

所属分类:web前端开发

前端(vue)入门到精通课程:进入学习
Apipost = Postman + Swagger + Mock + Jmeter 超好用的API调试工具:点击使用
【相关推荐:javascript视频教程、web前端】
经过前几篇文章的学习,对DOM有一定的了解。但这仅仅是DOM一些基础性的知识,如果要对DOM更了解,需要更深入地了解DOM节点。在这一节中,咱们将围绕DOM的节点属性、标签和内容来展开。这样我们就可以更进一步的了解它们是什么?以及它们最常的属性。
DOM节点的属性取决于它们的类(class)。例如,<a>标签对应的是一个元素节点和链接a相关的属性。文本节点与元素节点不一样,但是它们之间也有相同的属性和方法,因为所有的DOM节点会形成一个DOM树。
每个DOM节点属于相应的内置类。
root是DOM树的EventTarget,它是由Node继承的,而其他DOM节点继承它。
下图可以帮助我们更易于理解:
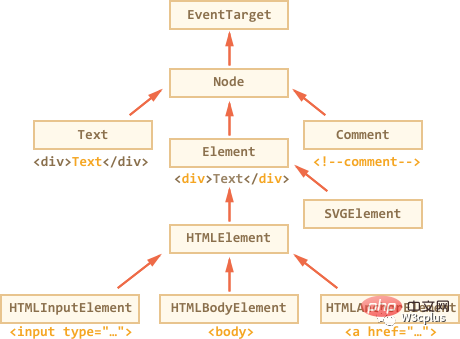
DOM节点的类主要有:
EventTarget:是root抽象类(Abstract Class)。该类的对象永远不会创建。它作为一个基础,因此所有的DOM节点都支持所谓的事件(Events),稍后会涉及这个
Node:也是一个抽象类,作为DOM节点的基础。它提供了核心功能:parentNode、nextSibling、childNodes等(它们是getter)。节点类的对象没有被创建。但是,有一些具体的节点类继承了它,比如:文本节点的Text,元素节点的Element以及注释节点的Comment等
Element:是DOM元素的基本类。它提供了元素级的搜索,比如nextElementSibling、childern、getElementsByTagName、querySelector等。在浏览器中,不仅有HTML,还有XML和SVG文档。元素类是更具体类的一些基础,比如SVGElement、XMLElement和HTMLElement
HTMLElement:是HTML元素的基本类,它由各种HTML元素继承。比如HTMLInputElemnt(对应input元素的类)、HTMLBodyElement(对应body元素的类)和HTMLAnchorElement(对应a元素的类)等
对于
HTMLElement类,还有很多其它种,比如下图所示的这些。
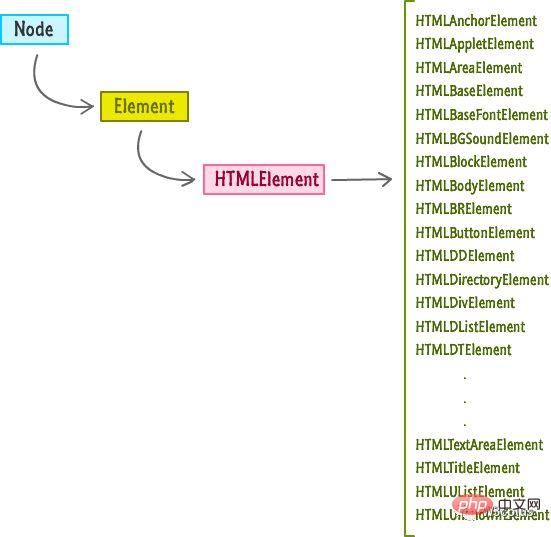
因此,节点的全部属性和方法都是继承的结果!
例如,DOM对象中的<input>元素。它属于HTMLElement类中的HTMLInputElement类。它将属性和方法叠加在一起:
HTMLInputElement:提供了input指定的属性
HTMLElement:它提供常用的HTML元素方法(getter和setter)
Element:提供元素通用方法
Node:提供公共的DOM节点属性
EventTarget:提供对事件的支持(覆盖)
最后它继承了Object的方法(纯对象),比如hasOwnProperty
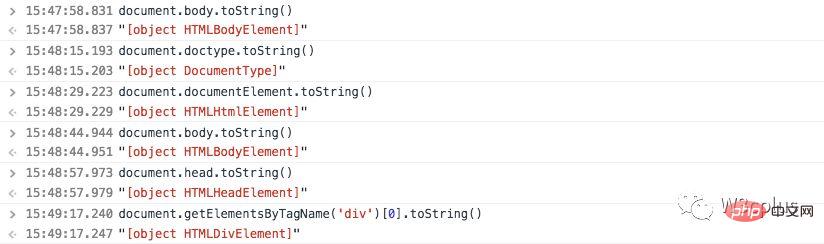
如果我们想查DOM节点类名,可以使用对象常用的constructor属性。它引用类构造函数,可以使用constructor.name来获取它的name。比如:

或者使用toString把它串起来,比如:
我们还可以使用instanceof来检查继承关系:

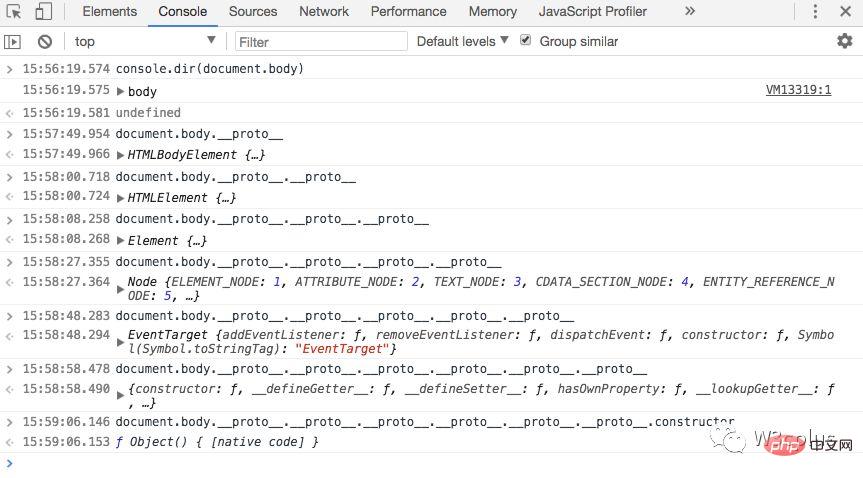
正如我们所看到的,DOM节点是常规的JavaScript对象。他们使用基于原型的类来继承。
在浏览器中使用console.dir(elem)输出元素也很容易。在控制台可以看到HTMLElement.prototype、Element.prototype等等。
在浏览器和DOM一节中,我们知道浏览器会根据DOM模型,将HTML文档解析成一系列的节点,再由这些节点组成一个DOM树。在DOM中的最小组成单位叫做节点(Node),DOM树由12种类型的节点组成。
DOM中的Node至少拥有
nodeType、nodeName和nodeValue这三个基本属性。节点类型不同,这三个属性的值也会不相同。
nodeType:该属性返回节点类型的常数值。不同的类型对应不同的常数值,12种类型分别对应1到12的常数值,如下面的表格所示
nodeName:该属性返回节点的名称
nodeValue:该属性返回或设置当前节点的值,格式为字符串
nodeType节点类型:
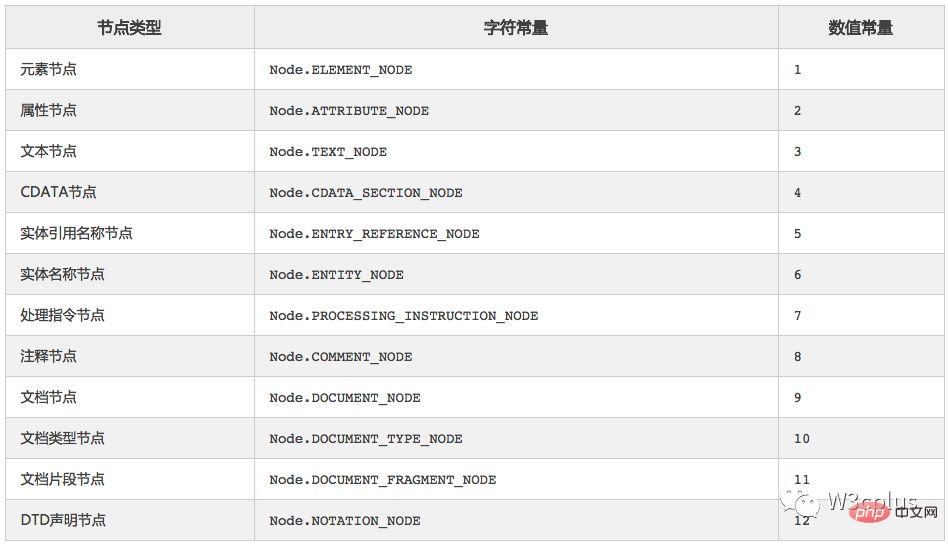
而其中元素节点、文本节点和属性节点是我们操作DOM最常见的几种节点类型。
在JavaScript中,我们可以使用instanceof和其他基于类的测试来查看节点类型,但是有时候nodeType可能更简单。

而nodeType是只能属性,我们不能修改它。

前面提到过nodeName将会返回节点名称(返回的是HTML标签,并且是大写的)。也就是说,给定的DOM节点,可以通过nodeName属性读取它的标签名称,比如:
document.body.nodeName
// => BODY
登录后复制除了nodeName属性之外,还可以通过tagName属性来读取:
document.body.tagName
// => BODY
登录后复制虽然nodeName和tagName都能读取到元素标签名,但两者之间有区别吗?当然,两者之间有略微的差异:
tagName属性只能用于元素节点(Element)
nodeName属性可以用于任意节点(Node)上,如果用于元素上,那么和tagName相同,如果用于其他节点类型,比如文本、注释节点等,它有一个带有节点类型的字符串
也就是说,tagName只支持元素节点(因为它源于Element类),而nodeName可以用于所有节点类型。比如下面这个示例,来比较一下tagName和nodeName的结果:
如果我们只处理DOM元素,那么我们就可以选择tagName属性来做相应的处理。
除了XHTML,标签名始终是大写的。浏览器有两种处理文档的模式:HTML和XML。通常HTML模式用于Web页面。当浏览器接收到一个带有
Content-Type:application/xml+xhtml的头,就会启用XML模式。在HTML模式中,tagName或者nodeName总是返回大写标签,比如<body>或<BoDy>返回的是BODY;对于XML模式,现在很少使用了。
对于DOM节点的内容,JavaScript中提供了几个方法来对其进行操作,比如innerHTML、outerHTML、textContent、innerText、outerText和nodeValue等。接下来,咱们看看他们的使用场景以及相应的差异性。
为了易于帮助大家理解和掌握这向方法的使用,接下来的示例都将围绕着下面这个DOM结构来做处理:
<body>
<!-- 主内容 -->
<div id="main">
<p>The paragraph element</p>
<div>The div </div>
<input type="text" id="name" value="User name" />
</div>
</body>
登录后复制innerHTMLinnerHTML属性允许我们获取元素的HTML,而且其获取的的值是一个String类型。比如:
let ele = document.getElementById('main')
let eleContent = ele.innerHTML; console.log(typeof eleContent, eleContent)登录后复制输出的结果如下:

上面看到的是innerHTML属性获取某个元素的内容,当然innerHTML也可以修改某个元素的内容。比如:
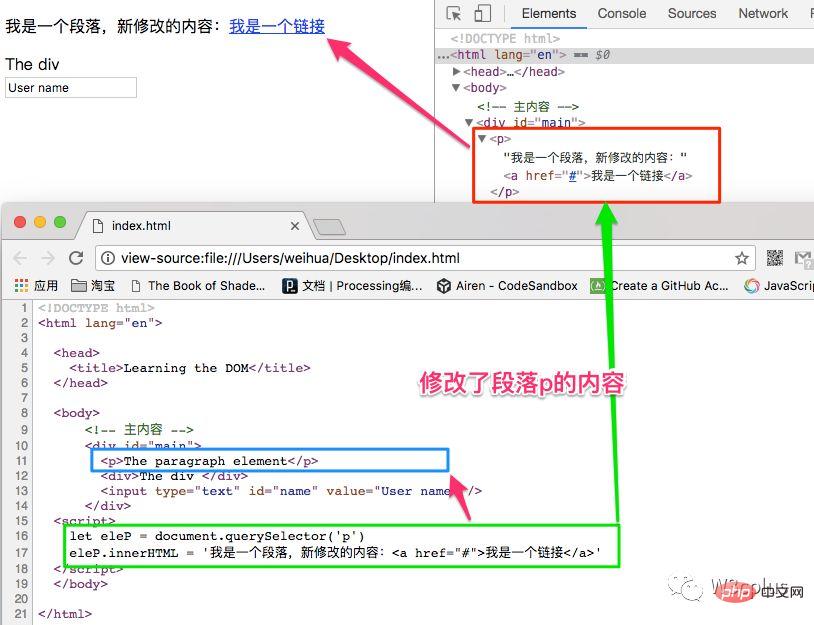
let eleP = document.querySelector('p') eleP.innerHTML = '我是一个段落,新修改的内容:<a href="#">我是一个链接</a>'登录后复制刷新页面,段落p元素整个内容都将被修改了:
如果使用
innerHTML将<script>标签插入到document,它不会被执行。
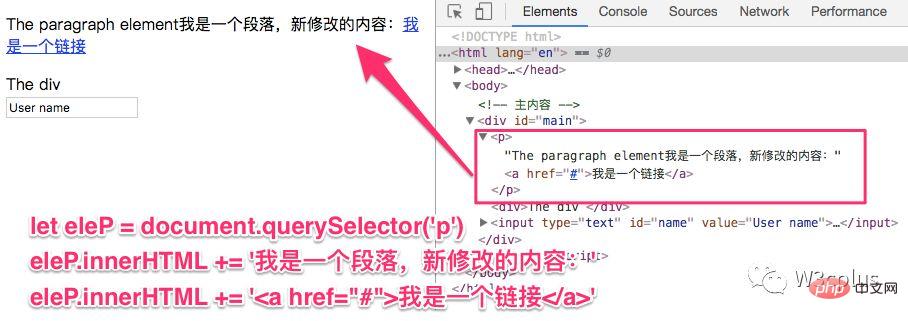
使用innerHTML可以使用ele.innerHTML += "something"来追回更多的HTML,比如下面这个示例:
let eleP = document.querySelector('p') eleP.innerHTML += '我是一个段落,新修改的内容:' eleP.innerHTML += '<a href="#">我是一个链接</a>'登录后复制结果如下:
使用innerHTML要非常小心,因为它做的不是加法,而是完整的覆盖。还有:
当内容为“零输出”(zeroed-out)和从头重写时,所有的图像和其他资源将被重新加载。
outerHTMLouterHTML属性包含元素的全部HTML。就像innerHTML的内容加上元素本身一样。从文字难于理解或想象的话,咱们把上面的示例修改一下,通过innerHTML和outerHTML的结果来看其获取的是什么:
let eleP = document.querySelector('p')
let eleInner = eleP.innerHTML
let eleOuter = eleP.outerHTML console.log('>>> innerHTML >>>', eleInner) console.log('>>> outerHTML >>>', eleOuter)登录后复制输出的结果:

outerHTML和innerHTML也可以写入,但不同的是:
innerHTML可以写入内容,改变元素,但outerHTML在外部环境中取代了整体!
比如下面这个示例:
let eleP = document.querySelector('p') eleP.outerHTML = '<div class="new">把整个p元素换成div元素</div>'登录后复制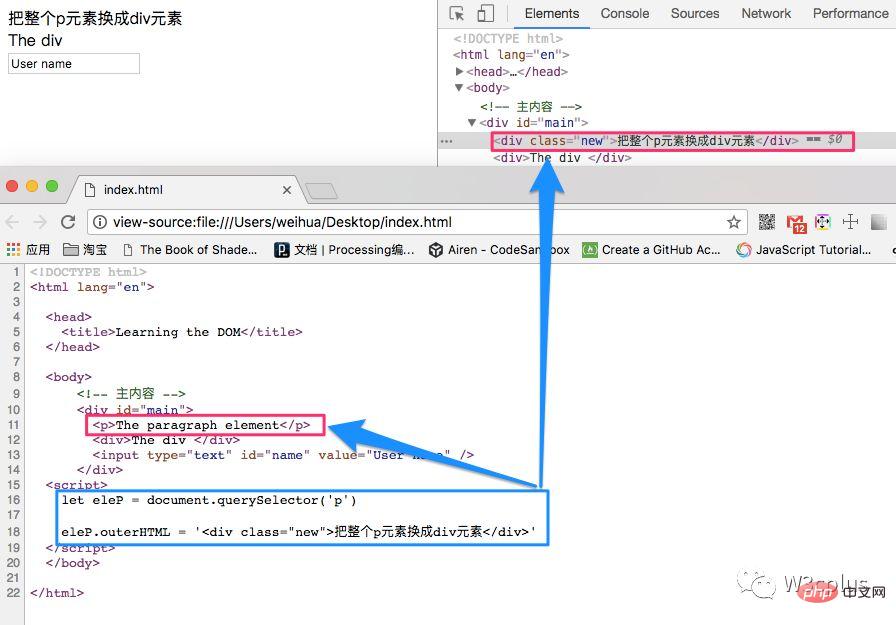
从效果和页面源码上截图可以看出来,p替换了p。
outerHTML赋值不修改DOM元素,而是从外部环境中提取它,并插入一个新的HTML片段,而不是它。新手时常在这里会犯错误:修改eleP.outerHTML,然后继续使用eleP,就好像它有新的内容一样。
let eleP = document.querySelector('p') eleP.outerHTML = '<div class="new">把整个p元素换成div元素</div>' console.log(eleP.innerHTML)登录后复制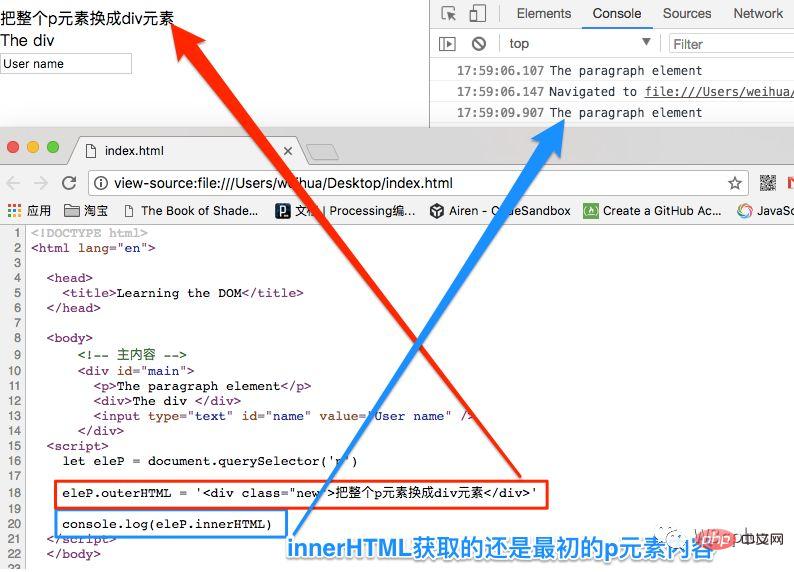
我们可以写入outerHTML,但是要记住,它不会改变我们写入的元素。相反,它会在它的位置上创建新的内容。我们可以通过查询DOM获得对新元素的引用。比如:
let eleP = document.querySelector('p') eleP.outerHTML = '<div class="new">把整个p元素换成div元素</div>' console.log('>>>> ', eleP) let newEle = document.querySelector('.new') console.log('>>>> ', newEle)登录后复制结果如下:

textContenttextContent属性和innerHTML以及outerHTML都不一样。textContent只获取元素的纯文本内容,包括其后代元素的内容。比如:
let mainEle = document.querySelector('#main') console.log('>>>> innerHTML >>>>', mainEle.innerHTML) console.log('>>>> outerHTML >>>>', mainEle.outerHTML) console.log('>>>> textContent >>>>', mainEle.textContent)登录后复制结果如下:
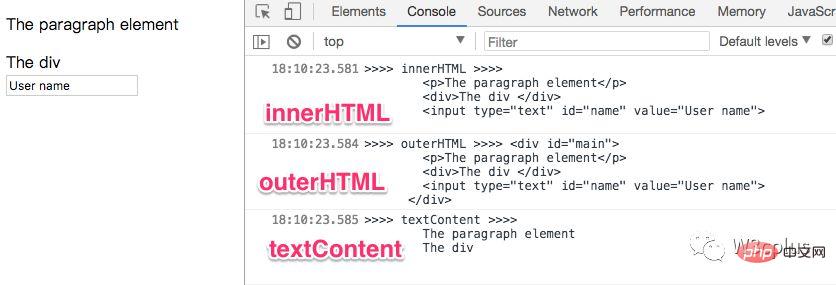
正如我们所看到的,textContent返回的只有文本内容,就像是把所有HTML元素的标签都删除了,但是它们的文本仍然保留着。正如上面示例中的,innerHTML、outerHTML和textContent输出的结果,可以一目了然知道他们之间的差异性。
textContent和其他两个属性一样,也可以写入内容。但对于textContent的写入更为有用,因为它写入的内容是纯内容,是一种安全方式。而innerHTML和outerHTML都会写入HTML,而会写入HTML标签的方式是一种不安全的形式,容易引起Web的XSS攻击。
XSS我们先忽略,来看看写入的差异性:
let mainEle = document.querySelector('#main') let content = "我要新内容,并带有一个标签:<b>Boo,Waa!!!</b>" mainEle.textContent = content mainEle.innerHTML = content mainEle.outerHTML = content登录后复制效果如下:
如果你够仔细的话,会发现,name中的<b>Boo,Waa!!!</b>的<body>标签也被当做文本内容写进去了。如下图所示:
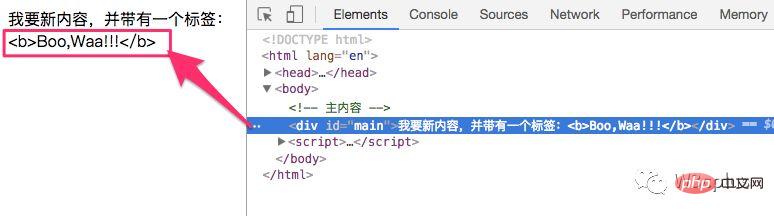
大多数情况之下,我们希望从用户那里得到文本,并希望将其视为文本。我们不希望在我们的网站上出现意想不到的HTML,那么textContent就可以得到你想要的。
innerText和outerTextinnerText和outerText是IE的私有属性,获取的也是元素的文本内容,有点类似于textContent。所以这里只简单的提一提,并不深入展开。如果这里有误,请大大们指正。
nodeValue和datainnerHTML属性仅对元素节点有效。
其他节点类型有对应的节点:nodeValue和data属性。这两种方法在实际应用中几乎是相同的,只有很小的差异。来看看示例。
<body>
Hello JavaScript!!!!
<!-- 主内容 -->
<div id="main">
<p>The paragraph element</p>
<div>The div </div>
<input type="text" id="name" value="User name" />
</div>
<script>
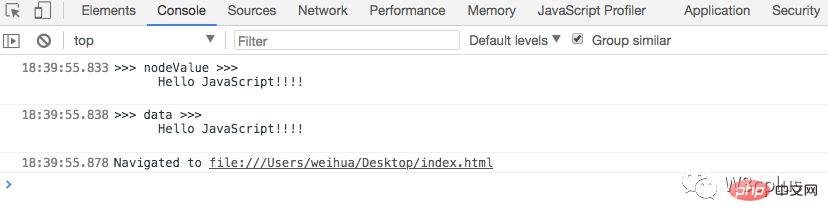
console.log('>>> nodeValue >>>', document.body.firstChild.nodeValue) console.log('>>> data >>>', document.body.firstChild.data)
</script>
</body>登录后复制他们输出的结果是相同的:
每个DOM节点属于某个类。这些类构成一个DOM树。所有的属性和方法都将被继承。主要的DOM节点属性有:
nodeType:我们可以从DOM对象类中获取nodeType。我们通常需要查看它是否是文本或元素节点,使用nodeType属性很好。它可以获取对应的常数值,其中1表示元素节点,3表示文本节点。另外,该属性是一个只读属性。
nodeName / tagName:tagName只用于元素节点,对于非元素节点使用nodeName来描述。它们也是只读属性。
innerHTML:获取HTML元素的内容(包括元素标签自身)。其可以被修改。
outerHTML:获取元素完整的HTML。outerHTML并没有触及元素自身。相反,它被外部环境中的新HTML所取代。
nodeValue / data:非元素节点的内容(文本、注释)。这两个几乎是一样的,不过我们通常使用data。
textContent:获取元素内容的文本,基本上是HTML减去所有的标签。它也具有写入特性,可以将文本放入元素中,所有特殊的字符和标记都被精确的处理为文本。
DOM节点也有其他属性,这取决于它们的类。例如,<input>元素(HTMLElement)具有value、type属性,而<a>元素(HTMLAnchorElement)具有href属性。大多数标准的HTML属性都具有相应的DOM属性。
【相关推荐:javascript视频教程、web前端】
以上就是归纳分享DOM节点属性知识点的详细内容,更多请关注zzsucai.com其它相关文章!

