

所属分类:php教程

程序员必备接口测试调试工具:立即使用
Apipost = Postman + Swagger + Mock + Jmeter
Api设计、调试、文档、自动化测试工具
后端、前端、测试,同时在线协作,内容实时同步
推荐学习:python教程

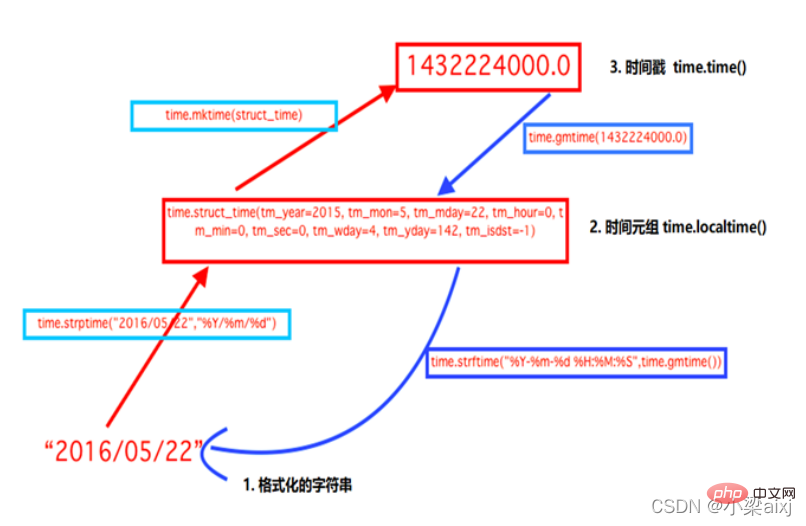
time()模块时间转换
时间戳 1970年1月1日之后的秒, 即:time.time()
格式化的字符串 2014-11-11 11:11, 即:time.strftime(’%Y-%m-%d’)
结构化时间 元组包含了:年、日、星期等… time.struct_time 即:time.localtime()
import time
print(time.time()) # 时间戳:1511166937.2178104
print(time.strftime('%Y-%m-%d')) # 格式化的字符串: 2017-11-20
print(time.localtime()) # 结构化时间(元组):
(tm_year=2017, tm_mon=11...)
print(time.gmtime()) # 将时间转换成utc格式的元组格式:
(tm_year=2017, tm_mon=11...)
#1. 将结构化时间转换成时间戳: 1511167004.0
print(time.mktime(time.localtime()))#2. 将格字符串时间转换成结构化时间 元组: (tm_year=2017, tm_mon=11...)
print(time.strptime('2014-11-11', '%Y-%m-%d'))#3. 结构化时间(元组) 转换成 字符串时间 :2017-11-20
print(time.strftime('%Y-%m-%d', time.localtime())) # 默认当前时间#4. 将结构化时间(元组) 转换成英文字符串时间 : Mon Nov 20 16:51:28 2017 print(time.asctime(time.localtime()))
#5. 将时间戳转成 英文字符串时间 : Mon Nov 20 16:51:28 2017 print(time.ctime(time.time()))
1)ctime传入的是以秒计时的时间戳转换成格式化时间
2)asctime传入的是时间元组转换成格式化时间
import time t1 = time.time() print(t1) #1483495728.4734166 print(time.ctime(t1)) #Wed Jan 4 10:08:48 2017 t2 = time.localtime() print(t2) #time.struct_time(tm_year=2017, tm_mon=1, tm_mday=4, tm_hour=10, print(time.asctime(t2)) #Wed Jan 4 10:08:48 2017
import datetime
#1、datetime.datetime获取当前时间
print(datetime.datetime.now())
#2、获取三天后的时间
print(datetime.datetime.now()+datetime.timedelta(+3))
#3、获取三天前的时间
print(datetime.datetime.now()+datetime.timedelta(-3))
#4、获取三个小时后的时间
print(datetime.datetime.now()+datetime.timedelta(hours=3))
#5、获取三分钟以前的时间
print(datetime.datetime.now()+datetime.timedelta(minutes = -3))
import datetime
print(datetime.datetime.now()) #2017-08-18
11:25:52.618873
print(datetime.datetime.now().date()) #2017-08-18
print(datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S"))
#2017-08-18 11-25-52#1、datetime对象与str转化
# datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
'2018-03-09 10:08:50'
# datetime.datetime.strptime('2016-02-22',"%Y-%m-%d")
datetime.datetime(2016, 2, 22, 0, 0)#2、datetime对象转时间元组 # datetime.datetime.now().timetuple() time.struct_time(tm_year=2018, tm_mon=3, tm_mday=9,
#3、时间戳转换成datetime对象 # datetime.datetime.fromtimestamp(1520561646.8906238) datetime.datetime(2018, 3, 9, 10, 14, 6, 890624)
# 本地时间与utc时间相互转换
import time
import datetime
def utc2local(utc_st):
''' 作用:将UTC时间装换成本地时间
:param utc_st: 传入的是utc时间(datatime对象)
:return: 返回的是本地时间 datetime 对象
'''
now_stamp = time.time()
local_time = datetime.datetime.fromtimestamp(now_stamp)
utc_time = datetime.datetime.utcfromtimestamp(now_stamp)
offset = local_time - utc_time
local_st = utc_st + offset
return local_st
def local2utc(local_st):
''' 作用:将本地时间转换成UTC时间
:param local_st: 传入的是本地时间(datatime对象)
:return: 返回的是utc时间 datetime 对象
'''
time_struct = time.mktime(local_st.timetuple())
utc_st = datetime.datetime.utcfromtimestamp(time_struct)
return utc_st
utc_time = datetime.datetime.utcfromtimestamp(time.time())
# utc_time = datetime.datetime(2018, 5, 6, 5, 57, 9, 511870) # 比北京时间
晚了8个小时
local_time = datetime.datetime.now()
# local_time = datetime.datetime(2018, 5, 6, 13, 59, 27, 120771) # 北京本地时间
utc_to_local = utc2local(utc_time)
local_to_utc = local2utc(local_time)
print utc_to_local # 2018-05-06 14:02:30.650270 已经转换成了北京本地时间
print local_to_utc # 2018-05-06 06:02:30 转换成北京当地时间# django的timezone时间与本地时间转换 from django.utils import timezone from datetime import datetime utc_time = timezone.now() local_time = datetime.now() #1、utc时间装换成本地时间 utc_to_local = timezone.localtime(timezone.now())
#2、本地时间装utc时间 local_to_utc = timezone.make_aware(datetime.now(), timezone.get_current_timezone())
import datetime d1 = datetime.datetime(2018,10,31) # 第一个日期 d2 = datetime.datetime(2019,2,2) # 第二个日期 interval = d2 - d1 # 两日期差距 print(interval.days) # 具体的天数
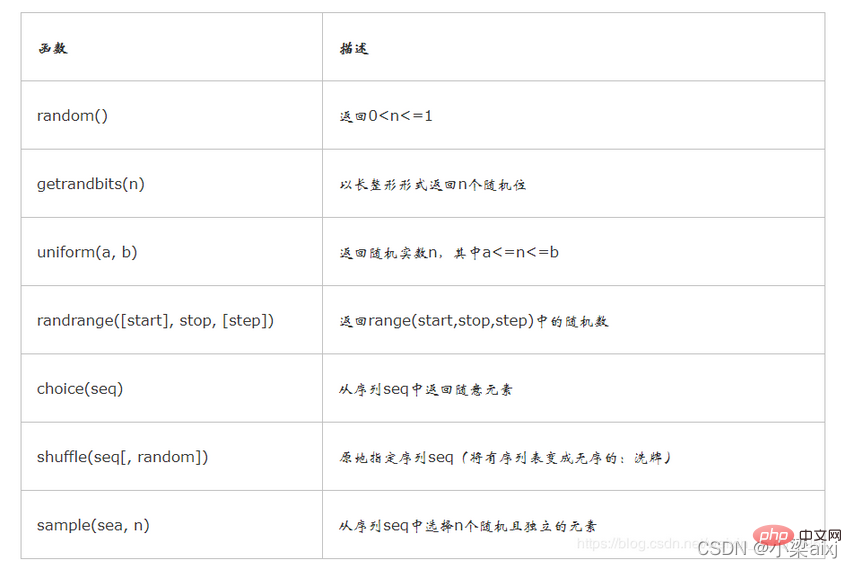
import random #⒈ 随机整数: print(random.randint(0,99)) # 随机选取0-99之间的整数 print(random.randrange(0, 101, 2)) # 随机选取0-101之间的偶数
#⒉ 随机浮点数: print(random.random()) # 0.972654134347 print(random.uniform(1, 10)) # 4.14709813772
#⒊ 随机字符:
print(random.choice('abcdefg')) # c
print(random.sample('abcdefghij',3)) # ['j', 'f', 'c']#使用for循环实现
import random
checkcode = ''
for i in range(4):
current = random.randrange(0,4)
if current == i:
tmp = chr(random.randint(65,90)) #65,90表示所有大写字母
else:
tmp = random.randint(0,9)
checkcode += str(tmp)
print(checkcode) #运行结果: 851Kimport random import string str_source = string.ascii_letters + string.digits str_list = random.sample(str_source,7) #['i', 'Q', 'U', 'u', 'A', '0', '9'] print(str_list) str_final = ''.join(str_list) #iQUuA09 print(str_final) # 运行结果: jkFU2Ed
import os #1 当前工作目录,即当前python脚本工作的目录路径 print(os.getcwd()) # C:\Users\admin\PycharmProjects\s14\Day5\test4
#2 当前脚本工作目录;相当于shell下cd
os.chdir("C:\\Users\\admin\\PycharmProjects\\s14")
os.chdir(r"C:\Users\admin\PycharmProjects\s14")
print(os.getcwd()) # C:\Users\admin\PycharmProjects\s14#3 返回当前目录: ('.')
print(os.curdir) # ('.')#4 获取当前目录的父目录字符串名:('..')
print(os.pardir) # ('..')#5 可生成多层递归目录 os.makedirs(r'C:\aaa\bbb') # 可以发现在C盘创建了文件夹/aaa/bbb
#6 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.removedirs(r'C:\aaa\bbb') # 删除所有空目录
#7 生成单级目录;相当于shell中mkdir dirname os.mkdir(r'C:\bbb') # 仅能创建单个目录
#8 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.rmdir(r'C:\aaa') # 仅删除指定的一个空目录
#9 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 print(os.listdir(r"C:\Users\admin\PycharmProjects\s14"))
#10 删除一个文件 os.remove(r'C:\bbb\test.txt') # 指定删除test.txt文件
#11 重命名文件/目录 os.rename(r'C:\bbb\test.txt',r'C:\bbb\test00.bak')
#12 获取文件/目录信息 print(os.stat(r'C:\bbb\test.txt'))
#13 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" print(os.sep) # \
#14 输出当前平台使用的行终止符,win下为"\r\n",Linux下为"\n" print(os.linesep)
#15 输出用于分割文件路径的字符串 print(os.pathsep) # ; (分号)
#16 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' print(os.name) # nt
#17 运行shell命令,直接显示
os.system("bash command")#18 获取系统环境变量
print(os.environ) # environ({'OS': 'Windows_NT', 'PUBLIC': ………….#19 返回path规范化的绝对路径 print(os.path.abspath(r'C:/bbb/test.txt')) # C:\bbb\test.txt
#20 将path分割成目录和文件名二元组返回
print(os.path.split(r'C:/bbb/ccc')) # ('C:/bbb', 'ccc')#21 返回path的目录。其实就是os.path.split(path)的第一个元素 print(os.path.dirname(r'C:/bbb/ccc')) # C:/bbb
#22 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即 os.path.split(path)的第二个元素 print(os.path.basename(r'C:/bbb/ccc/ddd')) # ddd
#23 如果path存在,返回True;如果path不存在,返回False print(os.path.exists(r'C:/bbb/ccc/')) # True
#24 如果path是绝对路径,返回True # True print(os.path.isabs(r"C:\Users\admin\PycharmProjects\s14\Day5\test4"))
#25 如果path是一个存在的文件,返回True。否则返回False print(os.path.isfile(r'C:/bbb/ccc/test2.txt')) # True
#26 如果path是一个存在的目录,则返回True。否则返回False print(os.path.isdir(r'C:/bbb/ccc')) # True
#28 返回path所指向的文件或者目录的最后存取时间 print(os.path.getatime(r'C:/bbb/ccc/test2.txt')) # 1483509254.9647143
#29 返回path所指向的文件或者目录的最后修改时间 print(os.path.getmtime(r'C:/bbb/ccc/test2.txt')) # 1483510068.746478
#30 无论linux还是windows,拼接出文件路径 put_filename = '%s%s%s'%(self.home,os. path.sep, filename) #C:\Users\admin\PycharmProjects\s14\day10select版FTP\home
import os
os.makedirs('C:/aaa/bbb/ccc/ddd',exist_ok=True) # exist_ok=True:如果存
在当前文件夹不报错
path = os.path.join('C:/aaa/bbb/ccc','ddd',)
f_path = os.path.join(path,'file.txt')
with open(f_path,'w',encoding='utf8') as f:
f.write('are you ok!!')import os,sys print(os.path.dirname( os.path.dirname( os.path.abspath(__file__) ) )) BASE_DIR = os.path.dirname( os.path.dirname( os.path.abspath(__file__) ) ) sys.path.append(BASE_DIR) # 代码解释: # 要想导入其他目录中的函数,其实就是将其他目录的绝对路径动态的添加到 pyhton的环境变量中,这样python解释器就能够在运行时找到导入的模块而不报 错: # 然后调用sys模块sys.path.append(BASE_DIR)就可以将这条路径添加到python 环境变量中
data = {'name':'aaa'}
import json
print json.dumps(data)#! /usr/bin/env python
# -*- coding: utf-8 -*-
import os,json
ret = os.popen('python data.py')
data = ret.read().strip()
ret.close()
data = json.loads(data)
print data # {'name':'aaa'}sys.argv 返回执行脚本传入的参数 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称 sys.stdout.write(‘please:’) val = sys.stdin.readline()[:-1]
import sys # C:\Users\tom\PycharmProjects\s14Review\day01> python test01.py 1 2 3 print(sys.argv) # 打印所有参数 ['test01.py', '1', '2', '3'] print(sys.argv[1:]) # 获取索引 1 往后的所有参数 ['1', '2', '3']
import tarfile
# 将文件夹Day1和Day2归档成your.rar并且在归档文件夹中Day1和Day2分别变成
bbs2.zip和ccdb.zip的压缩文件
tar = tarfile.open('your.tar','w')
tar.add(r'C:\Users\admin\PycharmProjects\s14\Day1', arcname='bbs2.zip')
tar.add(r'C:\Users\admin\PycharmProjects\s14\Day2', arcname='cmdb.zip')
tar.close()# 将刚刚的归档文件your.tar进行解压解压的内容是bbs2.zip和cmdb.zip压缩文件
而不是变成原有的文件夹
tar = tarfile.open('your.tar','r')
tar.extractall() # 可设置解压地址
tar.close()注 : shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的 作用: shutil 创建压缩包并返回文件路径(如:zip、tar),并且可以复制文件,移动文件
import shutil
#1 copyfileobj() 将文件test11.txt中的内容复制到test22.txt文件中
f1 = open("test11.txt",encoding="utf-8")
f2 = open("test22.txt",'w',encoding="utf-8")
shutil.copyfileobj(f1,f2)#2 copyfile() 直接指定文件名就可进行复制
shutil.copyfile("test11.txt",'test33.txt')#3 shutil.copymode(src, dst) 仅拷贝权限。内容、组、用户均不变
#4 shutil.copystat(src, dst) 拷贝状态的信息,包括:mode bits, atime, mtime,
flags
shutil.copystat('test11.txt','test44.txt')#5 递归的去拷贝目录中的所有目录和文件,这里的test_dir是一个文件夹,包含多
级文件夹和文件
shutil.copytree("test_dir","new_test_dir")#6 递归的去删除目录中的所有目录和文件,这里的test_dir是一个文件夹,包含多
级文件夹和文件
shutil.rmtree("test_dir")#7 shutil.move(src, dst) 递归的去移动文件
shutil.move('os_test.py',r'C:\\')#8 shutil.make_archive(base_name, format,...) 创建压缩包并返回文件路径,例 如:zip、tar ' ' '
’ ’ ’
#将C:\Users\admin\PycharmProjects\s14\Day4 的文件夹压缩成 testaa.zip
shutil.make_archive("testaa","zip",r"C:\Users\admin\PycharmProjects
\s14\Day4")import zipfile
#将文件main.py和test11.py压缩成day5.zip的压缩文件
z = zipfile.ZipFile('day5.zip', 'w')
z.write('main.py')
z.write("test11.txt")
z.close()#将刚刚压缩的day5.zip文件进行解压成原文件
z = zipfile.ZipFile('day5.zip', 'r')
z.extractall()
z.close()作用:shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式
import shelve
import datetime
#1 首先使用shelve将.py中定义的字典列表等读取到指定文件shelve_test中,其
实我们可不必关心在文件中是怎样存储的
d = shelve.open('shelve_test') #打开一个文件
info = {"age":22,"job":"it"}
name = ["alex","rain","test"]
d["name"] = name #持久化列表
d["info"] = info
d["date"] = datetime.datetime.now()
d.close()#2 在这里我们可以将刚刚读取到 shelve_test文件中的内容从新获取出来
d = shelve.open('shelve_test') # 打开一个文件
print(d.get("name")) # ['alex', 'rain', 'test']
print(d.get("info")) # {'job': 'it', 'age': 22}
print(d.get("date")) # 2017-11-20 17:54:21.223410序列化 (json.dumps) :是将内存中的对象存储到硬盘,变成字符串
反序列化(json.loads) : 将刚刚保存在硬盘中的内存对象从新加载到内存中
json.dumps( data,ensure_ascii=False, indent=4)
json序列化
#json序列化代码
import json
info = {
'name':"tom",
"age" :"100"
}
f = open("test.txt",'w')
# print(json.dumps(info))
f.write(json.dumps(info))
f.close()json反序列化
#json反序列化代码
import json
f = open("test.txt","r")
data = json.loads(f.read())
f.close()
print(data["age"])python的pickle模块实现了python的所有数据序列和反序列化。基本上功能使用和JSON模块没有太大区别,方法也同样是dumps/dump和loads/load
与JSON不同的是pickle不是用于多种语言间的数据传输,它仅作为python对象的持久化或者python程序间进行互相传输对象的方法,因此它支持了python所有的数据类型。
pickle序列化
#pickle序列化代码
import pickle
info = {
'name':"tom",
"age" :"100"
}
f = open("test.txt",'wb')
f.write(pickle.dumps(info))
f.close()pickle反序列化
#pickle反序列化代码
import pickle
f = open("test.txt","rb")
data = pickle.loads(f.read())
f.close()
print(data["age"])import json,datetime
class JsonCustomEncoder(json.JSONEncoder):
def default(self, field):
if isinstance(field, datetime.datetime):
return field.strftime('%Y-%m-%d %H:%M:%S')
elif isinstance(field, datetime.date):
return field.strftime('%Y-%m-%d')
else:
return json.JSONEncoder.default(self, field)
t = datetime.datetime.now()
print(type(t),t)
f = open('ttt','w') #指定将内容写入到ttt文件中
f.write(json.dumps(t,cls=JsonCustomEncoder)) #使用时候只要在json.dumps
增加个cls参数即可JSON只能处理基本数据类型。pickle能处理所有Python的数据类型。
JSON用于各种语言之间的字符转换。pickle用于Python程序对象的持久化或者Python程序间对象网络传输,但不同版本的Python序列化可能还有差异
hashlib 模块
1、用于加密相关的操作,代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlib
#1 ######## md5 ########
# 目的:实现对b"HelloIt's me" 这句话进行md5加密
m = hashlib.md5() # 1)生成一个md5加密对象
m.update(b"Hello") # 2)使用m对 b"Hello" 加密
m.update(b"It's me") # 3) 使用m对 b"It's me"加密
print(m.hexdigest()) # 4) 最终加密结果就是对b"HelloIt's me"加密的md5
值:5ddeb47b2f925ad0bf249c52e342728a#2 ######## sha1 ######## hash = hashlib.sha1() hash.update(b'admin') print(hash.hexdigest())
#3 ######## sha256 ######## hash = hashlib.sha256() hash.update(b'admin') print(hash.hexdigest())
#4 ######## sha384 ######## hash = hashlib.sha384() hash.update(b'admin') print(hash.hexdigest())
#5 ######## sha512 ######## hash = hashlib.sha512() hash.update(b'admin') print(hash.hexdigest())
2、以上加密算法虽然依然非常厉害,但时候存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来做加密。
hmac添加自定义key加密
######### hmac ######## import hmac h = hmac.new(b"123456","真实要传的内容".encode(encoding="utf-8")) print(h.digest()) print(h.hexdigest()) # 注:hmac是一种双重加密方法,前面是加密的内容,后面才是真实要传的数据 信息
#1、返回执行状态:0 执行成功
retcode = subprocess.call(['ping', 'www.baidu.com', '-c5'])
#2、返回执行状态:0 执行成功,否则抛异常
subprocess.check_call(["ls", "-l"])
#3、执行结果为元组:第1个元素是执行状态,第2个是命令结果
>>> ret = subprocess.getstatusoutput('pwd')
>>> ret
(0, '/test01')#4、返回结果为 字符串 类型
>>> ret = subprocess.getoutput('ls -a')
>>> ret
'.\n..\ntest.py'#5、返回结果为’bytes’类型
>>> res=subprocess.check_output(['ls','-l'])
>>> res.decode('utf8')
'总用量 4\n-rwxrwxrwx. 1 root root 334 11月 21 09:02 test.py\n'将dos格式文件转换成unix格式
subprocess.check_output(['chmod', '+x', filepath]) subprocess.check_output(['dos2unix', filepath])
实际上,上面的几个函数都是基于Popen()的封装(wrapper),这些封装的目的在于让我们容易使用子进程
当我们想要更个性化我们的需求的时候,就要转向Popen类,该类生成的对象用来代表子进程
与上面的封装不同,Popen对象创建后,主程序不会自动等待子进程完成。我们必须调用对象的wait()方法,父进程才会等待 (也就是阻塞block)
从运行结果中看到,父进程在开启子进程之后并没有等待child的完成,而是直接运行print。
chil
#1、先打印'parent process'不等待child的完成
import subprocess
child = subprocess.Popen(['ping','-c','4','www.baidu.com'])
print('parent process')#2、后打印'parent process'等待child的完成
import subprocess
child = subprocess.Popen('ping -c4 www.baidu.com',shell=True)
child.wait()
print('parent process')child.poll() # 检查子进程状态
child.kill() # 终止子进程
child.send_signal() # 向子进程发送信号
child.terminate() # 终止子进程subprocess.PIPE实际上为文本流提供一个缓存区。child1的stdout将文本输出到缓存区,随后child2的stdin从该PIPE中将文本读取走
child2的输出文本也被存放在PIPE中,直到communicate()方法从PIPE中读取出PIPE中的文本。
注意:communicate()是Popen对象的一个方法,该方法会阻塞父进程,直到子进程完成
分步执行cat /etc/passwd | grep root命
import subprocess #下面执行命令等价于: cat /etc/passwd | grep root child1 = subprocess.Popen(["cat","/etc/passwd"], stdout=subprocess.PIPE) child2 = subprocess.Popen(["grep","root"],stdin=child1.stdout, stdout=subprocess.PIPE) out = child2.communicate() #返回执行结果是元组 print(out) #执行结果: (b'root:x:0:0:root:/root:/bin/bash\noperator:x:11:0:operator:/root: /sbin/nologin\n', None)
获取ping命令执行结果
import subprocess
list_tmp = []
def main():
p = subprocess.Popen(['ping', 'www.baidu.com', '-c5'], stdin = subprocess.PIPE, stdout = subprocess.PIPE)
while subprocess.Popen.poll(p) == None:
r = p.stdout.readline().strip().decode('utf-8')
if r:
# print(r)
v = p.stdout.read().strip().decode('utf-8')
list_tmp.append(v)
main()
print(list_tmp[0])作用:点(.)可以匹配除换行符以外的任意一个字符串
例如:‘.ython’ 可以匹配‘aython’ ‘bython’ 等等,但只能匹配一个字符串
作用:可以将其他有特殊意义的字符串以原本意思表示
例如:‘python.org’ 因为字符串中有一个特殊意义的字符串(.)所以如果想将其按照普通意义就必须使用这样表示: ‘python.org’ 这样就只会匹配‘python.org’ 了
注:如果想对反斜线(\)自身转义可以使用双反斜线(\)这样就表示 ’\’
作用:使用中括号来括住字符串来创建字符集,字符集可匹配他包括的任意字串
①‘[pj]ython’ 只能够匹配‘python’ ‘jython’
② ‘[a-z]’ 能够(按字母顺序)匹配a-z任意一个字符
③‘[a-zA-Z0-9]’ 能匹配任意一个大小写字母和数字
④‘[^abc]’ 可以匹配任意除a,b和c 之外的字符串
作用:一次性匹配多个字符串
例如:’python|perl’ 可以匹配字符串‘python’ 和 ‘perl’
作用:在子模式后面加上问号,他就变成可选项,出现或者不出现在匹配字符串中都是合法的
例如:r’(aa)?(bb)?ccddee’ 只能匹配下面几种情况
‘aabbccddee’
‘aaccddee’
‘bbccddee’
‘ccddee’
① ‘w+’ 匹配以w开通的字符串
② ‘^http’ 匹配以’http’ 开头的字符串
③‘ $com’ 匹配以‘com’结尾的字符串
\d 匹配任何十进制数;它相当于类 [0-9]。
\D 匹配任何非数字字符;它相当于类 [^0-9]。
\s 匹配任何空白字符;它相当于类 [ fv]。
\S 匹配任何非空白字符;它相当于类 [^ fv]。
\w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。
\W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_]。
\w* 匹配所有字母字符
\w+ 至少匹配一个字符
匹配字符结尾,或e.search("foo",“bfoo\nsdfsf”,flags=re.MULTILINE).group()也可

1)把一个正则表达式pattern编译成正则对象,以便可以用正则对象的match和search方法
2)用了re.compile以后,正则对象会得到保留,这样在需要多次运用这个正则对象的时候,效率会有较大的提升
re.compile使用
import re
mobile_re = re.compile(r'^(13[0-9]|15[012356789]|17[678]|18[0-9]|14[57])
[0-9]{8}$')
ret = re.match(mobile_re,'18538762511')
print(ret) # <_sre.SRE_Match object; span=(0, 11),
match='18538652511'>1)match :只从字符串的开始与正则表达式匹配,匹配成功返回matchobject,否则返回none;
2)search :将字符串的所有字串尝试与正则表达式匹配,如果所有的字串都没有匹配成功,返回none,否则返回matchobject;
match与search使用比较
import re
a =re.match('www.bai', 'www.baidu.com')
b = re.match('bai', 'www.baidu.com')
print(a.group()) # www.bai
print(b) # None
# 无论有多少个匹配的只会匹配一个
c = re.search('bai', 'www.baidubaidu.com')
print(c) # <_sre.SRE_Match object; span=(4, 7),
match='bai'>
print(c.group()) # bai作用:将字符串以指定分割方式,格式化成列表
import re
text = 'aa 1bb###2cc3ddd'
print(re.split('\W+', text)) # ['aa', '1bb', '2cc3ddd']
print(re.split('\W', text)) # ['aa', '1bb', '', '', '2cc3ddd']
print(re.split('\d', text)) # ['aa ', 'bb###', 'cc', 'ddd']
print(re.split('#', text)) # ['aa 1bb', '', '', '2cc3ddd']
print(re.split('#+', text)) # ['aa 1bb', '2cc3ddd']作用:正则表达式 re.findall 方法能够以列表的形式返回能匹配的子串
import re
p = re.compile(r'\d+')
print(p.findall('one1two2three3four4')) # ['1', '2', '3', '4']
print(re.findall('o','one1two2three3four4')) # ['o', 'o', 'o']
print(re.findall('\w+', 'he.llo, wo#rld!')) # ['he', 'llo', 'wo', 'rld']1)替换,将string里匹配pattern的部分,用repl替换掉,最多替换count次然后返回替换后的字符串
2)如果string里没有可以匹配pattern的串,将被原封不动地返回
3)repl可以是一个字符串,也可以是一个函数
4) 如果repl是个字符串,则其中的反斜杆会被处理过,比如 \n 会被转成换行符,反斜杆加数字会被替换成相应的组,比如 \6 表示pattern匹配到的第6个组的内容
import re
test="Hi, nice to meet you where are you from?"
print(re.sub(r'\s','-',test)) # Hi,-nice-to-meet-you-where-are-you-from?
print(re.sub(r'\s','-',test,5)) # Hi,-nice-to-meet-you-where are you from?
print(re.sub('o','**',test)) # Hi, nice t** meet y**u where are y**u fr**m?1) re.escape(pattern) 可以对字符串中所有可能被解释为正则运算符的字符进行转义的应用函数。
2) 如果字符串很长且包含很多特殊技字符,而你又不想输入一大堆反斜杠,或者字符串来自于用户(比如通过raw_input函数获取输入的内容),
且要用作正则表达式的一部分的时候,可以用这个函数
import re
print(re.escape('www.python.org'))re模块中的匹配对象和组 group()
1)group方法返回模式中与给定组匹配的字符串,如果没有给定匹配组号,默认为组0
2)m.group() == m.group(0) == 所有匹配的字符
group(0)与group(1)区别比较
import re
a = "123abc321efg456"
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0)) # 123abc321
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).groups()) # ('123', 'abc', '321')
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1)) # 123
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2)) # abc
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3)) # 321import re
m = re.match('(..).*(..)(..)','123456789')
print(m.group(0)) # 123456789
print(m.group(1)) # 12
print(m.group(2)) # 67
print(m.group(3)) # 89group()匹配之返回匹配索引
import re
m = re.match('www\.(.*)\..*','www.baidu.com')
print(m.group(1)) # baidu
print(m.start(1)) # 4
print(m.end(1)) # 9
print(m.span(1)) # (4, 9)group()匹配ip,状态以元组返回
import re
test = 'dsfdf 22 g2323 GigabitEthernet0/3 10.1.8.1 YES NVRAM up
eee'
# print(re.match('(\w.*\d)\s+(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})\s+YES\s+NVRAM
\s+(\w+)\s+(\w+)\s*', test).groups())
ret = re.search( r'(\w*\/\d+).*\s(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}).*(\s+up\s+)',test
).groups()
print(ret) # 运行结果: ('GigabitEthernet0/3', '10.1.8.1', ' up ')
#1. (\w*\d+\/\d+) 匹配结果为:GigabitEthernet0/3
#1.1 \w*: 匹配所有字母数字
#1.2 /\d+:匹配所有斜杠开头后根数字 (比如:/3 )
#2. (\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}) 匹配结果为:10.1.8.1
#3. \s+up\s+ 匹配结果为: up 这个单词,前后都为空格re模块其他知识点
re匹配忽略大小写,匹配换行
import re
#匹配时忽略大小写
print(re.search("[a-z]+","abcdA").group()) #abcd
print(re.search("[a-z]+","abcdA",flags=re.I).group()) #abcdA
#连同换行符一起匹配:
#'.'默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包
括换行
print(re.search(r".+","\naaa\nbbb\nccc").group()) #aaa
print(re.search(r".+","\naaa\nbbb\nccc",flags=re.S))
#<_sre.SRE_Match object; span=(0, 12), match='\naaa\nbbb\nccc'>
print(re.search(r".+","\naaa\nbbb\nccc",flags=re.S).group())
aaa
bbb
ccc推荐学习:python学习教程
以上就是归纳总结Python常用模块大全的详细内容,更多请关注zzsucai.com其它相关文章!

