所属分类:php教程

程序员必备接口测试调试工具:立即使用
Apipost = Postman + Swagger + Mock + Jmeter
Api设计、调试、文档、自动化测试工具
后端、前端、测试,同时在线协作,内容实时同步
推荐学习:python视频教程
安装:
pip install seaborn
导入:
import seaborn as sns
正式开始之前我们先用如下代码准备一组数据,方便展示使用。
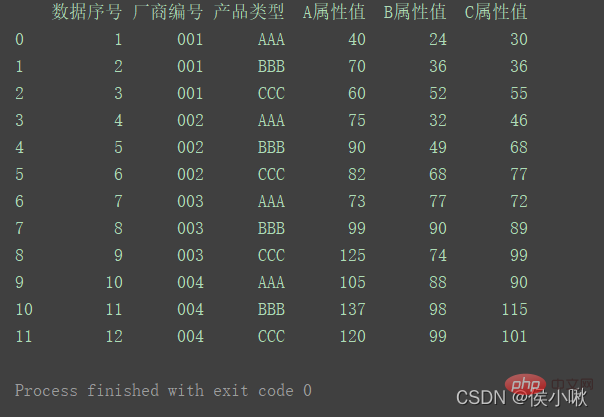
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snspd.set_option('display.unicode.east_asian_width', True)df1 = pd.DataFrame( {'数据序号': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12], '厂商编号': ['001', '001', '001', '002', '002', '002', '003', '003', '003', '004', '004', '004'], '产品类型': ['AAA', 'BBB', 'CCC', 'AAA', 'BBB', 'CCC', 'AAA', 'BBB', 'CCC', 'AAA', 'BBB', 'CCC'], 'A属性值': [40, 70, 60, 75, 90, 82, 73, 99, 125, 105, 137, 120], 'B属性值': [24, 36, 52, 32, 49, 68, 77, 90, 74, 88, 98, 99], 'C属性值': [30, 36, 55, 46, 68, 77, 72, 89, 99, 90, 115, 101] })print(df1)生成一组数据如下:
设置风格使用的是sns.set_style()方法,且这里内置的风格,是用背景色表示名字的,但是实际内容不限于背景色。
sns.set_style()
可以选择的背景风格有:
sns.set()
sns.set_style(“darkgrid”)
sns.set_style(“whitegrid”)
sns.set_style(“dark”)
sns.set_style(“white”)
sns.set_style(“ticks”)
其中sns.set()表示使用自定义样式,如果没有传入参数,则默认表示灰色网格背景风格。如果没有set()也没有set_style(),则为白色背景。
一个可能的bug:使用relplot()方法绘制出的图像,"ticks"样式无效。
seaborn库是基于matplotlib库而封装的,其封装好的风格可以更加方便我们的绘图工作。而matplotlib库常用的语句,在使用seaborn库时也依然有效。
关于设置其他风格相关的属性,如字体,这里有一个细节需要注意的是,这些代码必须写在sns.set_style()的后方才有效。如将字体设置为黑体(避免中文乱码)的代码:
plt.rcParams[‘font.sans-serif’] = [‘SimHei’]
如果在其后方设置风格,则设置好的字体会设置的风格覆盖,从而产生警告。其他属性也同理。
sns.despine()方法
# 移除顶部和右部边框,只保留左边框和下边框sns.despine()# 使两个坐标轴相隔一段距离(以10长度为例)sns.despine(offet=10,trim=True)# 移除左边框sns.despine(left=True)# 移除指定边框 (以只保留底部边框为例)sns.despine(fig=None, ax=None, top=True, right=True, left=True, bottom=False, offset=None, trim=False)
使用seaborn库 绘制散点图,可以使用replot()方法,也可以使用scatter()方法。
replot方法的参数kind默认是’scatter’,表示绘制散点图。
hue参数表示 在该一维度上,用颜色区分
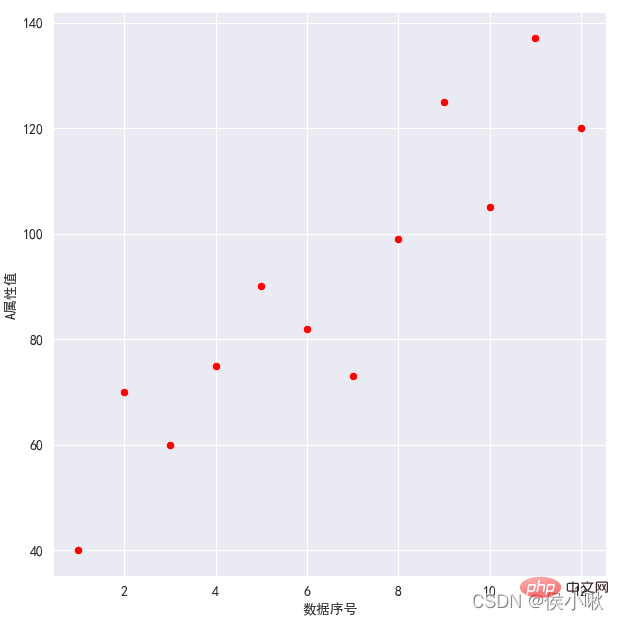
①对A属性值和数据序号绘制散点图,红色散点,灰色网格,保留左、下边框
sns.set_style(‘darkgrid’)
plt.rcParams[‘font.sans-serif’] = [‘SimHei’]
sns.relplot(x=‘数据序号’, y=‘A属性值’, data=df1, color=‘red’)
plt.show()
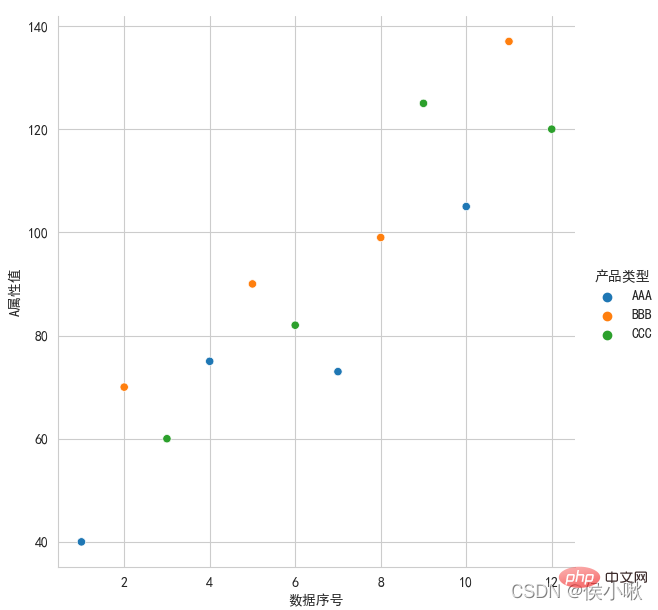
②对A属性值和数据序号绘制散点图,散点根据产品类型的不同显示不同的颜色,
白色网格,左、下边框:
sns.set_style(‘whitegrid’)
plt.rcParams[‘font.sans-serif’] = [‘SimHei’]
sns.relplot(x=‘数据序号’, y=‘A属性值’, hue=‘产品类型’, data=df1)
plt.show()
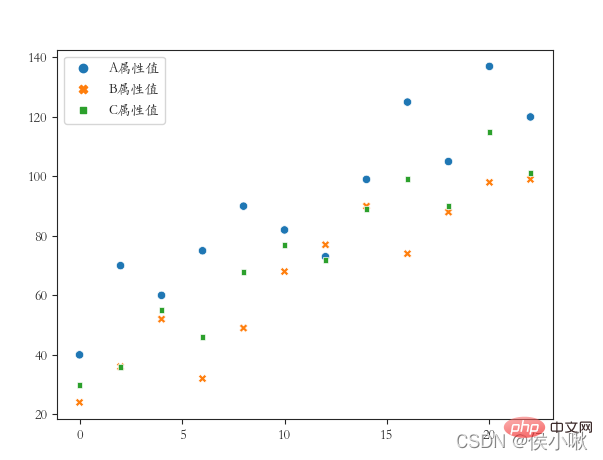
③将A属性、B属性、C属性三个字段的值用不同的样式绘制在同一张图上(绘制散点图),x轴数据是[0,2,4,6,8…]
ticks风格(四个方向的框线都要),字体使用楷体
sns.set_style(‘ticks’)
plt.rcParams[‘font.sans-serif’] = [‘STKAITI’]
df2 = df1.copy()
df2.index = list(range(0, len(df2)*2, 2))
dfs = [df2[‘A属性值’], df2[‘B属性值’], df2[‘C属性值’]]
sns.scatterplot(data=dfs)
plt.show()
使用seaborn库绘制折线图, 可以使用replot()方法,也可以使用lineplot()方法。
sns.replot()默认绘制的是散点图,绘制折线图只需吧参数kind改为"line"。
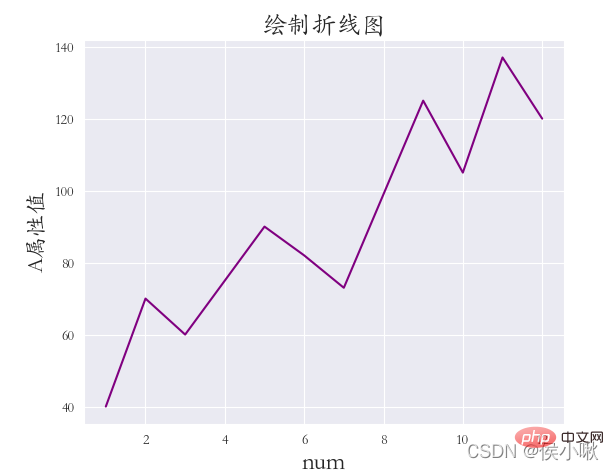
①
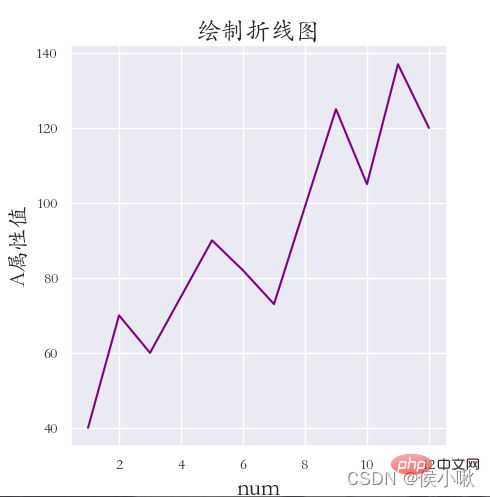
需求:绘制A属性值与数据序号的折线图,
灰色网格,全局字体为楷体;并调整标题、两轴标签 的字体大小,
以及坐标系与画布边缘的距离(设置该距离是因为字体没有显示完全):
sns.set(rc={‘font.sans-serif’: “STKAITI”})
sns.relplot(x=‘数据序号’, y=‘A属性值’, data=df1, color=‘purple’, kind=‘line’)
plt.title(“绘制折线图”, fontsize=18)
plt.xlabel(‘num’, fontsize=18)
plt.ylabel(‘A属性值’, fontsize=16)
plt.subplots_adjust(left=0.15, right=0.9, bottom=0.1, top=0.9)
plt.show()
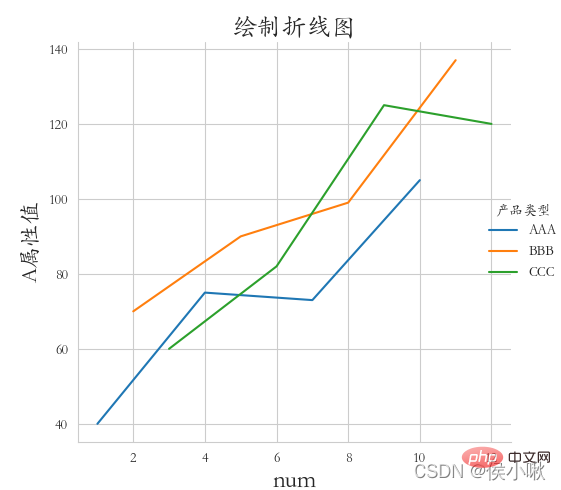
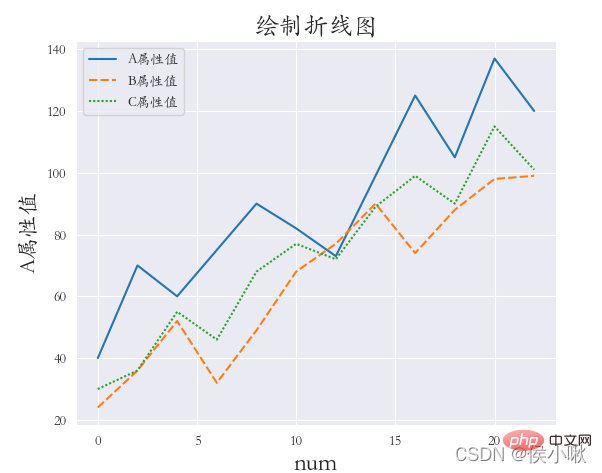
②
需求:绘制不同产品类型的A属性折线(三条线一张图),whitegrid风格,字体楷体。
sns.set_style(“whitegrid”)
plt.rcParams[‘font.sans-serif’] = [‘STKAITI’]
sns.relplot(x=‘数据序号’, y=‘A属性值’, hue=‘产品类型’, data=df1, kind=‘line’)
plt.title(“绘制折线图”, fontsize=18)
plt.xlabel(‘num’, fontsize=18)
plt.ylabel(‘A属性值’, fontsize=16)
plt.subplots_adjust(left=0.15, right=0.9, bottom=0.1, top=0.9)
plt.show()
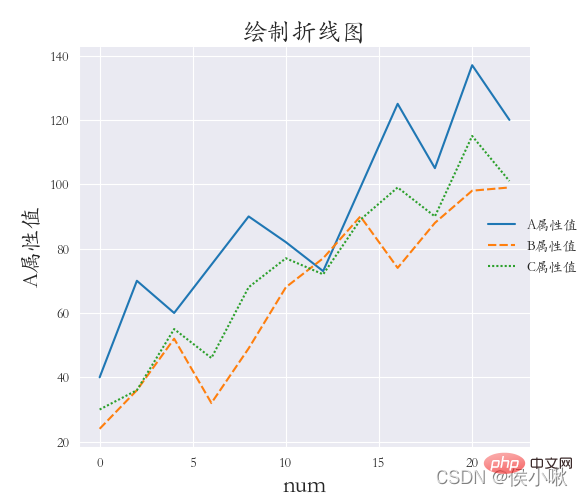
③
需求:将A属性、B属性、C属性三个字段的值用不同的样式绘制在同一张图上(绘制折线图),x轴数据是[0,2,4,6,8…]
darkgrid风格(四个方向的框线都要),字体使用楷体,并加入x轴标签,y轴标签和标题。边缘距离合适。
sns.set_style(‘darkgrid’)
plt.rcParams[‘font.sans-serif’] = [‘STKAITI’]
df2 = df1.copy()
df2.index = list(range(0, len(df2)*2, 2))
dfs = [df2[‘A属性值’], df2[‘B属性值’], df2[‘C属性值’]]
sns.relplot(data=dfs, kind=“line”)
plt.title(“绘制折线图”, fontsize=18)
plt.xlabel(‘num’, fontsize=18)
plt.ylabel(‘A属性值’, fontsize=16)
plt.subplots_adjust(left=0.15, right=0.9, bottom=0.1, top=0.9)
plt.show()
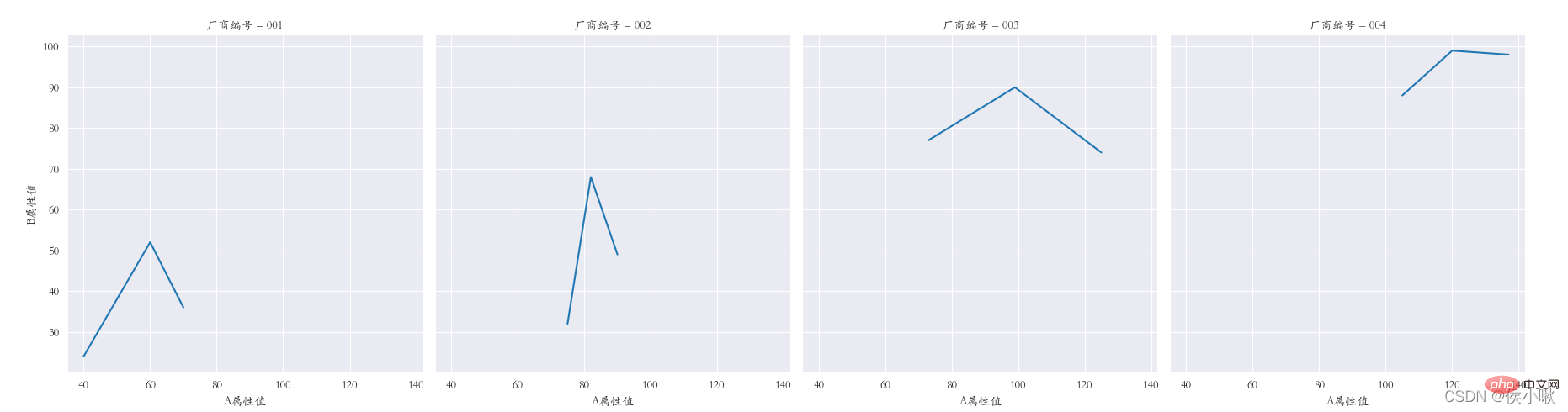
③
多重子图
横向多重子图 col
sns.set_style(‘darkgrid’)
plt.rcParams[‘font.sans-serif’] = [‘STKAITI’]
sns.relplot(data=df1, x=“A属性值”, y=“B属性值”, kind=“line”, col=“厂商编号”)
plt.subplots_adjust(left=0.05, right=0.95, bottom=0.1, top=0.9)
plt.show()
纵向多重子图 row
sns.set_style(‘darkgrid’)
plt.rcParams[‘font.sans-serif’] = [‘STKAITI’]
sns.relplot(data=df1, x=“A属性值”, y=“B属性值”, kind=“line”, row=“厂商编号”)
plt.subplots_adjust(left=0.15, right=0.9, bottom=0.1, top=0.95)
plt.show()
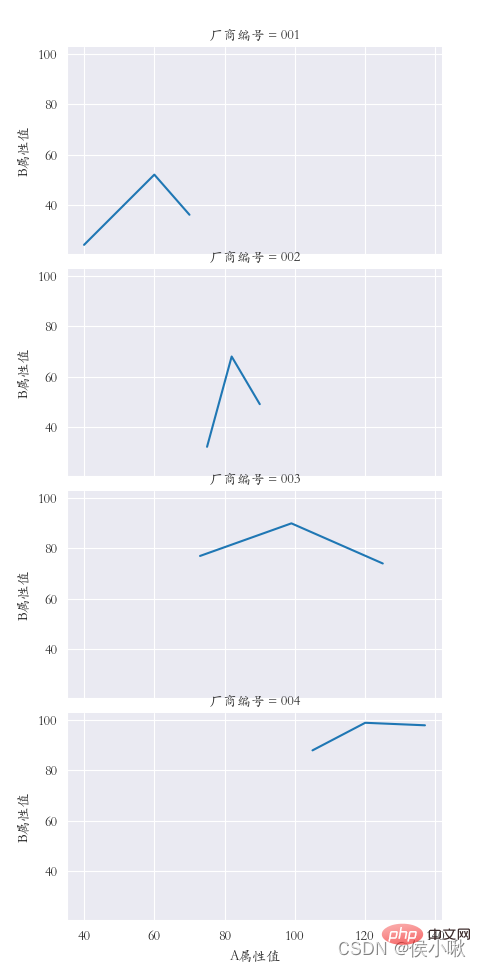
使用lineplot()方法绘制折线图,其他细节基本同上,示例代码如下:
sns.set_style(‘darkgrid’)
plt.rcParams[‘font.sans-serif’] = [‘STKAITI’]
sns.lineplot(x=‘数据序号’, y=‘A属性值’, data=df1, color=‘purple’)
plt.title(“绘制折线图”, fontsize=18)
plt.xlabel(‘num’, fontsize=18)
plt.ylabel(‘A属性值’, fontsize=16)
plt.subplots_adjust(left=0.15, right=0.9, bottom=0.1, top=0.9)
plt.show()
sns.set_style(‘darkgrid’)
plt.rcParams[‘font.sans-serif’] = [‘STKAITI’]
df2 = df1.copy()
df2.index = list(range(0, len(df2)*2, 2))
dfs = [df2[‘A属性值’], df2[‘B属性值’], df2[‘C属性值’]]
sns.lineplot(data=dfs)
plt.title(“绘制折线图”, fontsize=18)
plt.xlabel(‘num’, fontsize=18)
plt.ylabel(‘A属性值’, fontsize=16)
plt.subplots_adjust(left=0.15, right=0.9, bottom=0.1, top=0.9)
plt.show()
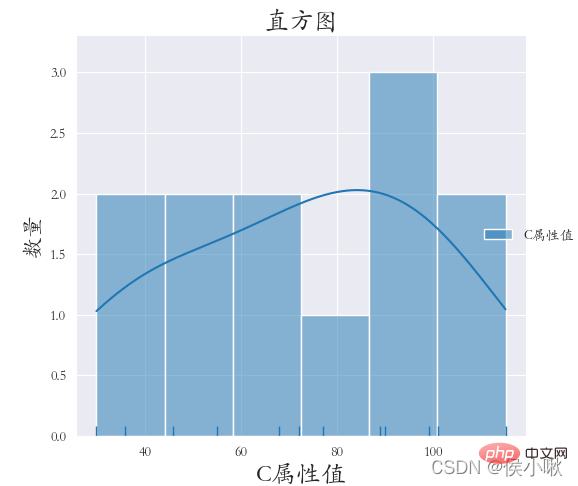
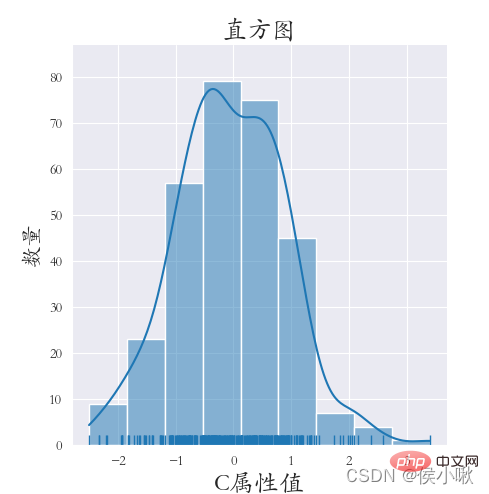
绘制直方图使用的是sns.displot()方法
bins=6 表示 分成六个区间绘图
rug=True 表示在x轴上显示观测的小细条
kde=True表示显示核密度曲线
sns.set_style(‘darkgrid’)
plt.rcParams[‘font.sans-serif’] = [‘STKAITI’]
sns.displot(data=df1[[‘C属性值’]], bins=6, rug=True, kde=True)
plt.title(“直方图”, fontsize=18)
plt.xlabel(‘C属性值’, fontsize=18)
plt.ylabel(‘数量’, fontsize=16)
plt.subplots_adjust(left=0.15, right=0.9, bottom=0.1, top=0.9)
plt.show()
随机生成300个正态分布数据,并绘制直方图,显示核密度曲线
sns.set_style(‘darkgrid’)
plt.rcParams[‘font.sans-serif’] = [‘STKAITI’]
np.random.seed(13)
Y = np.random.randn(300)
sns.displot(Y, bins=9, rug=True, kde=True)
plt.title(“直方图”, fontsize=18)
plt.xlabel(‘C属性值’, fontsize=18)
plt.ylabel(‘数量’, fontsize=16)
plt.subplots_adjust(left=0.15, right=0.9, bottom=0.1, top=0.9)
plt.show()
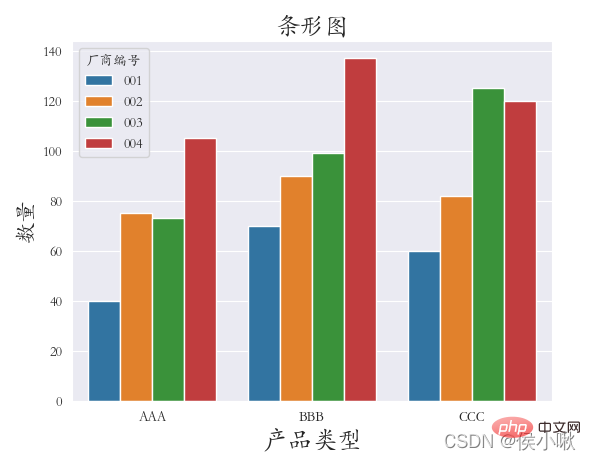
绘制条形图使用的是barplot()方法
以产品类型 字段数据作为x轴数据,A属性值数据作为y轴数据。按照厂商编号字段的不同进行分类。
具体如下:
sns.set_style(‘darkgrid’)
plt.rcParams[‘font.sans-serif’] = [‘STKAITI’]
sns.barplot(x=“产品类型”, y=‘A属性值’, hue=“厂商编号”, data=df1)
plt.title(“条形图”, fontsize=18)
plt.xlabel(‘产品类型’, fontsize=18)
plt.ylabel(‘数量’, fontsize=16)
plt.subplots_adjust(left=0.15, right=0.9, bottom=0.15, top=0.9)
plt.show()
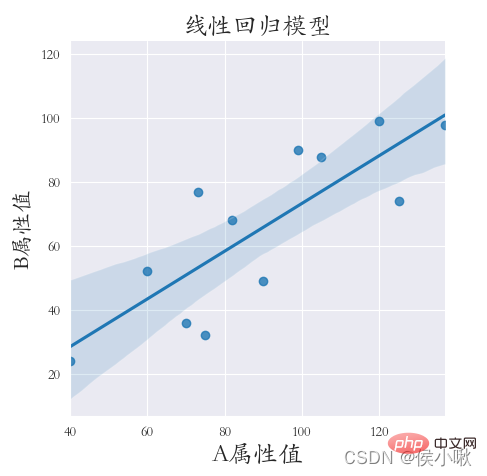
绘制线性回归模型使用的是lmplot()方法。
主要的参数为x, y, data。分别表示x轴数据、y轴数据和数据集数据。
除此之外,同上述所讲,还可以通过hue指定分类的变量;
通过col指定列分类变量,以绘制 横向多重子图;
通过row指定行分类变量,以绘制 纵向多重子图;
通过col_wrap控制每行子图的数量;
通过size可以控制子图的高度;
通过markers可以控制点的形状。
下边对 X属性值 和 Y属性值 做线性回归,代码如下:
sns.set_style(‘darkgrid’)
plt.rcParams[‘font.sans-serif’] = [‘STKAITI’]
sns.lmplot(x=“A属性值”, y=‘B属性值’, data=df1)
plt.title(“线性回归模型”, fontsize=18)
plt.xlabel(‘A属性值’, fontsize=18)
plt.ylabel(‘B属性值’, fontsize=16)
plt.subplots_adjust(left=0.15, right=0.9, bottom=0.15, top=0.9)
plt.show()
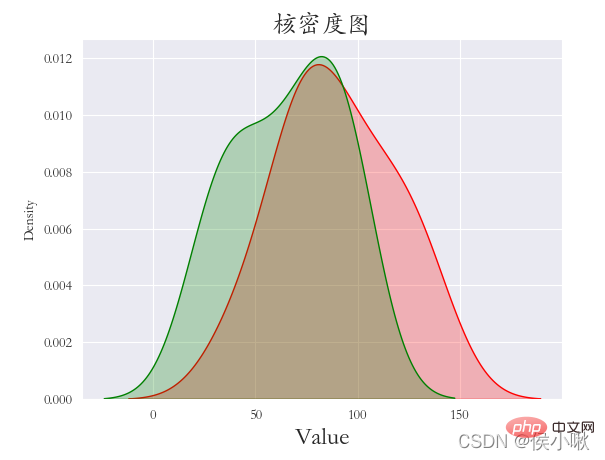
绘制和密度图,可以让我们更直观地看出样本数据的分布特征。绘制核密度图使用的方法是kdeplot()方法。
对A属性值和B属性值绘制核密度图,
将shade设置为True可以显示包围的阴影,否则只有线条。
sns.set_style(‘darkgrid’)
plt.rcParams[‘font.sans-serif’] = [‘STKAITI’]
sns.kdeplot(df1[“A属性值”], shade=True, data=df1, color=‘r’)
sns.kdeplot(df1[“B属性值”], shade=True, data=df1, color=‘g’)
plt.title(“核密度图”, fontsize=18)
plt.xlabel(‘Value’, fontsize=18)
plt.subplots_adjust(left=0.15, right=0.9, bottom=0.15, top=0.9)
plt.show()
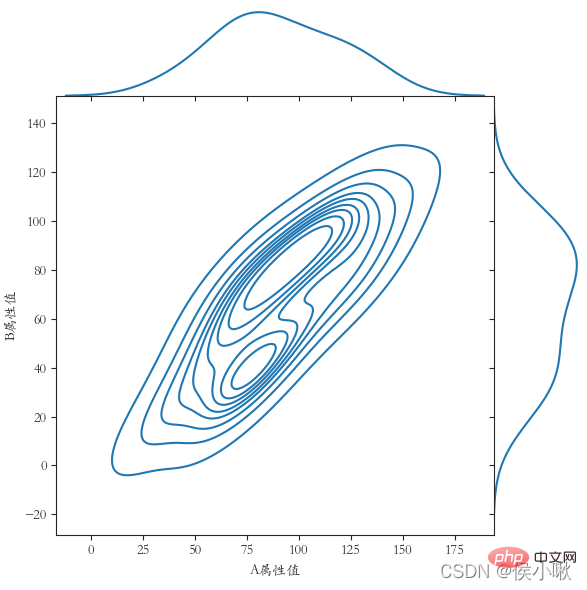
绘制边际核密度图时使用的是sns.jointplot()方法。参数kind应为"kde"。使用该方法时,默认使用的是dark样式。且不建议手动添加其他样式,否则可能使图像无法正常显示。
plt.rcParams[‘font.sans-serif’] = [‘STKAITI’]
sns.jointplot(x=df1[“A属性值”], y=df1[“B属性值”], kind=“kde”, space=0)
plt.show()
绘制箱线图使用到的是boxplot()方法。
基本的参数有x, y, data。
除此之外 还可以有
hue 表示分类字段
width 可以调节箱体的宽度
notch 表示中间箱体是否显示缺口,默认False不显示。
鉴于前边的数据数据量不太够不便展示,这里再生成一组数据:
np.random.seed(13)
Y = np.random.randint(20, 150, 360)
df2 = pd.DataFrame(
{‘厂商编号’: [‘001’, ‘001’, ‘001’, ‘002’, ‘002’, ‘002’, ‘003’, ‘003’, ‘003’, ‘004’, ‘004’, ‘004’] * 30,
‘产品类型’: [‘AAA’, ‘BBB’, ‘CCC’, ‘AAA’, ‘BBB’, ‘CCC’, ‘AAA’, ‘BBB’, ‘CCC’, ‘AAA’, ‘BBB’, ‘CCC’] * 30,
‘XXX属性值’: Y
}
)
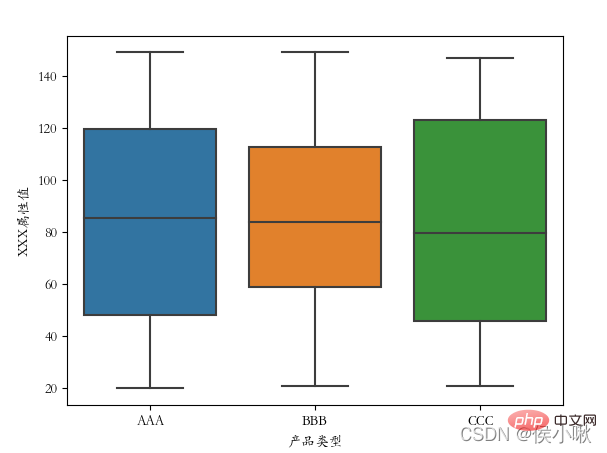
生成好后,开始绘制箱线图:
plt.rcParams[‘font.sans-serif’] = [‘STKAITI’]
sns.boxplot(x=‘产品类型’, y=‘XXX属性值’, data=df2)
plt.show()
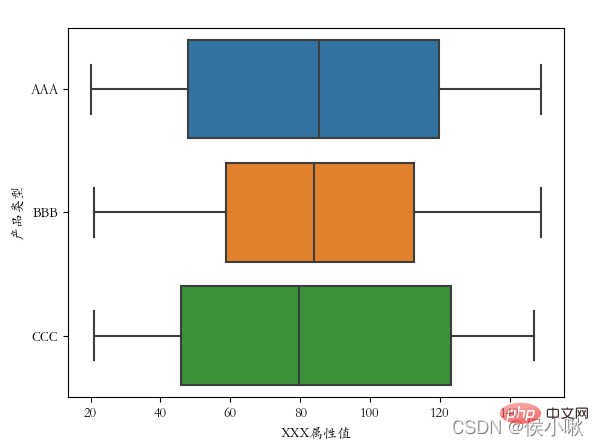
交换x、y轴数据后:
plt.rcParams[‘font.sans-serif’] = [‘STKAITI’]
sns.boxplot(y=‘产品类型’, x=‘XXX属性值’, data=df2)
plt.show()
可以看到箱线图的方向也随之改变
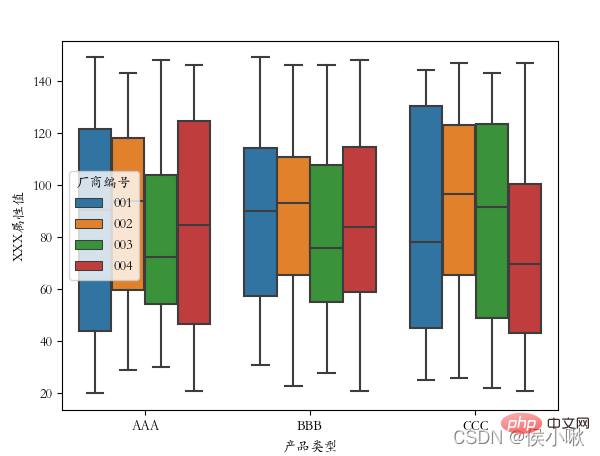
将厂商编号作为分类字段:
plt.rcParams[‘font.sans-serif’] = [‘STKAITI’]
sns.boxplot(x=‘产品类型’, y=‘XXX属性值’, data=df2, hue=“厂商编号”)
plt.show()
提琴图结合了箱线图和核密度图的特征,用于展示数据的分布形状。
使用violinplot()方法绘制提琴图。
plt.rcParams[‘font.sans-serif’] = [‘STKAITI’]
sns.violinplot(x=‘产品类型’, y=‘XXX属性值’, data=df2)
plt.show()
plt.rcParams[‘font.sans-serif’] = [‘STKAITI’]
sns.violinplot(x=‘XXX属性值’, y=‘产品类型’, data=df2)
plt.show()
plt.rcParams[‘font.sans-serif’] = [‘STKAITI’]
sns.violinplot(x=‘产品类型’, y=‘XXX属性值’, data=df2, hue=“厂商编号”)
plt.show()
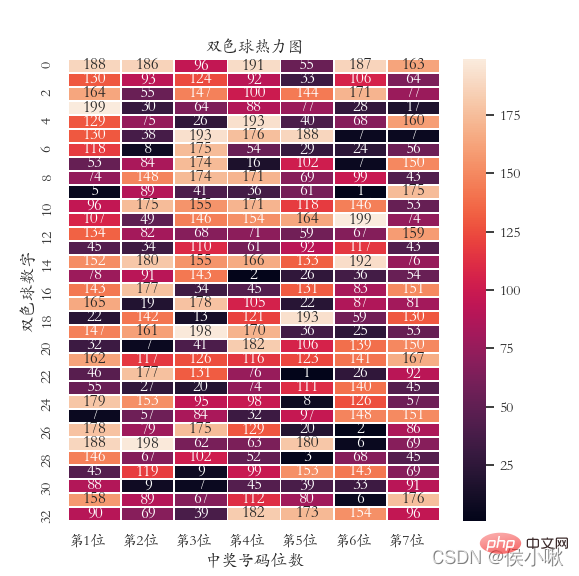
以双色球中奖号码数据为例绘制热力图,这里数据采用随机数生成。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
plt.figure(figsize=(6,6))
plt.rcParams[‘font.sans-serif’] = [‘STKAITI’]
s1 = np.random.randint(0, 200, 33)
s2 = np.random.randint(0, 200, 33)
s3 = np.random.randint(0, 200, 33)
s4 = np.random.randint(0, 200, 33)
s5 = np.random.randint(0, 200, 33)
s6 = np.random.randint(0, 200, 33)
s7 = np.random.randint(0, 200, 33)
data = pd.DataFrame(
{‘一’: s1,
‘二’: s2,
‘三’: s3,
‘四’:s4,
‘五’:s5,
‘六’:s6,
‘七’:s7
}
)
plt.title(‘双色球热力图’)
sns.heatmap(data, annot=True, fmt=‘d’, lw=0.5)
plt.xlabel(‘中奖号码位数’)
plt.ylabel(‘双色球数字’)
x = [‘第1位’, ‘第2位’, ‘第3位’, ‘第4位’, ‘第5位’, ‘第6位’, ‘第7位’]
plt.xticks(range(0, 7, 1), x, ha=‘left’)
plt.show()
推荐学习:python视频教程
以上就是详细讲解Python之Seaborn(数据可视化)的详细内容,更多请关注zzsucai.com其它相关文章!