

所属分类:php教程

程序员必备接口测试调试工具:立即使用
Apipost = Postman + Swagger + Mock + Jmeter
Api设计、调试、文档、自动化测试工具
后端、前端、测试,同时在线协作,内容实时同步
推荐学习:python视频教程
什么是列表呢?
变量可以存储一个元素,而列表可以存储N个元素。
列表相当于其他语言中的数组。
不同的是python中的列表可存储多个不同类型的元素。
a=10 #变量存储的是一个对象的id(即地址)lst=['hello','world',98]print(id(lst))print(type(lst))print(lst)
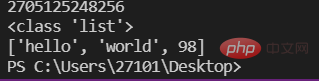
注意:变量存储的是一个元素的id,而列表存放的是多个元素的id,如图: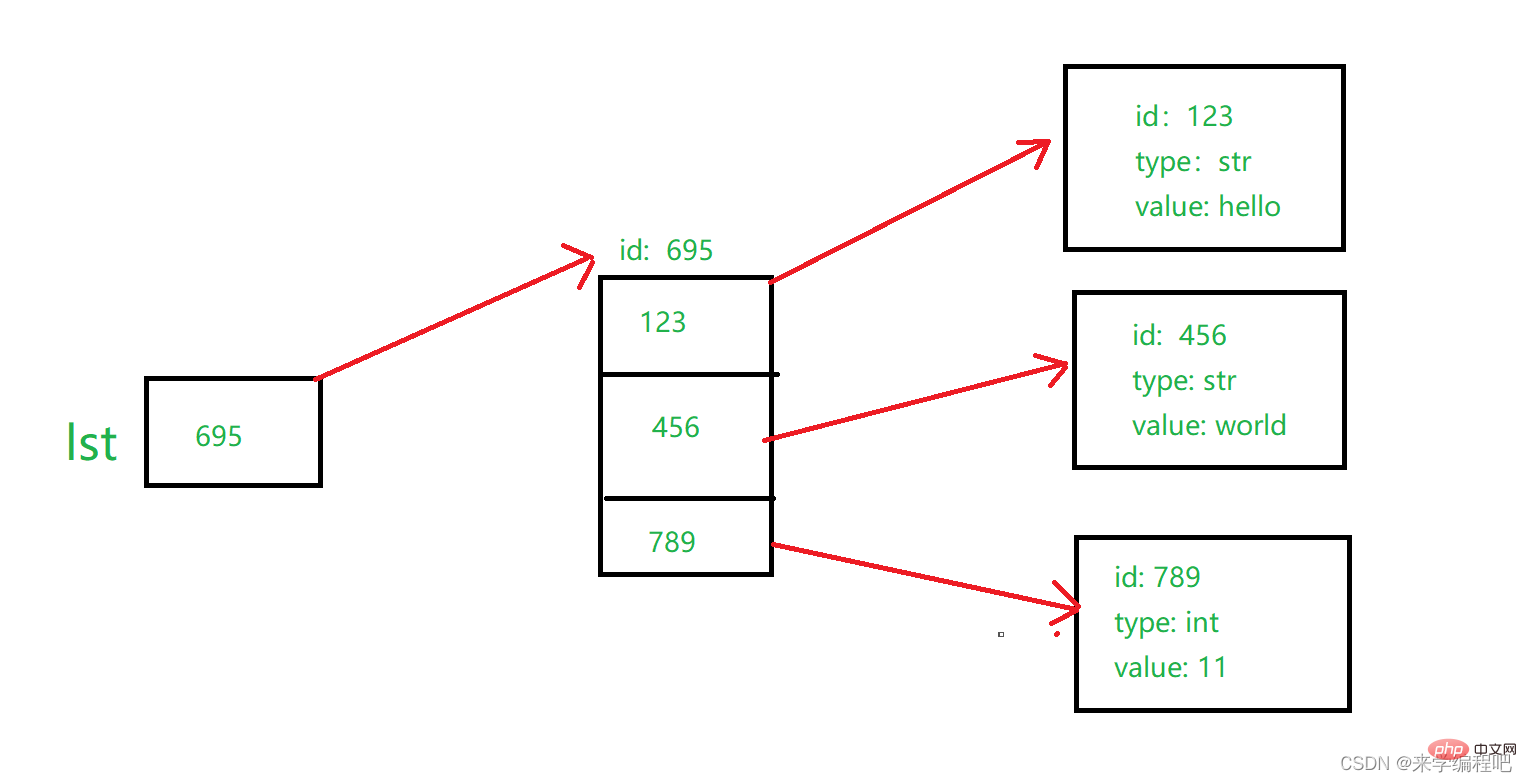
lst保存了列表的id,而列表的每一个位置保存了每一个元素的id,这样我们就可以用列表来存储多个不同种类的元素。
创建:
① [ , ] 使用中括号,元素与元素间用‘,’ 如 lst1=[‘hello’,‘world’,11]
② 调用内置函数list() 如lst2=list([‘hello’,‘world’,11])
创建空列表
list3=[]或list3=list()
列表的特点:
列表元素按顺序有序排列;
索引映射唯一元素;
索引正序为正,从0开始,逆序为负,从-1开始;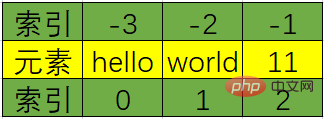
可存储重复数据;
任意数据类型混存;
根据需要动态分配和回收内存。
index(元素)
如列表中性存在多个相同元素,只返回相同元素中第一个元素的索引;
如果查询的元素不在列表中,则会出现错误ValueError;
可以在指定start和end之间查找。
value=0lst=['hello','world',11,'hello']print(lst.index('hello'))
#0#print(lst.index(value))
报错:找不到#print(lst.index('hello',1.3))
报错:找不到print(lst.index('hello',1,4))
#3正向索引从0到N-1,如 lst[0]
逆向索引从-N到-1,如 lst[-N]
指定索引不存在,出现IndexError
语法:
列表名[start: end :step ]
切片的结果:原列表片段的拷贝;
切片的范围:[start,end);
step默认为1:简写为[start: end]
lst=[10,20,30,40,50,60,70,80,90]lst1=lst[2:6:2]print(lst)print(lst1)print('原列表',id(lst))print('切片',id(lst1))
#切片是一个新的列表对象step为正数时,从start开始往后切片;
切片的第一个元素默认为列表的最后一个元素;
切片的最后一个元素默认为列表的第一个元素。
lst=[10,20,30,40,50,60,70,80,90]print(lst[1:6:2]) #[20, 40, 60]print(lst[:6:2]) #[10, 30, 50]print(lst[1::2]) #[20, 40, 60, 80]
step是负数时,从start开始往前切片
lst=[10,20,30,40,50,60,70,80,90]print(lst[::-1]) #[90, 80, 70, 60, 50, 40, 30, 20, 10]print(lst[6::-2]) #[70, 50, 30, 10]print(lst[6:0:-2]) #[70, 50, 30]print(lst[:2:-2]) #[90, 70, 50]
语法:
元素 in 列表名
元素 not in 列表名
语法:
for 迭代变量 in 列表名:
操作
print(10 in lst)print(100 not in lst)for item in lst:
print(item)lst=[10,20,30,40,50,60,70,80,90] lst1=['hello','world'] lst2=['python',66,88] #四种方法 #第一种 append() 在列表的末尾添加一个元素 lst.append(100) print(lst[9]) lst.append(lst1) #将lst1作为一个元素添加在lst末尾 print(lst) #第二种 extend() 在列表的末尾添加至少一个元素 lst.extend(lst1) #将lst1作为两个元素添加在lst末尾 print(lst) #第三种 insert() 在列表的任意位置添加一个元素 lst.insert(1,11) #在1处插入11 print(lst) #第四种 切片 在列表的任意位置添加至少一个元素 lst[1:]=lst2 #实质为在切掉的部分添加一个列表 print(lst)

lst=[10,20,30,40,50,60,70,80,40] print(lst) #五种方法 #第一种 remove() 一次删除一个元素;重复元素只删除第一个;元素不存在出错ValueError. lst.remove(40) print(lst) #第二种 pop() 删除一个指定索引位置上的元素;不指定索引删除最后一个元素;指定索引不存在出错IndexError lst.pop(3) print(lst) #第三种 切片 一次至少删除一个元素,但切片会产生新的列表对象 new_list=lst[1:3] #使用以下方式则不会: lst[1:3]=[] print(lst) #第四种 clear() 清空列表 lst.clear() print(lst) #第五种 del 删除列表 del lst print(lst) #报错
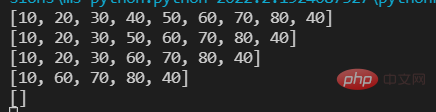
lst=[10,20,30,40,50] print(lst) #第一种 为指定索引的元素赋予一个新值 lst[1]=11 print(lst) #第二种 为指定的切片赋予一个新值 lst[1:3:]=[666,777,888,999,] print(lst)
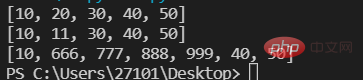
#两种排序方式
print('第一种方法:')
lst=[11,7,99,86,59,108]
print(lst,id(lst))
#第一种 调用sort()方法,列表中的所有元素默认从小到大排序,
#可以指定reverse=True进行降序排序
lst.sort() #相当于lst.sort(reverse=False)
print(lst,id(lst)) #升序排序
lst.sort(reverse=True)
print(lst) #降序排序
print('第二种方法:')
lst=[11,7,99,86,59,108]
print(lst,id(lst))
#第二种 调用内置函数sorted(),可以指定降序排序,原列表不发生改变,将产生一个新的列表对象
new_list=sorted(lst)
print(lst,id(lst))
print(new_list,id(new_list)) #升序排序
desc_list=sorted(lst,reverse=True)
print(desc_list,id(desc_list)) #降序排序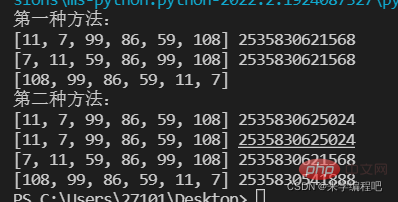
即生成列表的公式。
语法:
列表名=[ 列表元素表达式 for i in range( , ) ]
注意:表达式中一般包含自定义变量 i
lst=[i*i for i in range(1,10)] print(lst)#输出为 [1, 4, 9, 16, 25, 36, 49, 64, 81]
可变序列:进行增删改操作的序列,如列表
不可变序列:不能在原来的基础上增删改,如字符串、整数
字典是python内置的数据结构之一,与列表一样是一个可变序列;
以键值对的方式存储数据,字典是一个无序的序列;(列表单身狗,字典成一对)
语法:例如
scores={ '张三’:99,‘李四’: 66, ‘王五’: 11}
(:之前的称作键,、:之后的叫值)
字典示意图:(1,2,3代表元素顺序)
与列表第一个元素存在第一个位置,第二个元素存在第二个位置不同,字典中元素的存放位置与进入顺序无关,而是哈希函数计算得出的位置。
字典的实现原理与我们在现实中查字典类似,现实中我们是先根据偏旁部首或拼音查找对应页码,Python中与此类似,是先通过hash函数计算元素key值,然后根据key值找到value。
#字典的创建 两种方式
#第一种 { }
score={'张三':11,'李四':99,'王五':7}
print(score,type(score))
#第二种 使用内置函数dict()
people=dict(name='苏沐',age=20)
print(people,type(people))
#空字典
a={} #或a=dict()
print(a,type(a))
score={'张三':11,'李四':99,'王五':7,'age':20}
print(score)
#两种方法获取字典中的元素 根据键获取值
#第一种 ['键']
print(score['张三'])
print(score['age'])
#第二种 .get()方法
print(score.get('张三'))
#两种方法的区别:
#print(score['苏沐']) 报错:发生异常: KeyError
print(score.get('苏沐')) #正常运行,结果为None
print(score.get('楚风',66)) #字典中不存在元素时输出设置的默认值两种方法的区别:
[]如果字典中不存在指定的key,则会出现异常
get()如果字典中不存在指定的key,会返回None,并可以通过参数设置默认的value,使指定的key不存在时返回
score={'张三':11,'李四':99,'王五':7,'age':20}
# in 指定的key在字典中返回True
print('张三' in score)
# not in 指定的key在字典中不存在返回True
print('张三' not in score)score={'张三':11,'李四':99,'王五':7,'age':20}
print(score)
# del 删除某一个键值对
del score['张三']
print(score)
# clear() 清空字典的元素
score.clear()
print(score)
score={'张三':11,'李四':99,'王五':7,'age':20}
print(score)
score['苏沐']=66 #添加
print(score)
score['苏沐']=88 #修改
print(score)
三种方法:
keys() 获取字典中所有key
values() 获取字典中所有value
items() 获取字典中所有key.value键值对
score={'张三':11,'李四':99,'王五':7,'age':20}
print(score)
# keys() 获取字典中所有key
a=score.keys()
print(a,type(a))
print(list(a)) #可用list将所有key组成的视图转成列表
# values() 获取字典中所有value
b=score.values()
print(b,type(b))
print(list(b))
# items() 获取字典中所有key.value键值对
c=score.items()
print(c,type(c))
print(list(c)) #转换后的list元素为元组。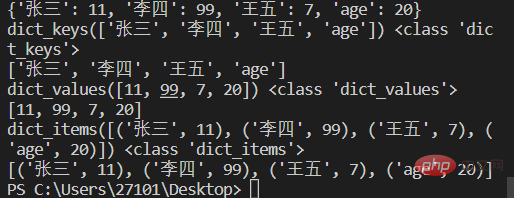
score={'张三':11,'李四':99,'王五':7,'age':20}for i in score:
print(i,score[i],score.get(i))i输出的是键,后面两个输出的是值
即生成字典的公式
内置函数zip() 将可迭代的对象作为参数,将对象中对应的元素打包成一个元组,然后返回由这些元组组成的列表。
语法:
{ 表示字典key的表达式:表示字典value的表达式 for 自定义表示key的变量,自定义表示value的变量 in zip(可迭代对象1,可迭代对象2)}
lst1=['Hello','World','Python']
lst2=[10,20,30,40]
a={key:value for key,value in zip(lst1,lst2)}
print(a)
b={key.upper():value for key,value in zip(lst1,lst2)}
print(b)
若两个可迭代对象中元素个数不一致,以元素少的那个为准。
字典中的所有元素都是一个key-value键值对,key不能重复,重复会覆盖,value可以重复;
字典中的元素是无序的;
字典中的key必须是不可变对象;(可变序列无法计算哈希值)
字典也可根据需要自动动态伸缩;
字典会浪费较大的内存,是一种使用空间换时间的数据结构。
在字典中我们已经知道可变序列与不可变序列下面重申一遍:
可变序列:可以对序列进行增、删、改操作,对象地址不发生改变。如列表、字典
不可变序列:无增删改操作,如字符串、元组。
所以元组也是Python内置的数据结构之一,是不可变序列
注意:小沐认为可变不可变关键看元素的内存地址有没有发生变化。
三种方式创建
#三种方式创建元组
# 第一种 直接用小括号()小括号可省
a=('Python','Hello',11) #或 a='Python','Hello',11
print(a,type(a))
#第二种 使用内置函数tuple()
b=tuple(('Python','yyds',666))
print(b,type(b))
#第三种 只包含一个元组的元素需要使用逗号和小括号,不加逗号系统认为是基本数据类型int等
c=(888,) #括号可省,逗号不能省
print(c,type(c))
#空元组的创建
t1=()
t2=tuple()
可以通过索引的方式输出元组元素,但要是不知道元素数目,可以用for in
t=(10,[20,30],40,50)
# 第一种 索引
print(t[0])
# 第二种 for in
for item in t:
print(item)首先,我们为什么要将元组设计成不可变序列呢?
因为这样设计,在多任务环境下比如多人协作时,不会存在在一个人操作对象时对象需要加锁的问题,因为元组本身就是不可变序列,只能读取。我们在程序中也应该尽量使用不可变序列。
注意事项:
元组中存储的是对象的引用(地址)
如果元组中对象本身是不可变对象,则不能再引用其他对象
如果元组中的数据是可变对象,则可变对象的引用不允许改变,但数据可以改变
t=(10,[20,30],40,50) # t[1]=100 报错 t[1].append(10) print(t) #列表是可变序列,可以向列表中添加元素,但列表的内存地址不变
集合是Python提供的内置数据结构之一;
与列表、字典一样都属于可变类型的序列;
集合是没有值value的字典。
所在存储位置同样是由哈希函数计算得出的。
两种方式:
注意:同字典中键不能重复一样,集合中的元素也不能重复。
#两种方式
#第一种 {}
s1={'hello','world','python',11}
print(s1,type(s1))
#第二种 使用内置函数set()
s2=set(range(6))
print(s2,type(s2))
s3=set([1,2,5,5,5,9,7,6]) #将列表内元素转为集合,同时去掉重复元素
print(s3,type(s3))
s4=set((2,11,77,88,66,66)) #将元组转成集合
print(s4,type(s4))
s5=set('python') #字符串转成集合
print(s5,type(s5))
#定义空集合 不能直接用{}否则是空字典
s6=set()
print(s6,type(s6))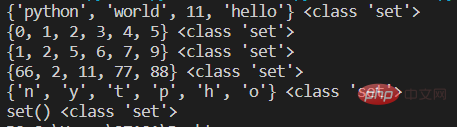
#判断元素是否存在——in not in
s={10,20,30,40,50,99}
print(s)
print(10 in s)
print(100 not in s)#两种方法 add() update()
s={10,20,30,40,50,99}
print(s)
#第一种 调用add()方法,一次添加一个元素
s.add(100)
print(s)
#第二种 调用update()方法,至少添加一个元素
s.update({666,888,999}) #给集合添加集合中的所有元素
print(s)
s.update([6666,8888,9999]) #给集合添加列表中的所有元素
print(s)
s.update((66666,88888,99999)) #给集合添加元组中的所有元素
print(s)
#四种方法 remove() discard() pop() clear()
s={10,20,30,40,50,99}
print(s)
#第一种 remove方法,一次删除一个指定元素,如果指定元素不存在报错KeyError
s.remove(99)
print(s)
#第二种 discard()方法,一次删除一个指定元素,如果指定元素不存在不出现异常
s.discard(100)
print(s)
#第三种 pop()方法,一次性只删除一个任意元素
s.pop() #括号里不能指定参数
print(s)
#第四种 clear()方法 清空集合
s.clear()
print(s)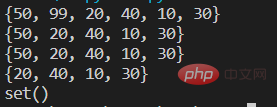
两个集合间的关系主要有相等、子集、超集、交集,我们用代码看下如何判断:
s1={10,20,30,40,50,99}
s2={10,20,30}
#判断相等可以用== != (元素相同即可)
print(s1==s2)
#判断s2是否是s1的子集可用issubset()方法
print(s2.issubset(s1))
#判断s1是否是s2的超集可用方法issuperset判断
print(s1.issuperset(s2))
#判断两个集合没有交集可用方法isdisjoint进行判断,
print(s1.isdisjoint(s2))s1={10,20,30,40,50,99}
s2={10,20,30,80}
# 1.求交集
print(s1.intersection(s2))
print(s1 & s2)
# 2.求并集
print(s1.union(s2))
print(s1 | s2)
# 3.求差集
print(s1.difference(s2))
print(s1-s2)
# 4.求对称差集
print(s1.symmetric_difference(s2))
print(s1^s2)注:数学操作之后原集合是不变的。
集合生成式就是用于生成集合的公式。
s={i+2 for i in range(5)}print(s)注意:集合、字典、列表都有生成式,但元组由于为不可变序列无生成式
推荐学习:python视频教程
以上就是一文搞定Python列表、字典、元组和集合的详细内容,更多请关注zzsucai.com其它相关文章!

