

所属分类:web前端开发
什么是流?如何理解流?下面本篇文章就来带大家深入了解一下Nodejs中的流(Stream),希望对大家有所帮助!

stream 是一个抽象的数据接口,它继承了 EventEmitter,它能够发送/接受数据,本质就是让数据流动起来,如下图: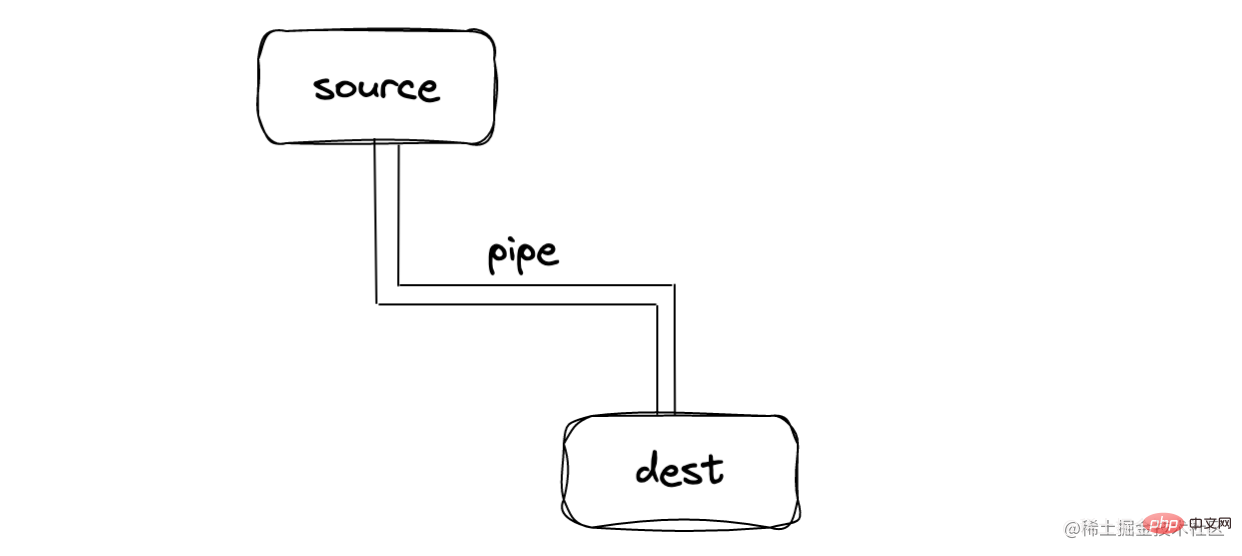
流不是 Node 中独有的概念,是操作系统最基本的操作方式,在 Linux 中 | 就是 Stream,只是 Node 层面对其做了封装,提供了对应的 API
首先使用下面的代码创建一个文件,大概在 400MB 左右 【相关教程推荐:nodejs视频教程】
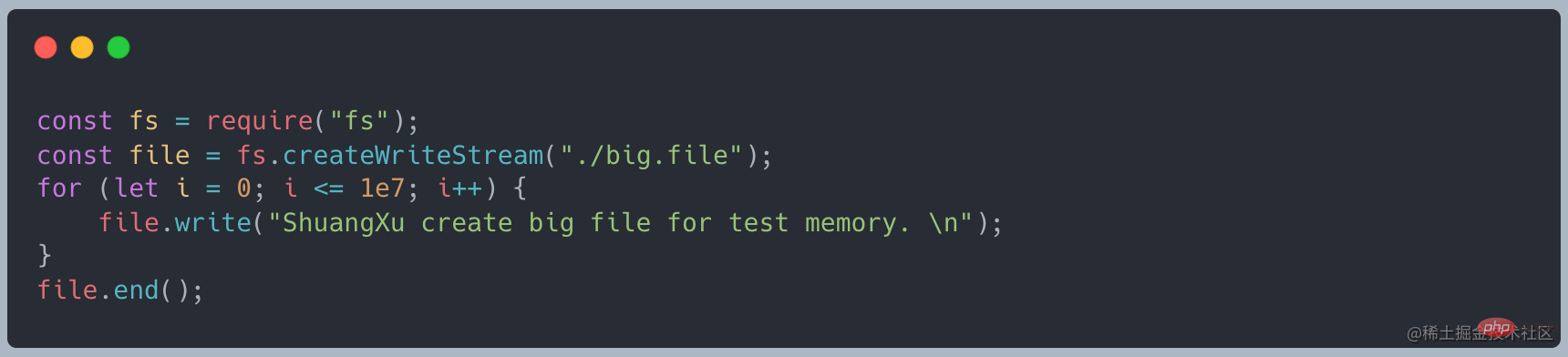
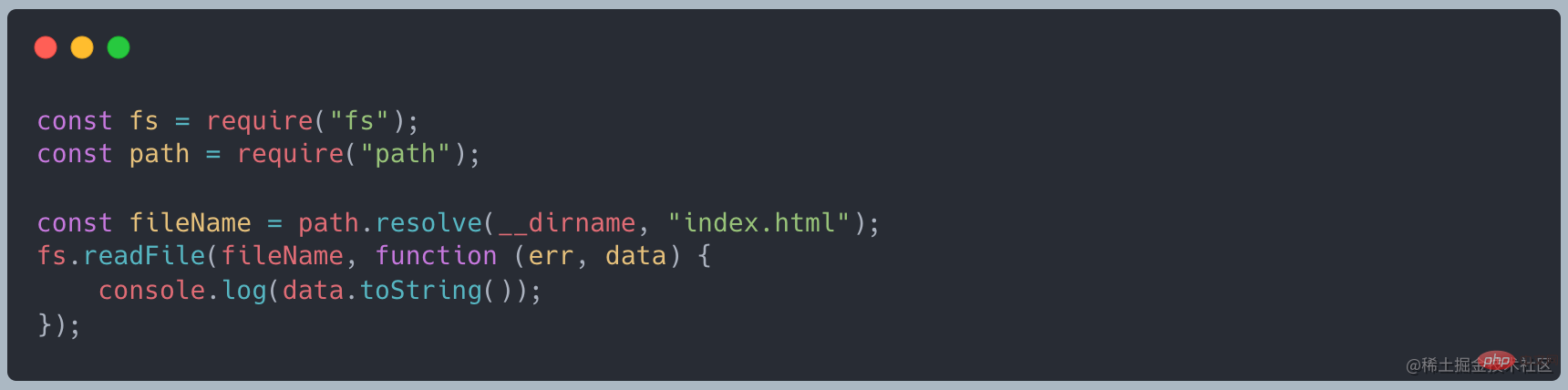
当我们使用 readFile 去读取的时候,如下代码
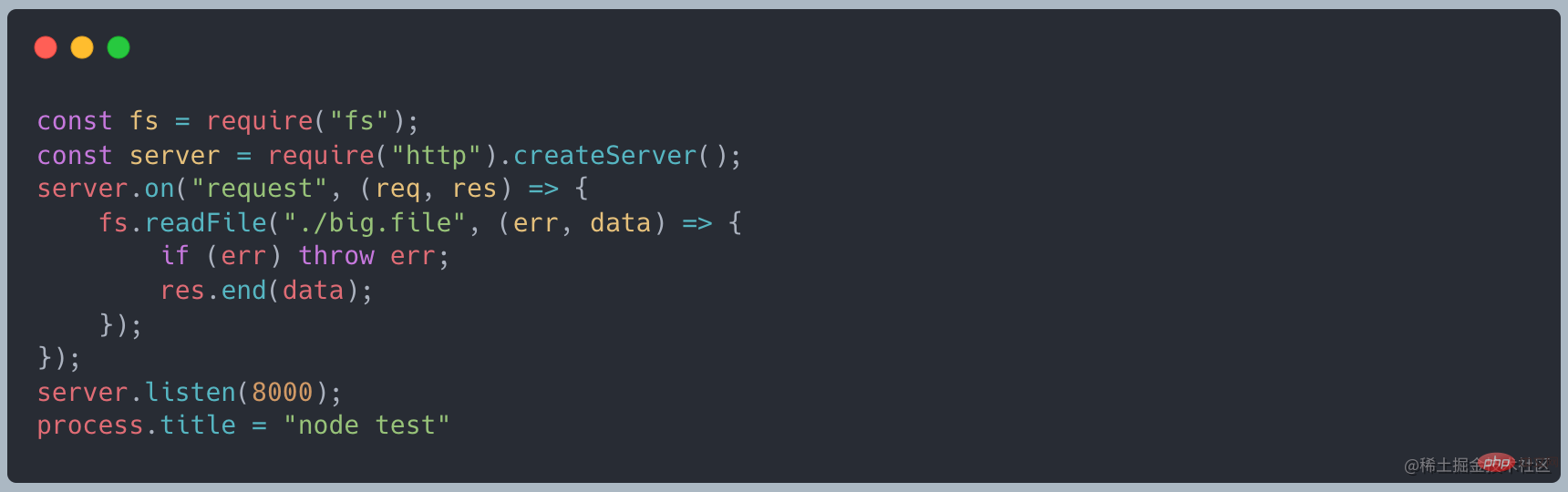
正常启动服务时,占用 10MB 左右的内存
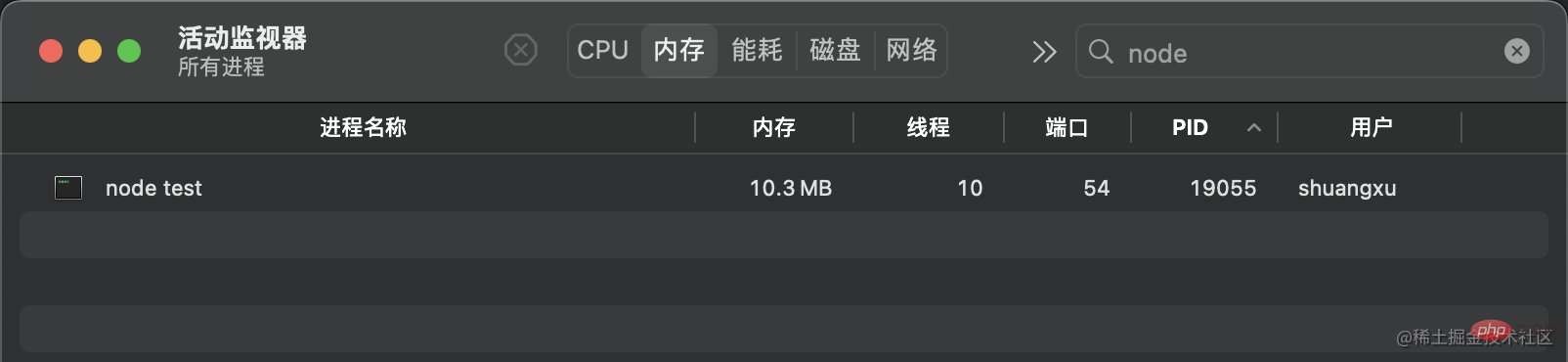
使用curl http://127.0.0.1:8000发起请求时,内存变为了 420MB 左右,和我们创建的文件大小差不多

改为使用使用 stream 的写法,代码如下
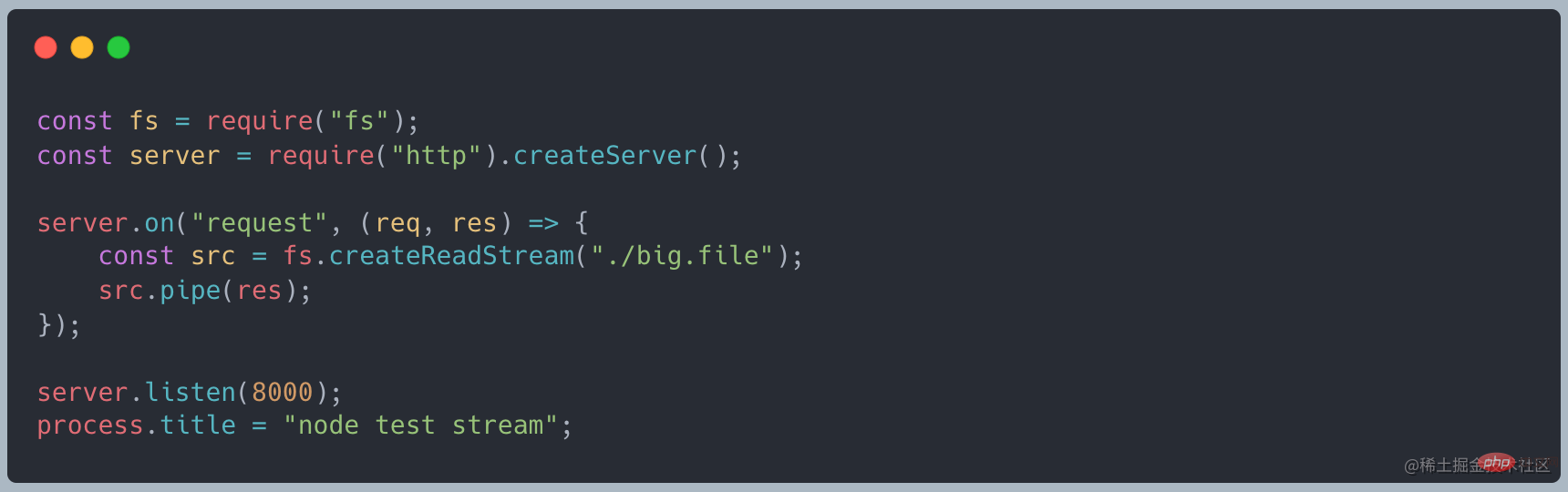
再次发起请求时,发现内存只占用了 35MB 左右,相比 readFile 大幅减少

如果我们不采用流的模式,等待大文件加载完成在操作,会有如下的问题:
总结来说就是,一次性读取大文件,内存和网络都吃不消
我们读取文件的时候,可以采用读取完成之后在输出数据
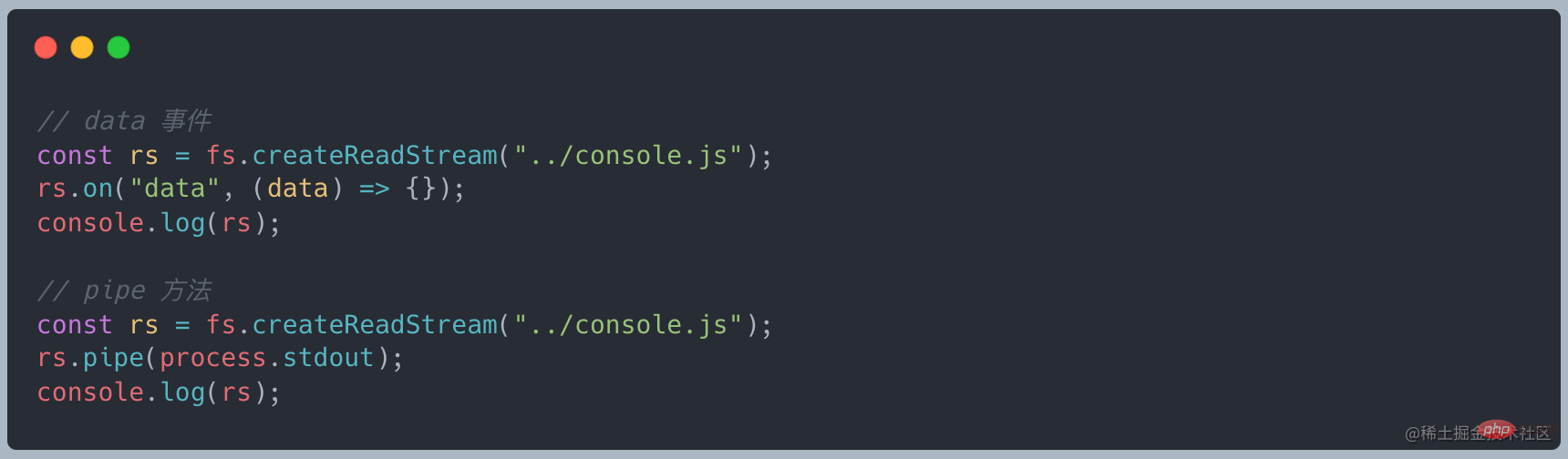
上述说到 stream 继承了 EventEmitter 可以是实现监听数据。首先将读取数据改为流式读取,使用 on("data", ()⇒{}) 接收数据,最后通过 on("end", ()⇒{}) 最后的结果
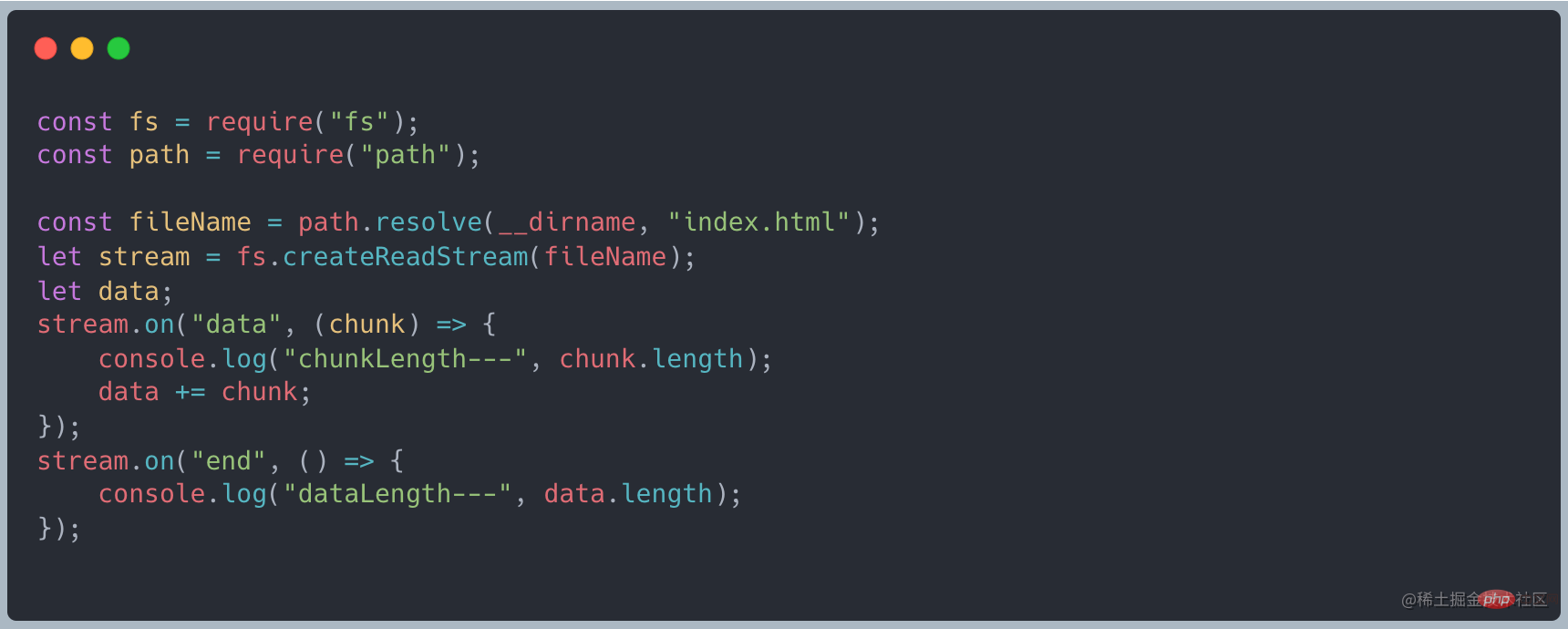
有数据传递过来的时候就会触发 data 事件,接收这段数据做处理,最后等待所有的数据全部传递完成之后触发 end 事件。
数据是从一个地方流向另一个地方,先看看数据的来源。
http 请求,请求接口来的数据
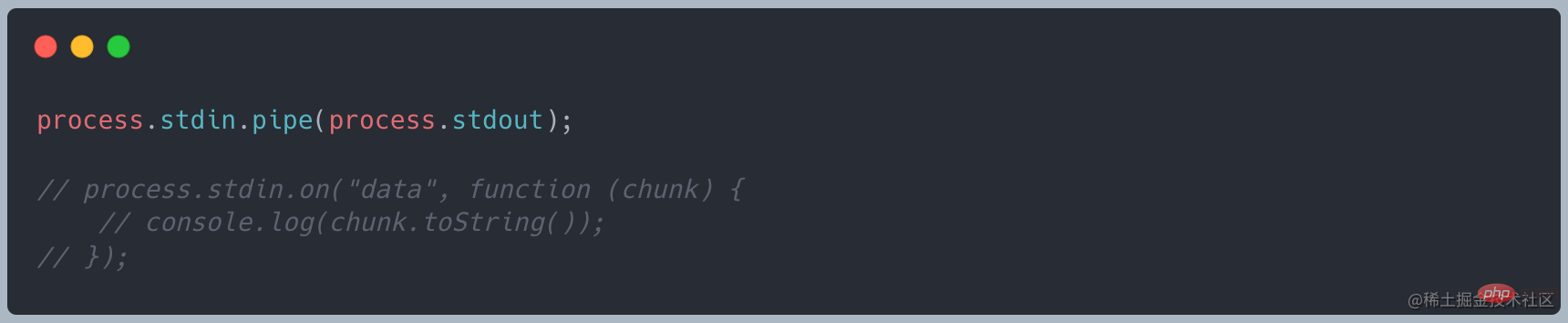
console 控制台,标准输入 stdin

file 文件,读取文件内容,例如上面的例子
在 source 和 dest 中有一个连接的管道 pipe,基本语法为 source.pipe(dest) ,source 和 dest 通过 pipe 连接,让数据从 source 流向 dest
我们不需要向上面的代码那样手动监听 data/end 事件.
pipe 使用时有严格的要求,source 必须是一个可读流,dest 必须是一个可写流
??? 流动的数据到底是一个什么东西?代码中的 chunk 是什么?
stream 常见的三种输出方式
console 控制台,标准输出 stdout
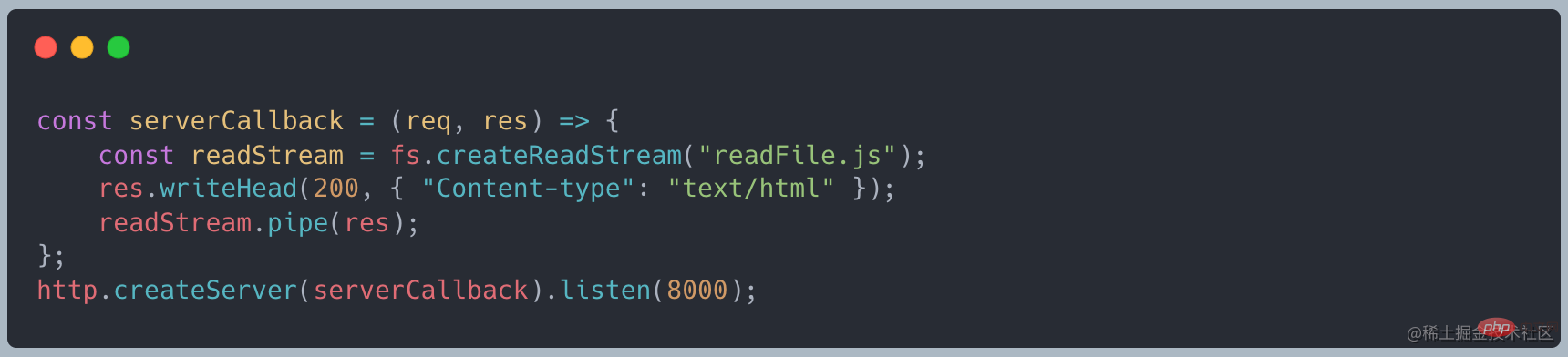
http 请求,接口请求中的 response
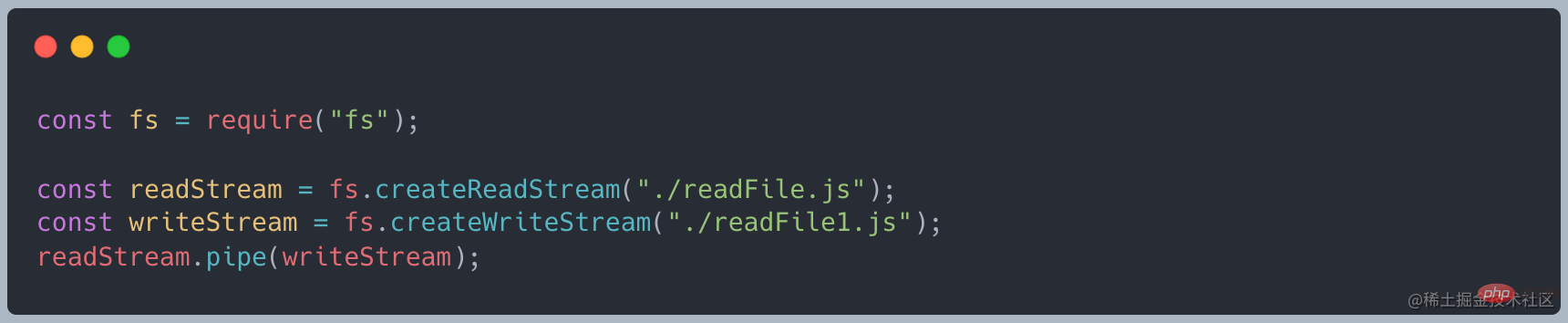
file 文件,写入文件

可读流是对提供数据的源头(source)的抽象
所有的 Readable 都实现了 stream.Readable 类定义的接口

? 读取文件流创建
fs.createReadStream 创建一个 Readable 对象
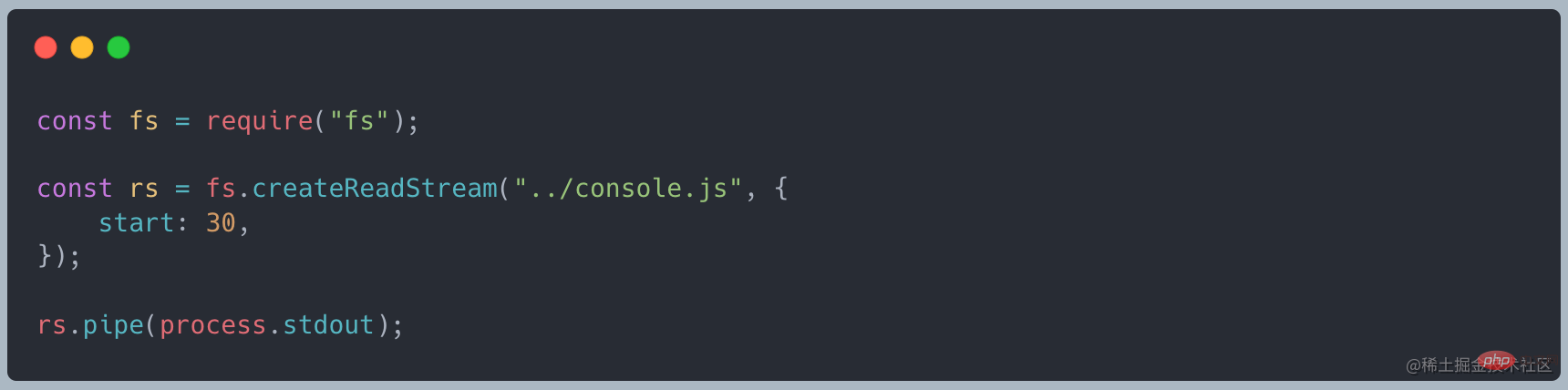
可读流有两种模式,流动模式(flowing mode)和暂停模式(pause mode),这个决定了 chunk 数据的流动方式:自动流动和手工流动
在 ReadableStream 中有一个 _readableState 属性,在其中有一个 flowing 的一个属性来判断流的模式,他有三种状态值:
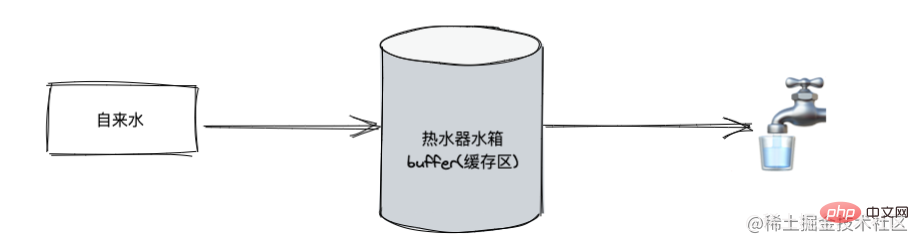
可以使用热水器模型来模拟数据的流动。热水器水箱(buffer 缓存区)存储着热水(需要的数据),当我们打开水龙头的时候,热水就会从水箱中不断流出来,并且自来水也会不断的流入水箱,这就是流动模式。当我们关闭水龙头时,水箱会暂停进水,水龙头则会暂停出水,这就是暂停模式。
数据自动地从底层读取,形成流动现象,并通过事件提供给应用程序。
监听 data 事件即可进入该模式
当 data 事件被添加后,可写流中有数据后会将数据推到该事件回调函数中,需要自己去消费数据块,如果不处理则该数据会丢失
调用 stream.pipe 方法将数据发送到 Writeable
调用 stream.resume 方法
数据会堆积在内部缓冲器中,必须显式调用 stream.read() 读取数据块
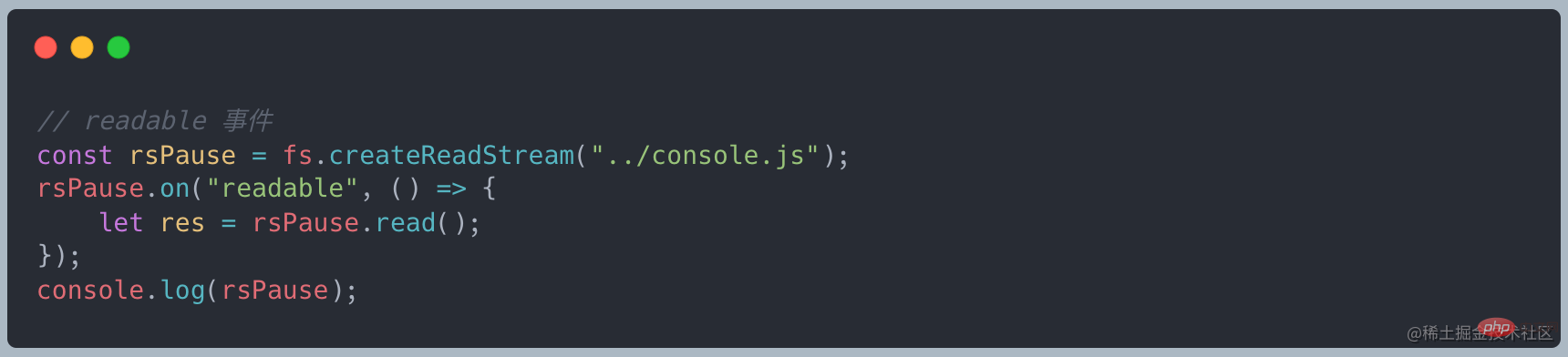
监听 readable 事件 可写流在数据准备好后会触发该事件回调,此时需要在回调函数中使用 stream.read() 来主动消费数据。readable 事件表明流有新的动态:要么有新的数据,要么流已经读取所有数据
可读流在创建完成之后处于初始状态 //TODO:和网上的分享不一致
暂停模式切换到流动模式
- 监听 data 事件
- 调用 stream.resume 方法
- 调用 stream.pipe 方法将数据发送到 Writable
登录后复制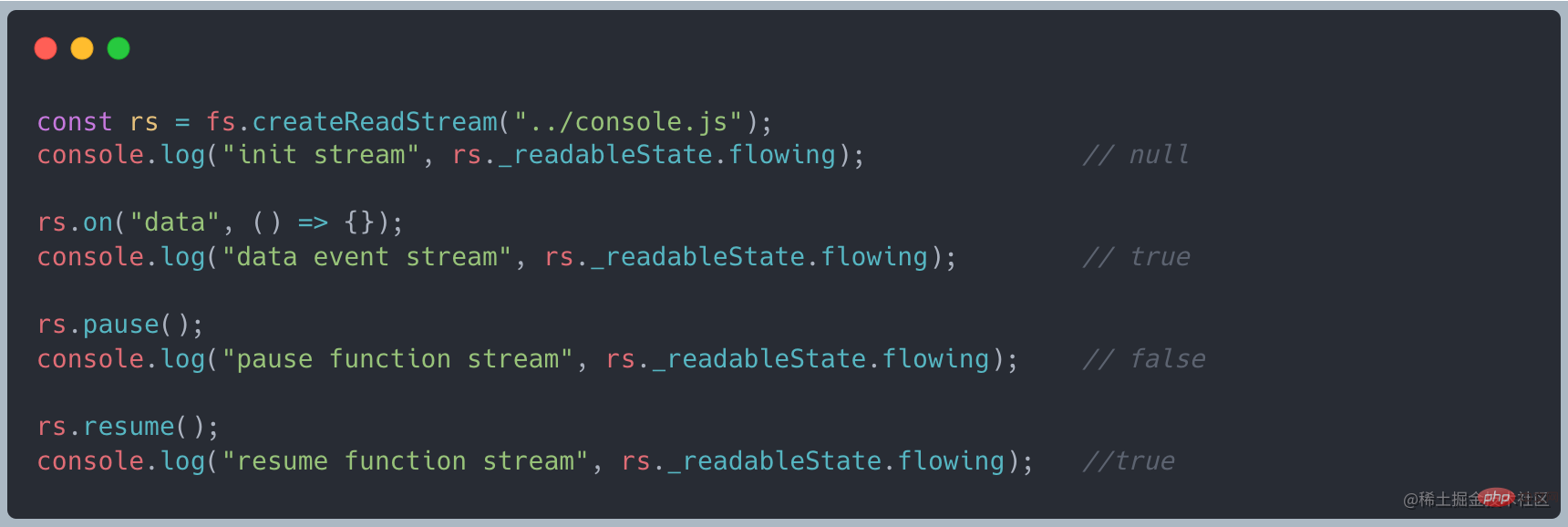
流动模式切换到暂停模式
- 移除 data 事件
- 调用 stream.pause 方法
- 调用 stream.unpipe 移除管道目标
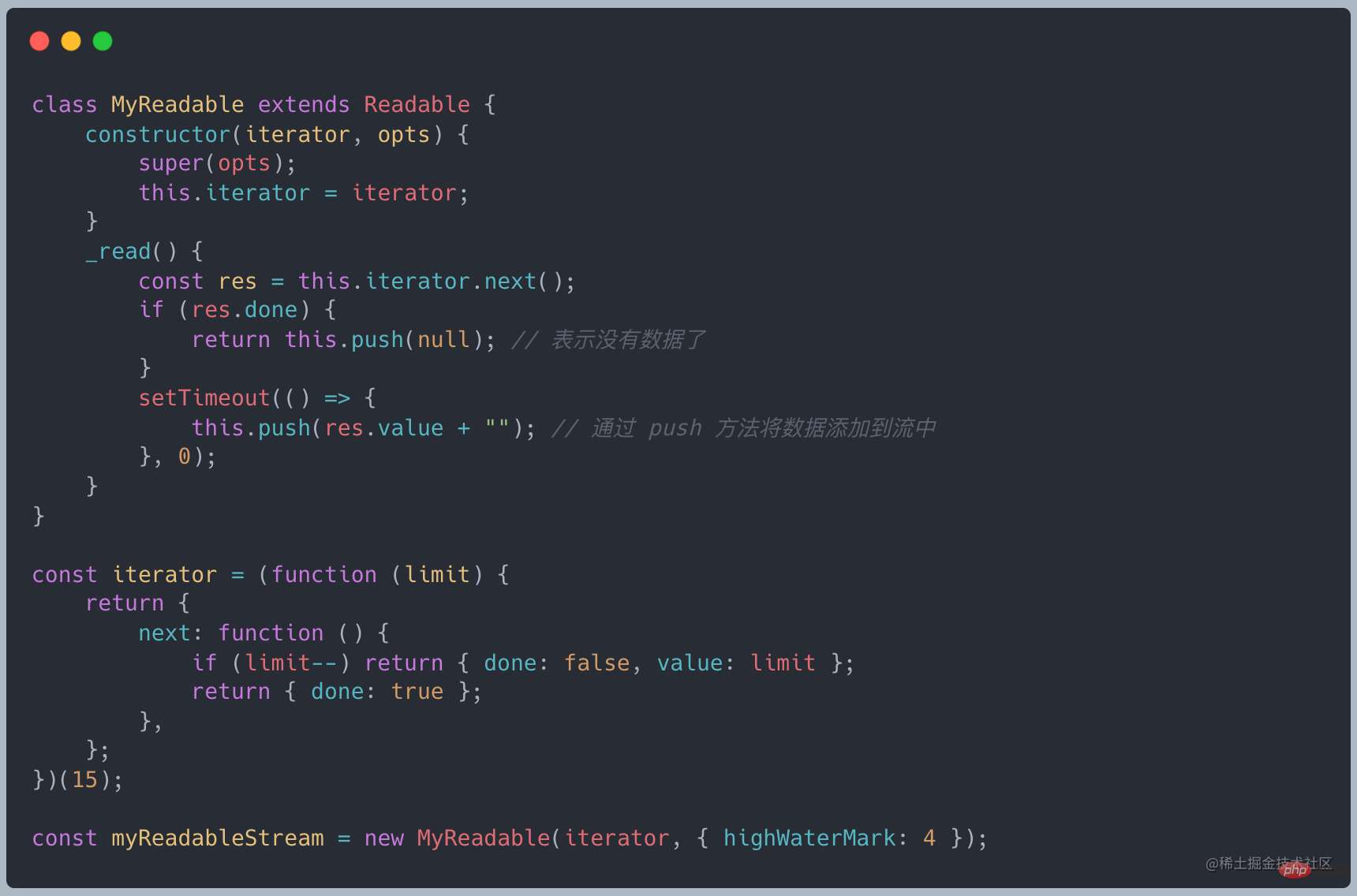
登录后复制创建可读流的时候,需要继承 Readable 对象,并且实现 _read 方法
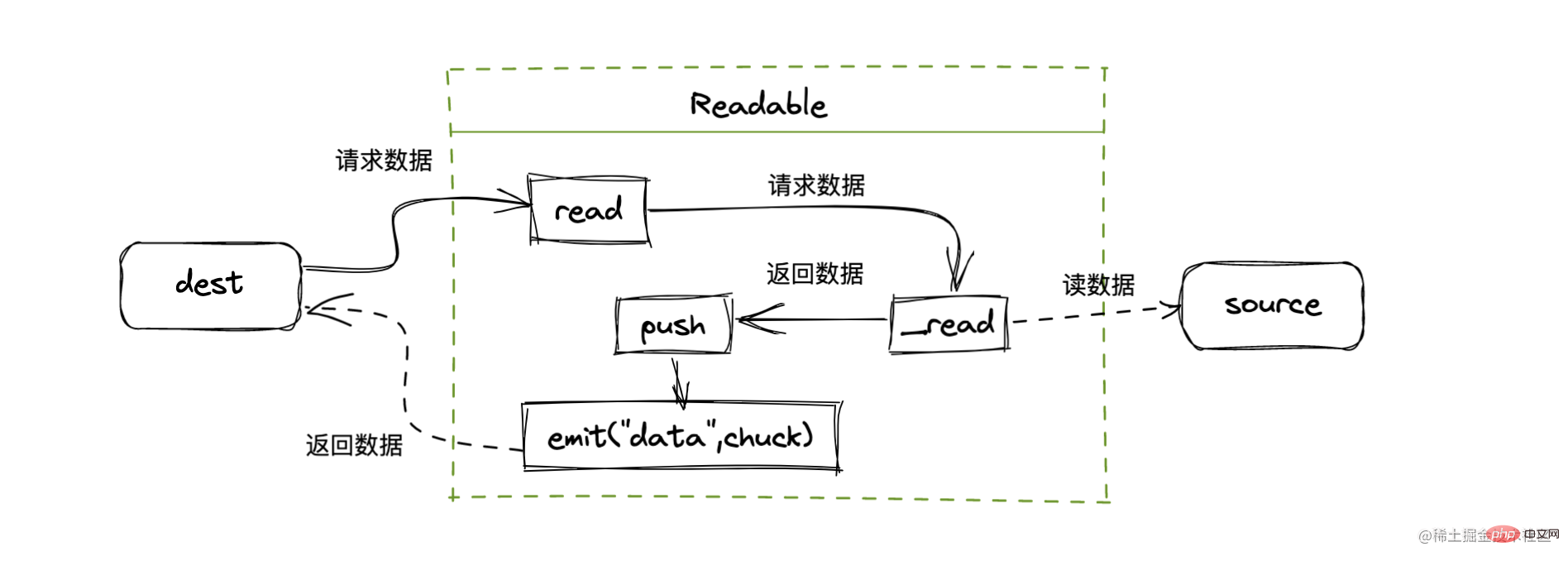
创建一个自定义可读流
当我们调用 read 方法时,整体的流程如下: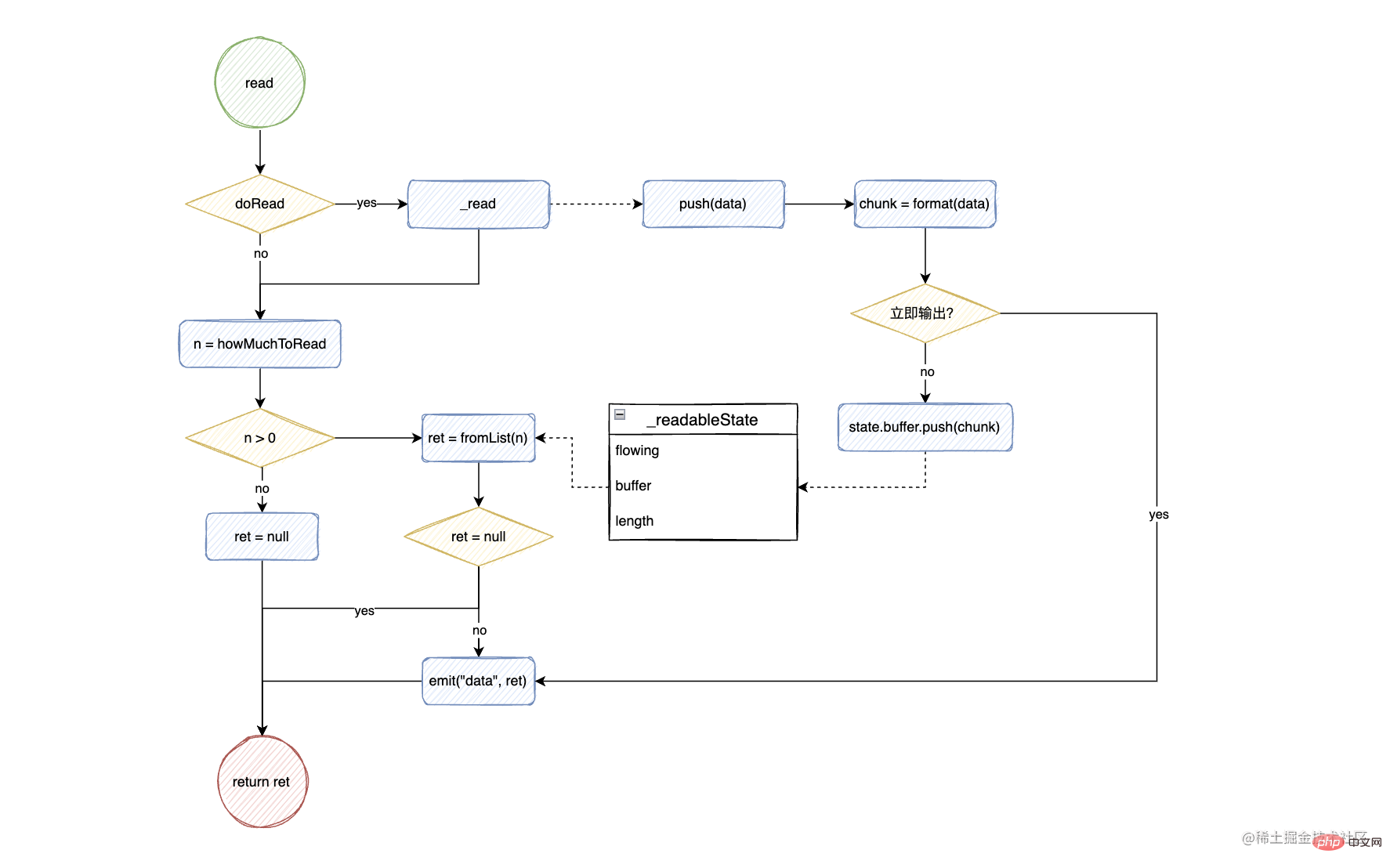
doRead
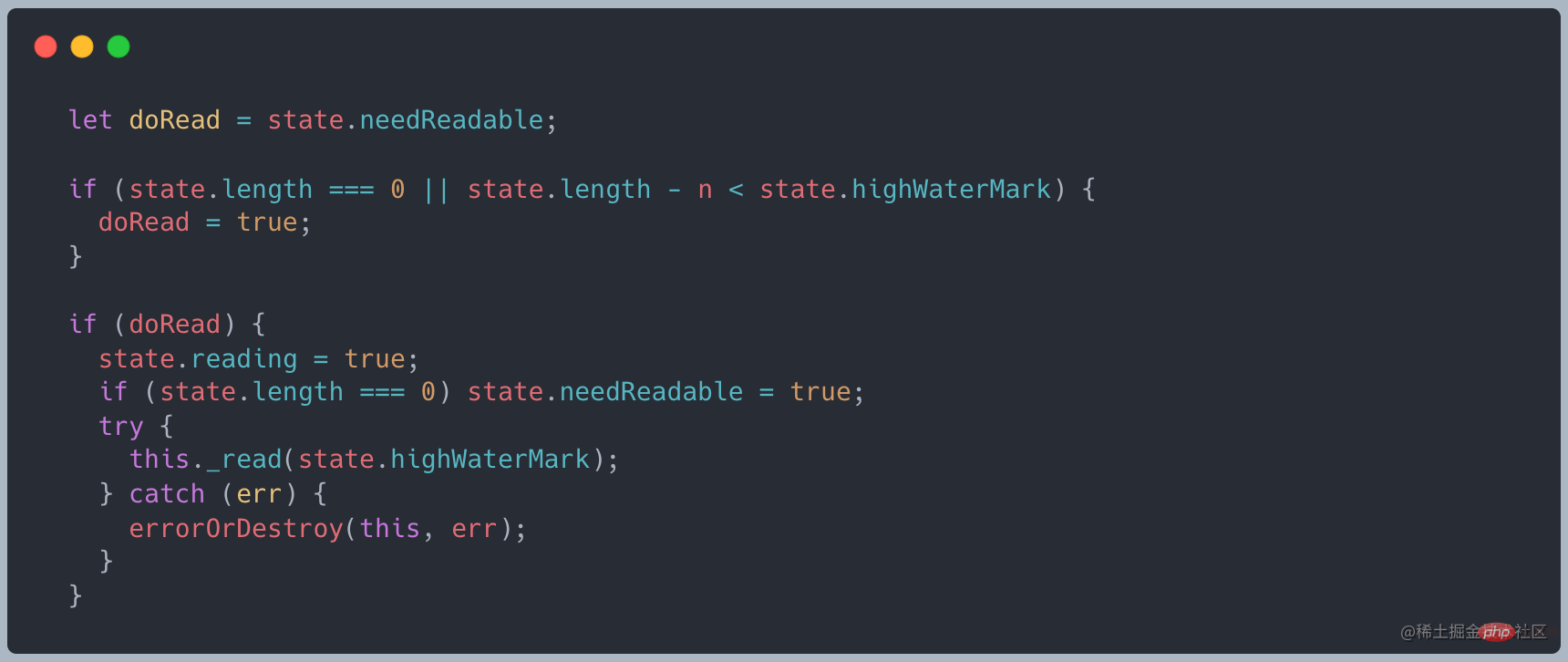
流中维护了一个缓存,当调用 read 方法的时候来判断是否需要向底层请求数据
当缓存区长度为0或者小于 highWaterMark 这个值得时候就会调用 _read 去底层获取数据 源码链接
可写流 是对数据写入目的地的一种抽象,是用来消费上游流过来的数据,通过可写流把数据写入设备,常见的写入流就是本地磁盘的写入

通过 write 写入数据
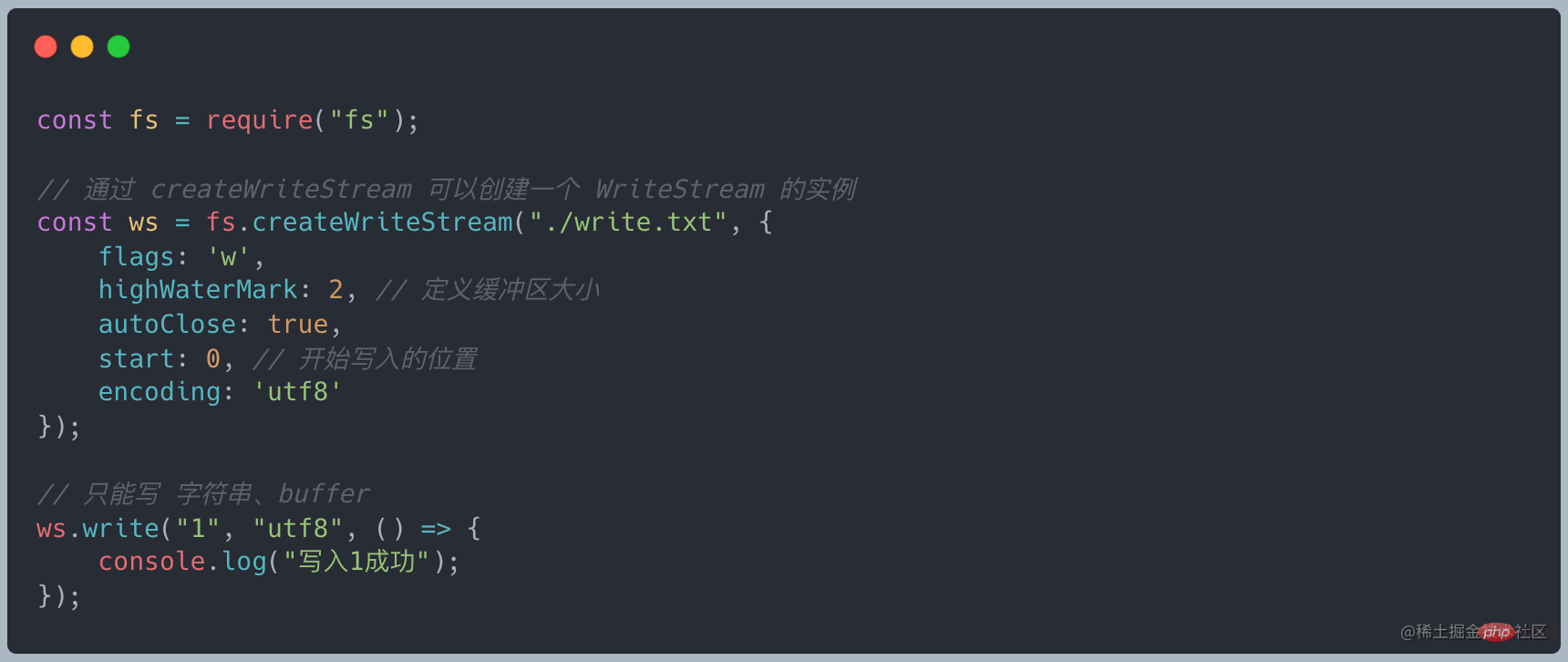
通过 end 写数据并且关闭流,end = write + close

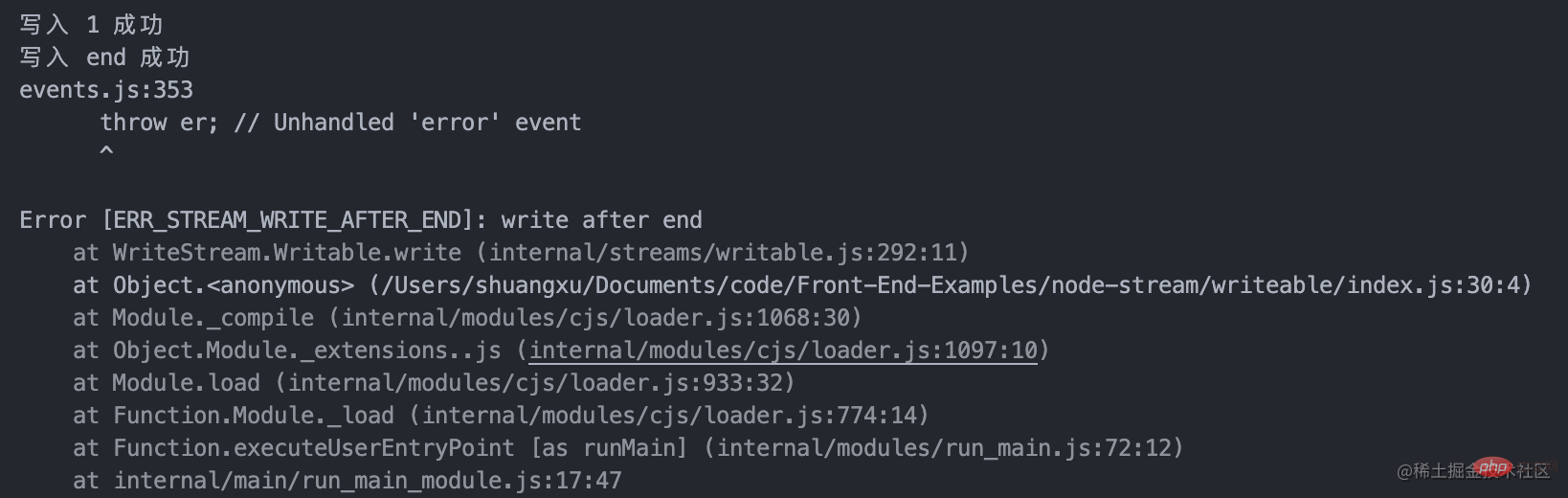
当写入数据达到 highWaterMark 的大小时,会触发 drain 事件
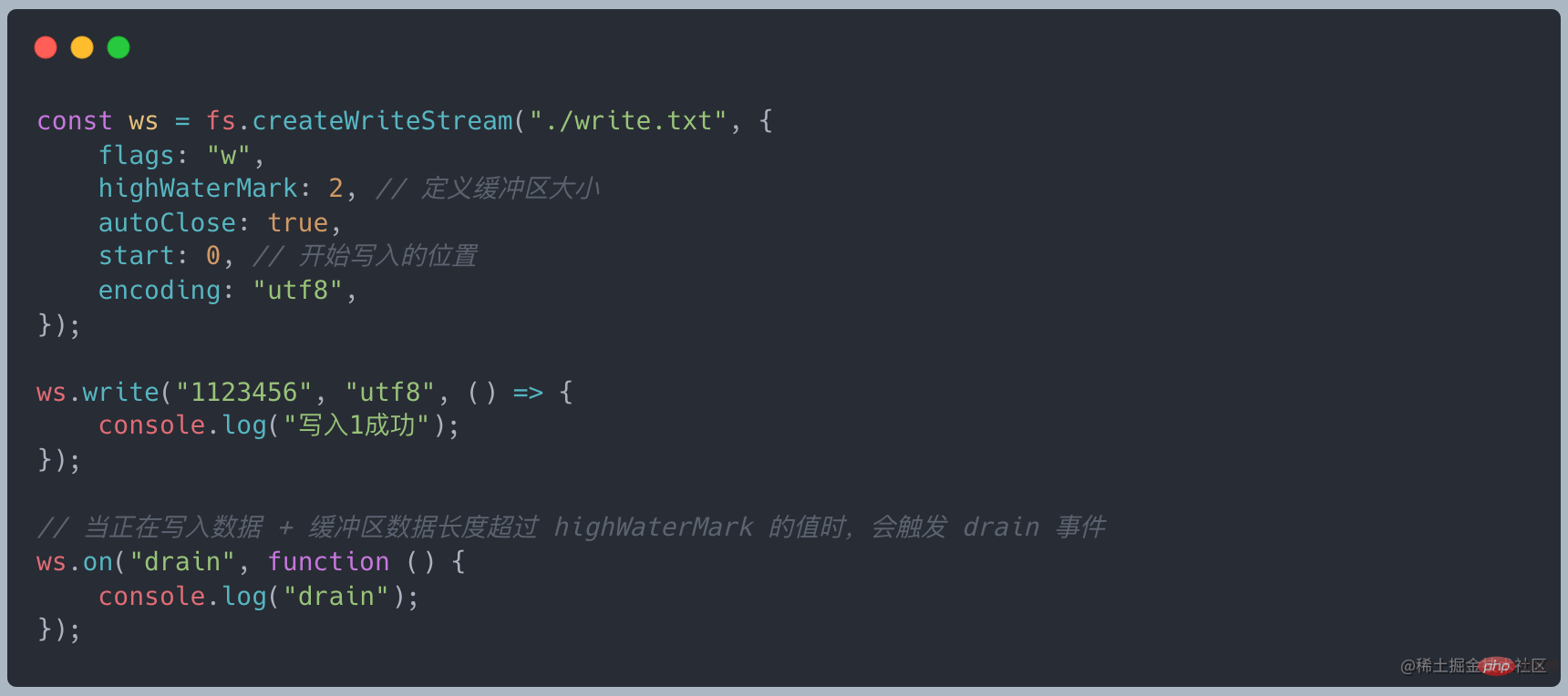
调用 ws.write(chunk) 返回 false,表示当前缓冲区数据大于或等于 highWaterMark 的值,就会触发 drain 事件。其实是起到一个警示作用,我们依旧可以写入数据,只是未处理的数据会一直积压在可写流的内部缓冲区中,直到积压沾满 Node.js 缓冲区后,才会被强行中断
所有的 Writeable 都实现了 stream.Writeable 类定义的接口
只需要实现 _write 方法就能够将数据写入底层
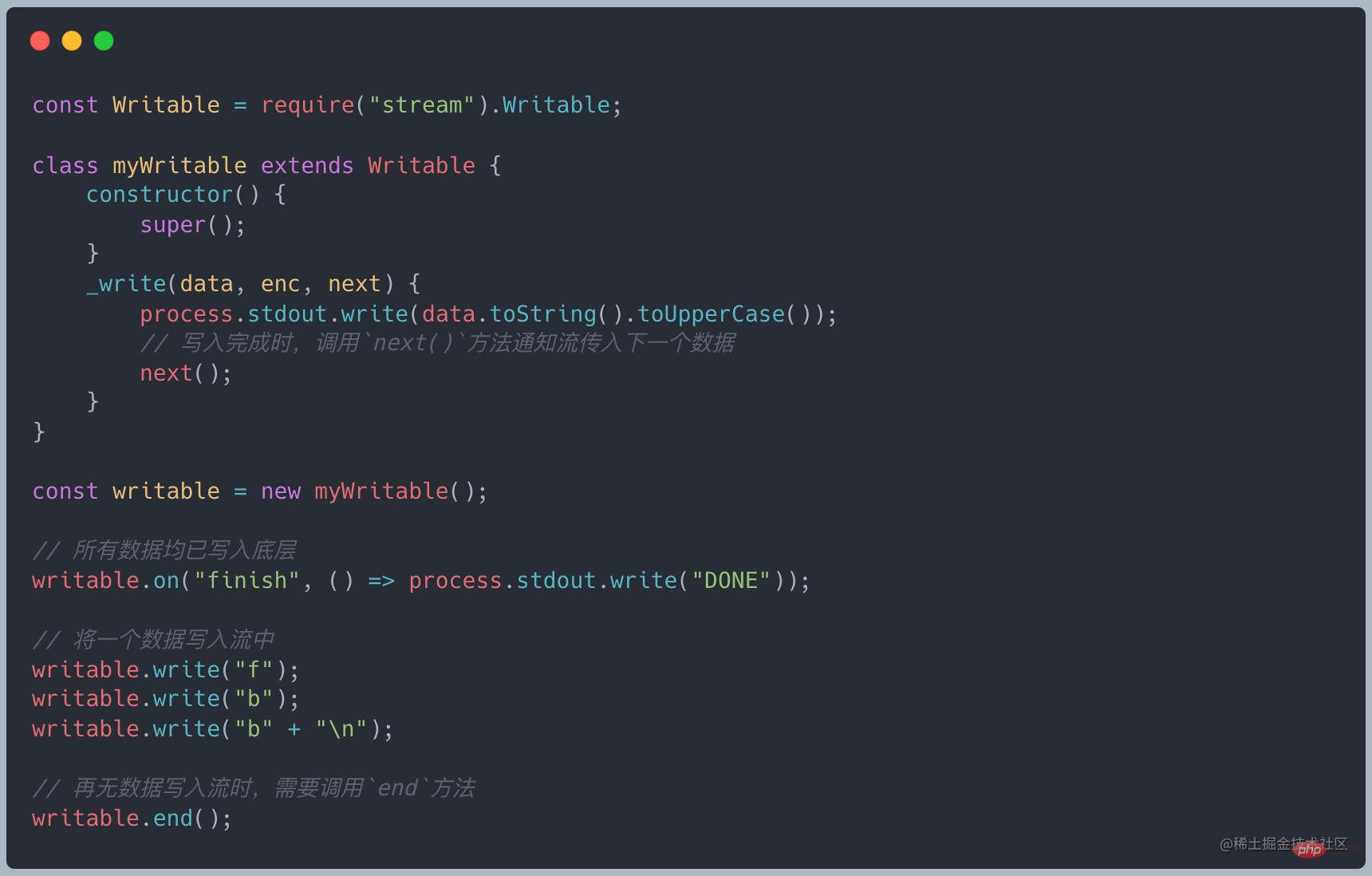
双工流,既可读,也可写。实际上继承了 Readable 和 Writable 的一种流,那它既可以当做可读流来用又可以当做可写流来用
自定义的双工流需要实现 Readable 的 _read 方法和 Writable 的 _write 方法
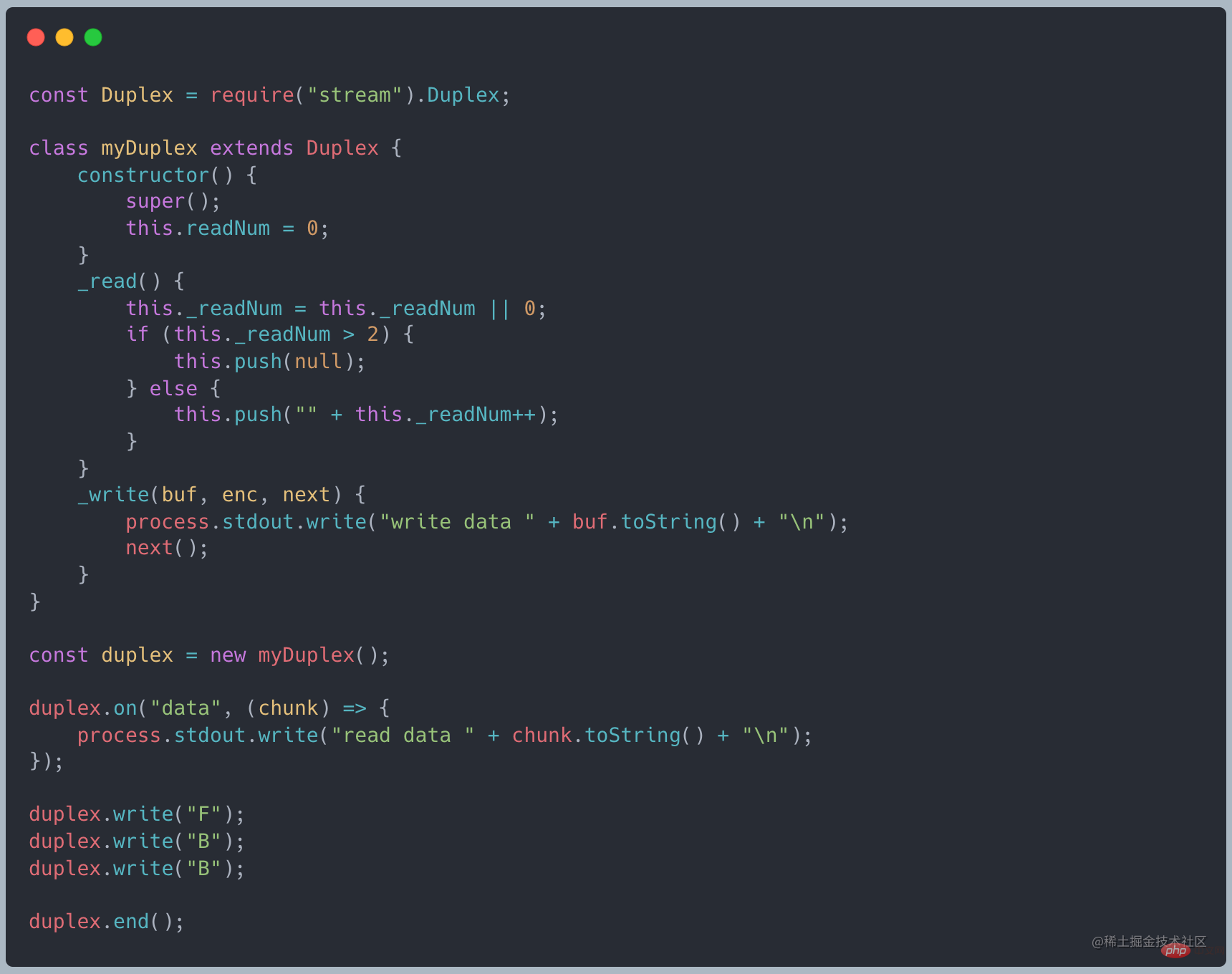
net 模块可以用来创建 socket,socket 在 NodeJS 中是一个典型的 Duplex,看一个 TCP 客户端的例子
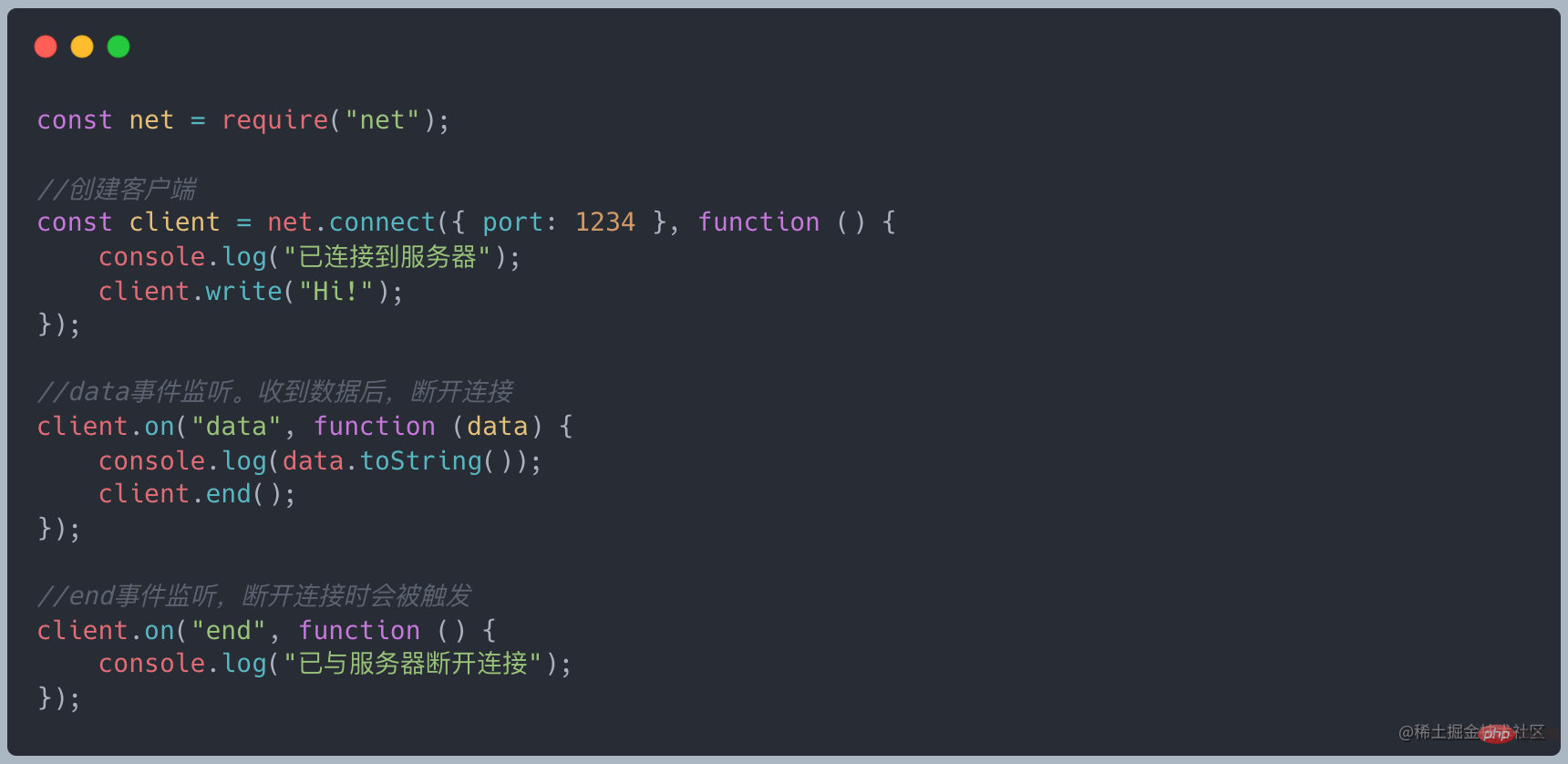
client 就是一个 Duplex,可写流用于向服务器发送消息,可读流用于接受服务器消息,两个流内的数据并没有直接的关系
上述的例子中,可读流中的数据(0/1)和可写流中的数据(’F’,’B’,’B’)是隔离的,两者并没有产生关系,但对于 Transform 来说在可写端写入的数据经过变换后会自动添加到可读端。
Transform 继承于 Duplex,并且已经实现了 _write 和 _read 方法,只需要实现 _tranform 方法即可
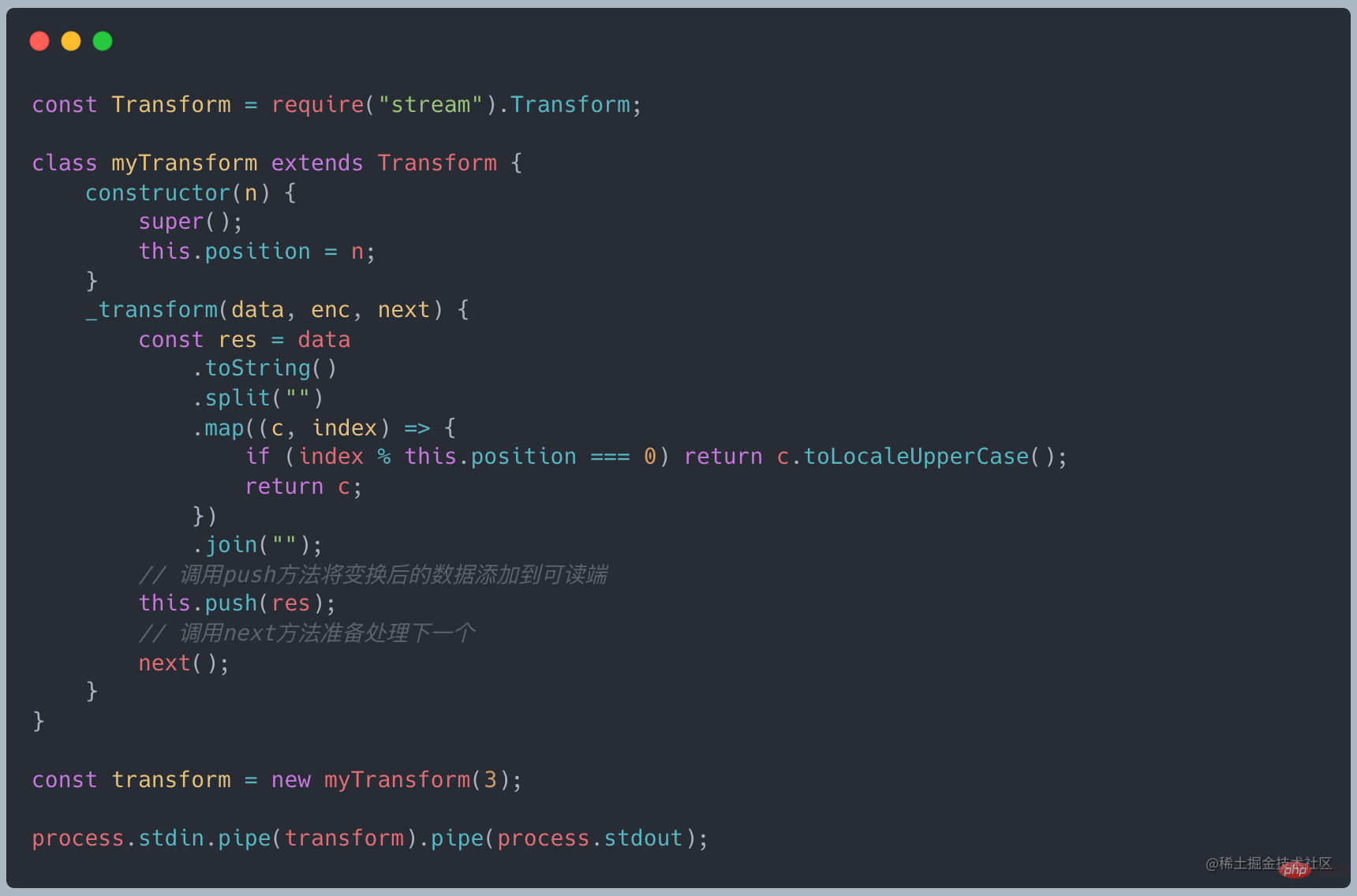
gulp 基于 Stream 的自动化构建工具,看一段官网的示例代码
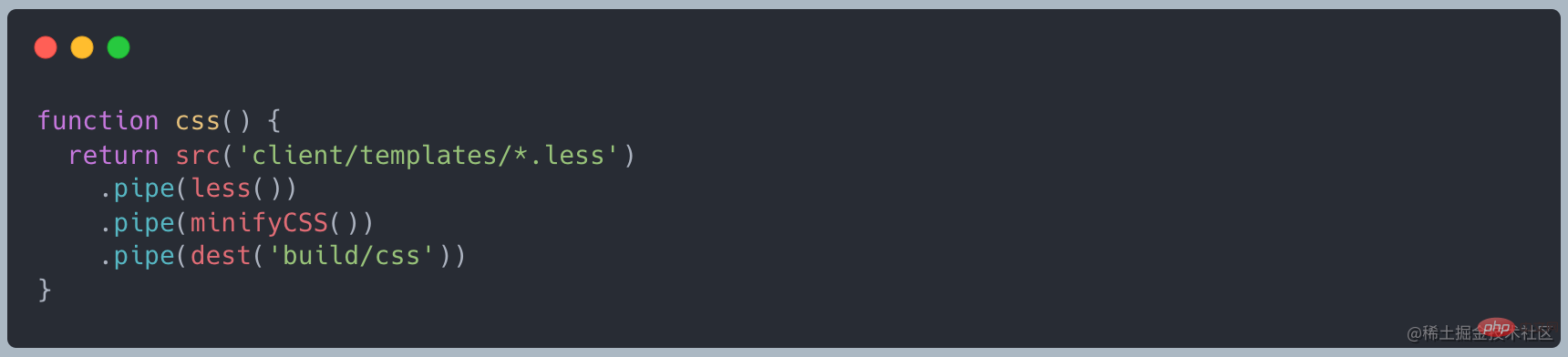
less → less 转为 css → 执行 css 压缩 → 压缩后的 css
其实 less() 和 minifyCss() 都是对输入的数据做了一些处理,然后交给了输出数据
Duplex 和 Transform 的选择
和上面的示例对比起来,我们发现一个流同时面向生产者和消费者服务的时候我们会选择 Duplex,当只是对数据做一些转换工作的时候我们便会选择使用 Tranform
背压问题来源于生产者消费者模式中,消费者处理速度过慢
比如说,我们下载过程,处理速度为3Mb/s,而压缩过程,处理速度为1Mb/s,这样的话,很快缓冲区队列就会形成堆积
要么导致整个过程内存消耗增加,要么导致整个缓冲区慢,部分数据丢失
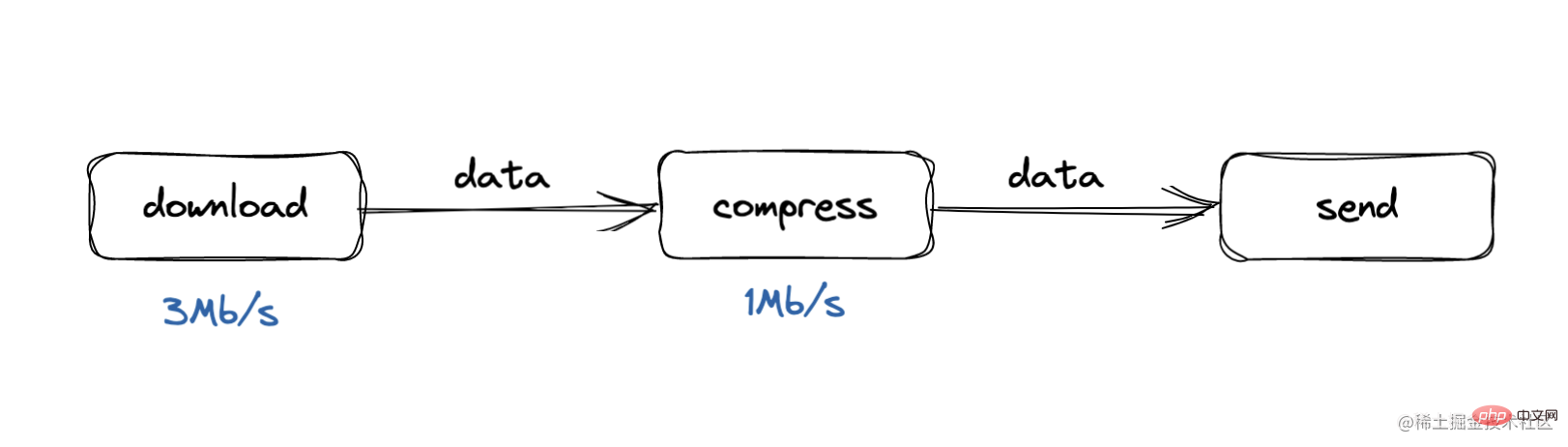
背压处理可以理解为一个向上”喊话”的过程
当压缩处理发现自己的缓冲区数据挤压超过阈值的时候,就对下载处理“喊话”,我忙不过来了,不要再发了
下载处理收到消息就暂停向下发送数据
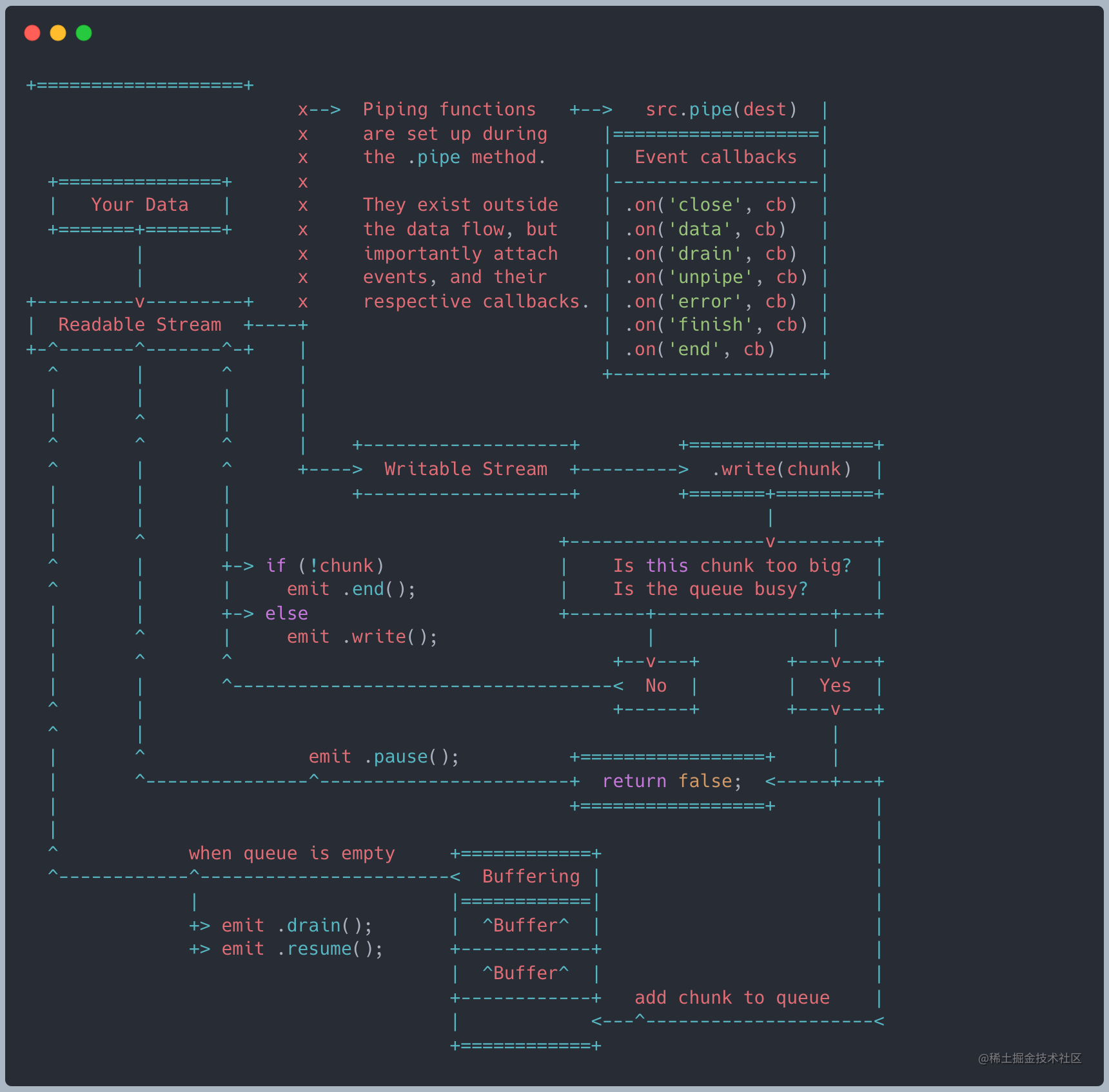
我们有不同的函数将数据从一个进程传入另外一个进程。在 Node.js 中,有一个内置函数称为 .pipe(),同样地最终,在这个进程的基本层面上我们有二个互不相关的组件:数据的_源头_,和_消费者_
当 .pipe() 被源调用之后,它通知消费者有数据需要传输。管道函数为事件触发建立了合适的积压封装
在数据缓存超出了 highWaterMark 或者写入的列队处于繁忙状态,.write() 会返回 false
当 false 返回之后,积压系统介入了。它将暂停从任何发送数据的数据流中进入的 Readable。一旦数据流清空了,drain 事件将被触发,消耗进来的数据流
一旦队列全部处理完毕,积压机制将允许数据再次发送。在使用中的内存空间将自我释放,同时准备接收下一次的批量数据
我们可以看到 pipe 的背压处理:
更多node相关知识,请访问:nodejs 教程!
以上就是深入浅析Node中的Stream(流)的详细内容,更多请关注zzsucai.com其它相关文章!
