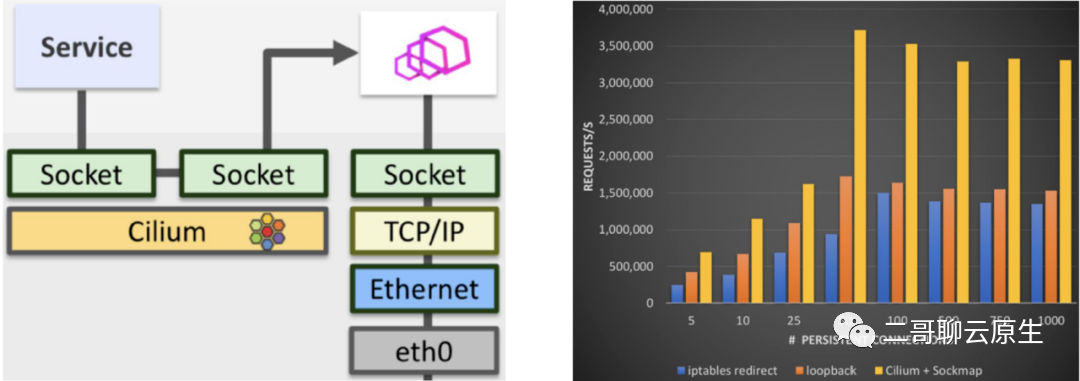
图 8:性能报告
以上就是本文的全部内容。码字不易,画图更难。喜欢本文的话请帮忙转发或点击“在看”。您的举手之劳是对二哥莫大的鼓励。谢谢!
