

所属分类:php教程

程序员必备接口测试调试工具:立即使用
Apipost = Postman + Swagger + Mock + Jmeter
Api设计、调试、文档、自动化测试工具
后端、前端、测试,同时在线协作,内容实时同步
推荐学习:python教程
表格是数据的一般表示形式,但对于机器来说是不可理解的,也就是无法辨识的数据,所以我们需要对表格的形式进行调整。
常用的机器学习表示形式为数据矩阵。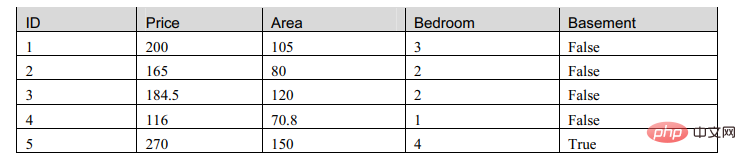
我们观察这个表格,发现,矩阵中的属性有两种,一种是数值型,一种是布尔型。那么我们现在就建立模型描述这个表格:
# 数据的矩阵化import numpy as np
data = np.mat([[1,200,105,3,False],[2,165,80,2,False],[3,184.5,120,2,False],
[4,116,70.8,1,False],[5,270,150,4,True]])row = 0for line in data:
row += 1print( row )print(data.size)print(data)这里第一行代码的意思就是引入NumPy将其重命名为np。第二行我们使用NumPy中的mat()方法建立一个数据矩阵,row是引入的计算行数的变量。
这里的size意思就是5*5的一个表格,直接打印data就可以看到数据了: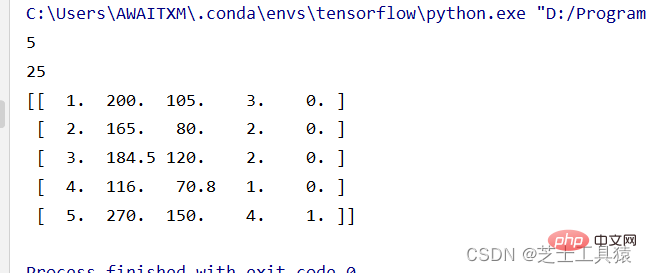
我们还是看最上面的表格,第二列是房价的差异,我们想直观的看出差别是不容易的(因为只有数字),所以我们希望能够把它画出来(研究数值差异和异常的方法就是绘制数据的分布程度):
import numpy as npimport scipy.stats as statsimport pylab
data = np.mat([[1,200,105,3,False],[2,165,80,2,False],[3,184.5,120,2,False],
[4,116,70.8,1,False],[5,270,150,4,True]])coll = []for row in data:
coll.append(row[0,1])stats.probplot(coll,plot=pylab)pylab.show()这个代码的结果就是生成一个图: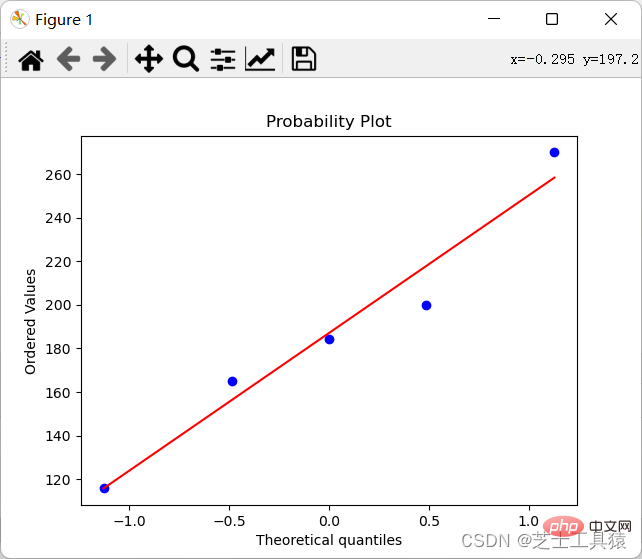
这样我们就能清晰的看出来差异了。
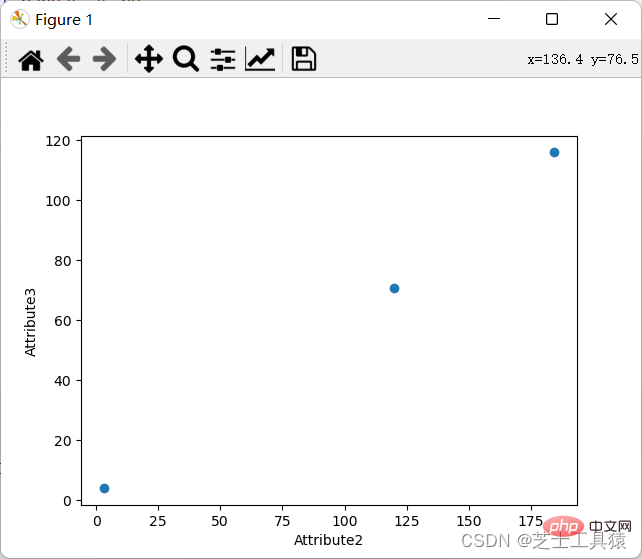
一个坐标图的要求,就是通过不同的行和列表现出数据的具体值。
当然,坐标图我们一样可以展示:
相似度的计算方法有很多,我们选用最常用的两种,即欧几里得相似度和余弦相似度计算。
欧几里得距离,用来表示三维空间中两个点的真实距离。公式我们其实都知道,只是名字听的少: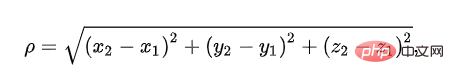
那么我们来看一看它的实际应用:
这个表格是3个用户对物品的打分: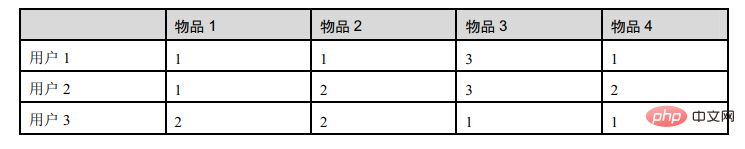
d12表示用户1和用户2的相似度,那么就有: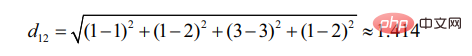
同理,d13: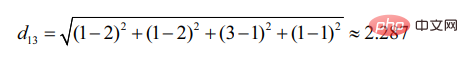
可见,用户2更加相似于用户1(距离越小,相似度越大)。
余弦角度的计算出发点是夹角的不同。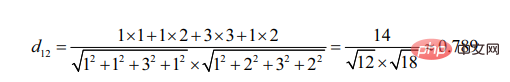
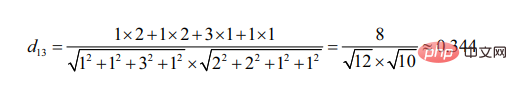
可见相对于用户3,用户2与用户1更为相似(两个目标越相似,其线段形成的夹角越小)
四分位数,是统计学中分位数的一种,也就是把数据由小到大排列,之后分成四等份,处于三个分割点位置的数据,就是四分位数。
第一四分位数(Q1),也称下四分位数;
第二四分位数(Q1),也称中位数;
第三四分位数(Q1),也称下四分位数;
第三四分位数与第一四分位数的差距又称为四分差距(IQR)。
若n为项数,则:
Q1的位置 = (n+1)*0.25
Q2的位置 = (n+1)*0.50
Q3的位置 = (n+1)*0.75
四分位示例:
关于这个rain.csv,有需要的可以私我要文件,我使用的是亳州市2010-2019年的月份降水情况。
from pylab import *import pandas as pdimport matplotlib.pyplot as plot
filepath = ("C:\\Users\\AWAITXM\\Desktop\\rain.csv")# "C:\Users\AWAITXM\Desktop\rain.csv"dataFile = pd.read_csv(filepath)summary = dataFile.describe()print(summary)array = dataFile.iloc[:,:].values
boxplot(array)plot.xlabel("year")plot.ylabel("rain")show()以下是plot运行结果: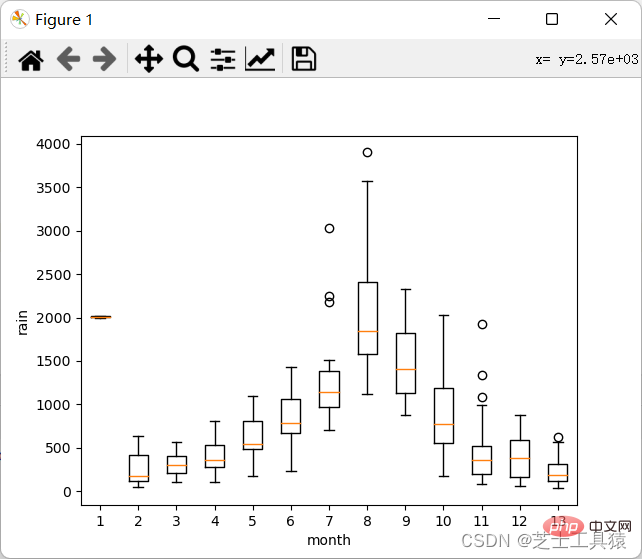
这个是pandas的运行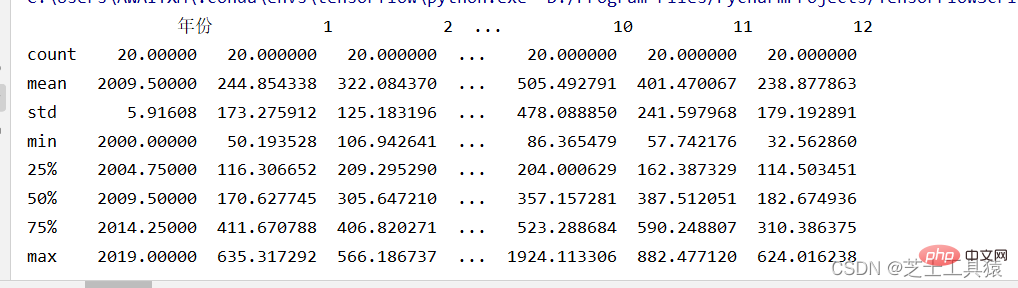
这里就可以很清晰的看出来数据的波动范围。
可以看出,不同月份的降水量有很大差距,8月最多,1-4月和10-12月最少。
那么每月的降水增减程度如何比较?
from pylab import *import pandas as pdimport matplotlib.pyplot as plot
filepath = ("C:\\Users\\AWAITXM\\Desktop\\rain.csv")# "C:\Users\AWAITXM\Desktop\rain.csv"dataFile = pd.read_csv(filepath)summary = dataFile.describe()minRings = -1maxRings = 99nrows = 11for i in range(nrows):
dataRow = dataFile.iloc[i,1:13]
labelColor = ( (dataFile.iloc[i,12] - minRings ) / (maxRings - minRings) )
dataRow.plot(color = plot.cm.RdYlBu(labelColor),alpha = 0.5)plot.xlabel("Attribute")plot.ylabel(("Score"))show()结果如图: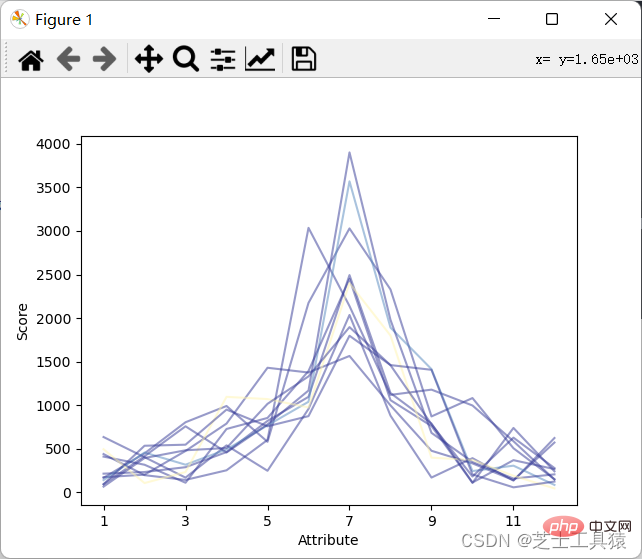
可以看出来降水月份并不规律的上涨或下跌。
那么每月降水是否相关?
from pylab import *import pandas as pdimport matplotlib.pyplot as plot
filepath = ("C:\\Users\\AWAITXM\\Desktop\\rain.csv")# "C:\Users\AWAITXM\Desktop\rain.csv"dataFile = pd.read_csv(filepath)summary = dataFile.describe()corMat = pd.DataFrame(dataFile.iloc[1:20,1:20].corr())plot.pcolor(corMat)plot.show()结果如图: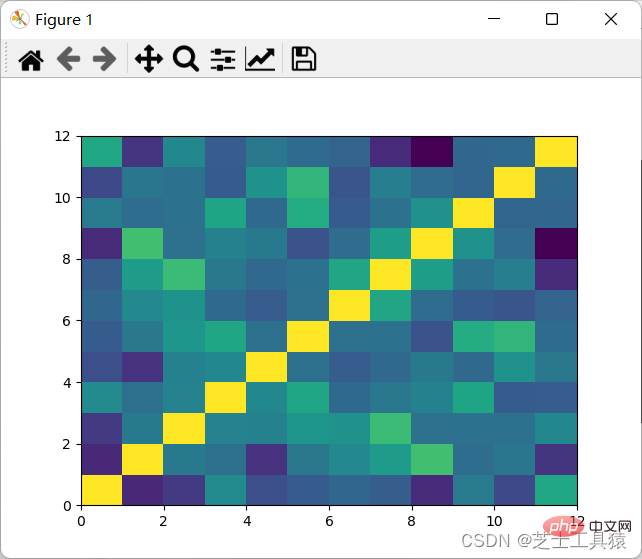
可以看出,颜色分布十分均匀,表示没有多大的相关性,因此可以认为每月的降水是独立行为。
今天就记录到这里了,我们下次再见!希望本文章对你也有所帮助。
推荐学习:python学习教程
以上就是深入了解Python数据处理及可视化的详细内容,更多请关注zzsucai.com其它相关文章!

