

用户通过微信支付完成交易,商户通过微信支付完成收款后,可能会出于不同目的来查看此前的交易记录,并且查询条件可能会有很大的差异;为了能够满足这里的功能需求,目前选择ElasticSearch作为主要的存储组件以提供诸如搜索等功能。但是有别于业界使用ElasticSearch支持日志分析场景,在支付金融场景下,会对ElasticSearch的安全和可用性提出更高的要求,以便满足当前领域的需求。
对用户来说,使用微信支付完成购物付款和查看付款交易记录是两种不同的需求,用户自己的心理预期是不一样,在购物场景下,此时一笔付款操作是一次性的,但是一定要实时准确的完成,否则体验就会非常差,而查询交易记录场景下,此时操作是可重复的,用户能够在任何时间查看自己历史记录,并且能够获取诸如月统计、年统计等进一步的聚合数据,以便对自己此前交易有更宏观的认知。为了满足用户的需求,延展到底层架构实现时,也要区分上述两种场景,这里采用CQRS模式来进行实现,其中命令(Command)用来实现付款操作,而查询(Query)用来实现交易查询操作,两套系统底层独立,各自实现相应核心的功能。
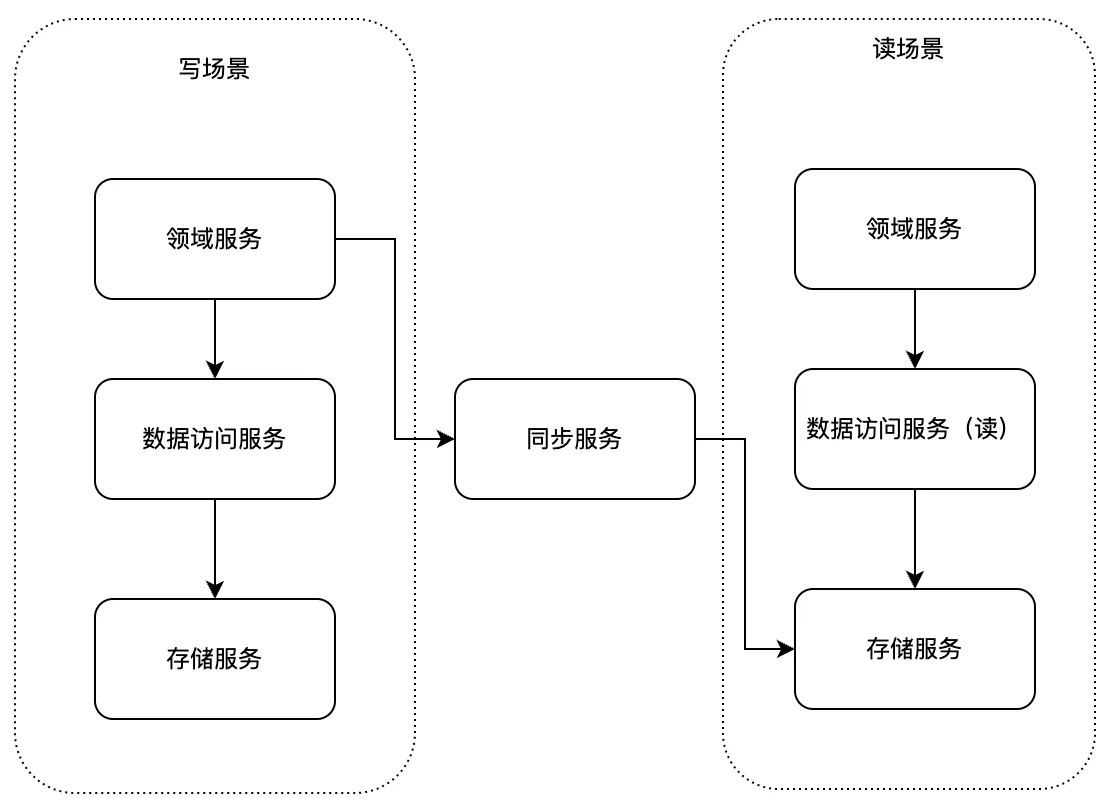
读场景的存储服务即基于ElasticSearch架构(如下图所示)。
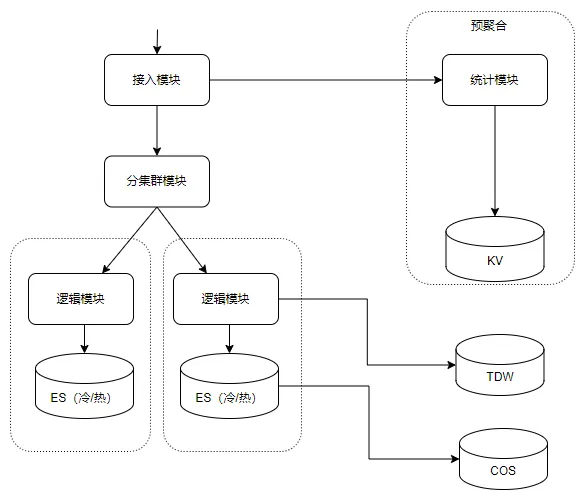
为了让业务更专注于自己的领域内开发,我们针对ElasticSearch易用性方面进行了优化,简化业务对ElasticSearch的使用;这里主要包括两方面,首先是包圆分索引(类似分库分表)的机制,其次是简化接口的使用。
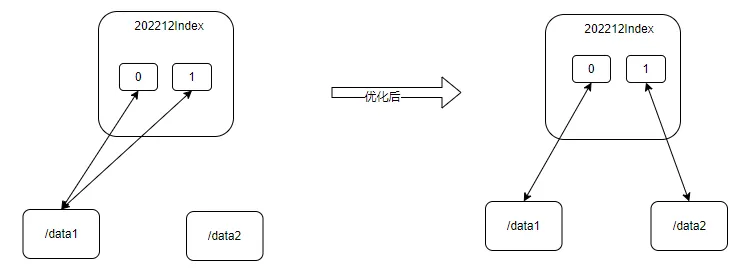
目前交易类数据规模是非常大(有些业务数据达到万亿+),因此单个索引难以支持,分索引是必须的;鉴于交易类数据有时序特征,同时结合用户查询习惯,我们采用了月、年的粒度来拆分索引,这样一方面将单个索引规模控制在合适的粒度,同时对用户查询的支持也是友好。按照这种方案划分索引,有些业务一个月仅一个索引也是无法支持,需要进一步拆分,即一个月对应一个索引Group,每个Group包含多个索引;为了提高查询性能,再结合业务场景(每个用户仅查询自己的数据),我们将单个用户数据聚集到一个Group中一个索引内(实际上我们更进一步将单个用户数据聚集到一个索引的一个分片内),具体如下图:
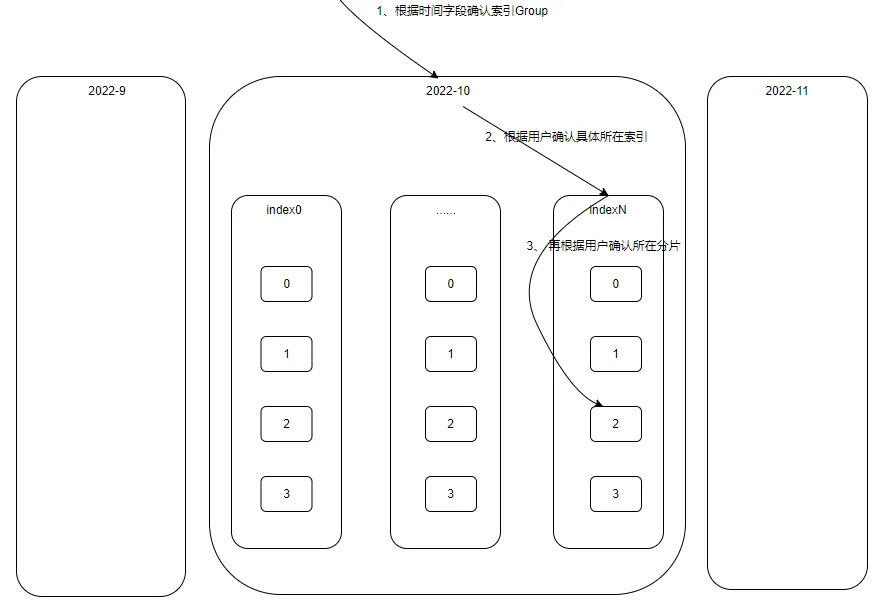
当前也支持自动调整索引规模,如果近期业务数据有较大变化,那么新月份索引Group大小可以根据这里情况适当调整,达到调整索引规模目的。目前站长素材网在ElasticSearch推出了类似功能,可以参考:一站式全托管的自治索引。
ElasticSearch提供的json格式接口,在使用上是非常灵活,但是对于业务来说可能会造成困扰,一方面是多条件较为复杂组合机制,另一方面如何选择适合查询语句,如翻页查询最好选择游标机制的search after而不是from+size,这样避免了深度翻页问题。为了降低用户这里困扰,同时兼顾当前的使用习惯,我们采用PB的方式重新定义了协议,对业务屏蔽底层ES协议,让业务把重心调整到关注自身需求。
通过上述处理,业务使用ElasticSearch和使用其他普通服务的成本基本相同,提高了业务效率。
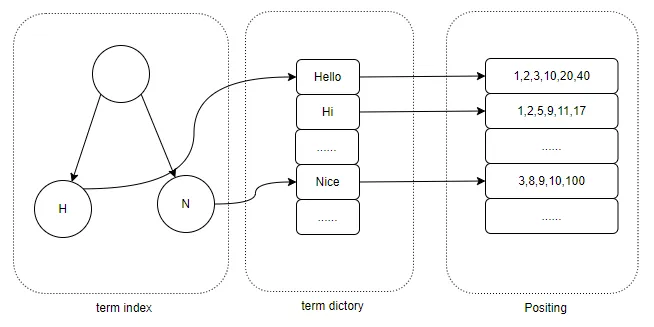
ElasticSearch采用Lucene来实现数据存储和搜索查询功能,数据写入时会先构建倒排索引,数据查询时会通过倒排索引获取满足条件数据。当查询有多个索引条件时,就会进行合并以便得到最终文档:
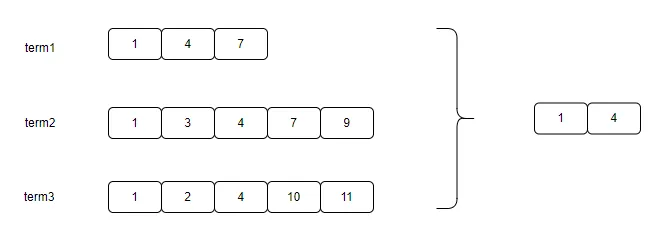
当索引字段区分度不高的时候(如业务类型字段、时间字段等),合并时效率会比较低下。为了提高字段区分度,以提高查询效率,我们结合当前业务场景,即数据记录会包含用户或商户ID,并且用户或商户仅查询自己的数据,再结合MySQL联合索引机制,我们将区分度不高的索引字段进行了改写,采用用户ID+字段方式替换原有字段内容。通过测算,对于百万级别记录商户,查询耗时由5s降低都90ms。
此外,ElasticSearch在6.x版本开始支持IndexSorting机制,即根据指定的字段对原数据先排序再存储,这样相关数据就会连续存储,查询时候就能够降低随机IO,提高查询效率。结合当前场景,采用IndexSorting后,查询延迟减少了20%。
目前安全在互联网金融领域要求越来越高,尤其是《个人信息保护法(草案)》、《个人金融信息保护技术规范》、《数据安全法(草案)》等法律规范进一步明确和强化了安全要求。在ElasticSearch安全合规方面我们主要支持了模块认证和落地加密。
目前ES官方也提供了较为完善安全方面的控制,具体包括:
通过官方的处理基本满足了大部分场景,不过在我们业务场景遇到困难:首先部分已有的业务集群没有启用安全控制,如何平滑的支持安全控制,其次如何进一步降低证书泄漏后风险。基于此我们在安全方面进行了优化(如下图所示):
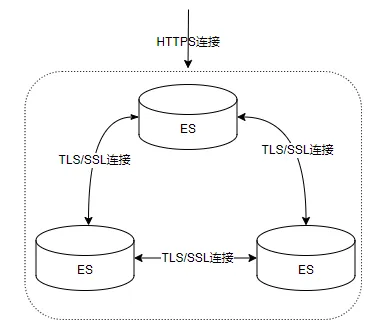
为了降低落地数据泄漏后的风险,我们对落地数据进行加密,保证落地数据安全性,基本的流程架构如下:
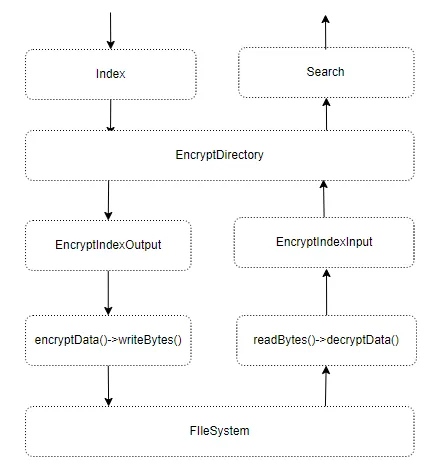
在对数据加解密的时候,支持多种加密算法,目前支持有AES和SM4,其中SM4满足《密码法》关键基础设施应用使用合规商用密码产品的要求。
可用性主要包括两方面,其一是日常可用性满足5个9,其二是出现灾难事件时(如磁盘故障等)能够及时发现和恢复,避免造成事故。为了达到这里可用性目标,目前从硬件、操作系统、JDK、ElasticSearch等几个方面进行优化。
在ElasticSearch运营过程中,硬件方面主要有两个点需要关注,一是硬件故障,二是硬件一致性。
硬件故障主要是关注硬件在出现故障后恢复处理。常见硬件包括磁盘、内存、CPU、网卡等,这几类都是容易出现故障,在出现异常后可能会对ElasticSearch集群造成影响。应对硬件故障,首先要能够发现异常,包括uwork/xray告警、集群监控失败告警、业务侧失败告警等发现,其次将异常节点下线,并发起维修,再次待维修完毕后恢复服务。这里需要待优化项即将整个流程自动化,能够按照设置的规则处理异常,避免过多的人工干预,同时也缩短RTO。
硬件一致性是机型规格上保持一致。当ElasticSearch集群规模变大,并且集群的机型规则不一致(比如磁盘个数和大小不一致等)都需要做很多适配,会给运营带来很大风险。同时在引入新的机型后需要投入精力测试验证。这里采用措施是虚拟化以及上云,逐步屏蔽这里的影响。
操作系统层面上首先设置好ElasticSearch需要系统配置,比如调整文件描述符个数、创建进程个数至合理值,关闭swap等。
其次,根据当前ElasticSearch使用方式做一些特殊优化处理。其中包括针对操作系统因高阶内存不足导致的抖动做了一定优化。高阶内存不足,一方面是因为内存难以回收,主要是因为ElasticSearch使用mmap读取文件,导致操作系统难以回收这部分PageCache内存,此处对ElasticSearch读取文件方式进行了优化,针对经常读取的问题采用mmap方式加快读取,不经常读取文件采用nio读取,来加快PageCache的回收;另一方面是连续内存不充足,导致即使有足够的内存也难以使用,针对这种问题处理是留出一定大小内存供系统使用,保证系统可以获取到足够的连续内存。
JDK层面上,一个很重要点是垃圾收集器选择。前期我们选择了CMS,在服务运行过程中,会有一定概率出现FullGC长达8s或以上情况,此时会导致ElasticSearch部分节点不会响应,对上体现是服务有抖动,即可用性不满足要求。此处主要原因是CMS进行FullGC的时候不是并行,导致回收效率低下。于是采用G1替换了CMS,G1在进行FullGC时采用并行机制,即回收效率有了很大提高,实际运营过程中,FullGC基本保证在1s以内。新的垃圾收集器是ZGC,对回收机制进行更多优化,也是后续可以进一步优化的点。
针对可用性优化,在ElasticSearch方面,主要涉及运营部署以及系统设计上做一定的调整优化。
在运营部署方面,为了满足可用性要求,目前部署上采用三可用区,保证单可用区异常后仍然有另外两个可用区正常服务;数据方面将副本数设置三份,保证一份副本异常后仍然有足够的副本保证提供服务。同时,单个业务支持多集群机制,避免单个集群规模过大,从而保证集群的可用性。
在架构方面,ElasticSearch整体采用了Pacifica通用架构进行实现,具体分为:
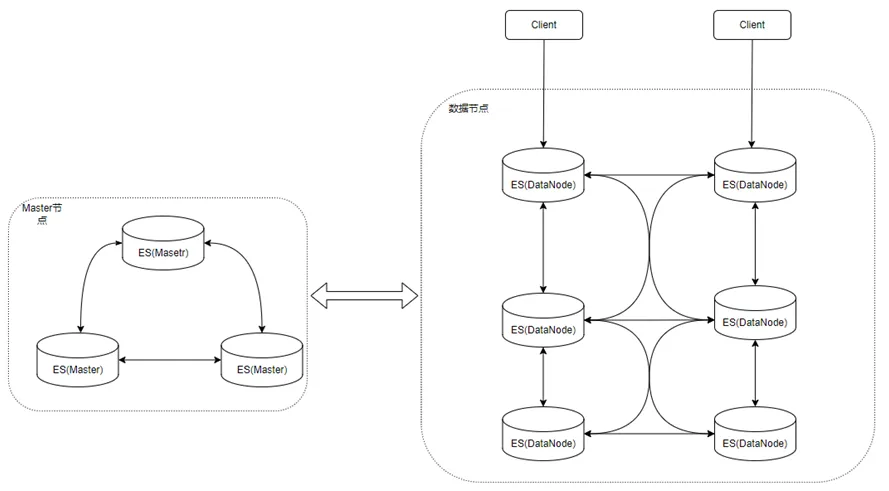
此处遇到问题是因心跳探测机制导致,因为节点是否正常服务需要master节点判断,而master节点判断依据即节点心跳是否正常,如果单节点不可达(如网络完全中断),目前ElasticSearch(6.x版本)判断超时时间为3*30s(3次30s心跳超时),即需要等待90s来才能够判断节点异常并从集群中移除,这段时间内ElasticSearch主shard和备shard之间请求会一直等待,则会导致上层业务侧会有约90s+超时抖动,如果再加上业务侧的请求重试,这期间失败率就可能比较高。目前针对这里的优化,包括两方面:
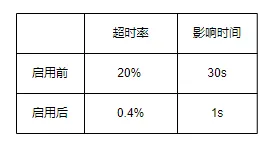
这里可以考虑进一步的优化是数据节点之间支持raft机制,即不完全依赖于master的存活探测,则在单节点有抖动(不完全异常)的情况,则数据节点自身可以支持majority分片成功即可返回而不用等待全部分片响应,提高了可用性。
其他涉及可用性优化项:
经过上述优化,ElasticSearch逐步满足了支付金融场景下对应安全、可用性等要求,符合业务的需求。不过由于ElasticSearch自身的复杂性,以及业务场景多样性和规模逐步大,可用性等优化还需要持续进行。
